데이터 시각화하기
맷플롯립 그래프를 담는 객체인 피겨, rcParams, 서브플롯을 통해 그래프를 다양하게 표현
데이터 다운로드
import gdown
gdown.download('https://bit.ly/3pK7iuu', 'ns_book7.csv', quiet=False)
import pandas as pd
ns_book7 = pd.read_csv('ns_book7.csv', low_memory=False)
ns_book7.head()Figure 객체
모든 그래프 구성 요소를 담고 있는 최상위 객체
그래프 크기 변경 : figsize 매개변수
그래프의 크기는 튜플로 지정이 가능하며 기본 크기는 (6, 4)이며 맷플롯립의 버전과 플랫폼에 따라 달라질 수 있음
// 그래프의 크기를 (9,6)로 변경
plt.figure(figsize=(9,6))
plt.scatter(ns_book7['도서권수'], ns_book7['대출건수'], alpha=0.1)
plt.show()
// 기본 그래프 크기 출력
print(plt.rcParams['figure.figsize']) |  |
|---|
픽셀에 따른 그래프 크기 변경
픽셀/dpi를 이용하여 진행
// 900x600 픽셀 크기의 그래프 생성
plt.figure(figsize=(900/72, 600/72))
plt.scatter(ns_book7['도서권수'], ns_book7['대출건수'], alpha=0.1)
plt.show()참고 : 여기서 맷플롯립의 기본 dpi를 72로 입력하는것 보다는 맷플롯립의 버전과 플랫폼에따라 달라지기 때문에 900/plt.rcParams['figure.dpi'] 로 진행하는것이 더 나은듯 함
그래프 주변 공백 삭제
코랩 노트북의 타이트 레이아웃을 사용하지 않기 위한 옵션변경
파이썬 셸에서는 그래프를 그리면 정상적으로 출력됨
%config InlineBackend.print_figure_kwargs = {'bbox_inches': None}
plt.figure(figsize=(900/72, 600/72))
plt.scatter(ns_book7['도서권수'], ns_book7['대출건수'], alpha=0.1)
plt.show()
// 다시 타이트 레이아웃 사용
%config InlineBackend.print_figure_kwargs = {'bbox_inches': 'tight'}그래프 크기 변경 : dpi 매개변수
인치당 픽셀 수가 변경되기 때문에 그래프의 크기가 변경되고 그래프 안의 모든 구성요소도 함께 변경
plt.figure(dpi=144)
plt.scatter(ns_book7['도서권수'], ns_book7['대출건수'], alpha=0.1)
plt.show()
rcParms 객체
맷플롯립 그래프의 기본값을 관리하는 객체로 객체에 담긴 값을 출력하는 것뿐만 아니라 새로운 값으로 변경이 가능함
DPI 기본값 바꾸기
plt.rcParams['figure.dpi'] = 100산점도 마커 모양 변경
// o모양
plt.rcParams['scatter.marker']
// *모양
plt.rcParams['scatter.marker'] = '*'
// 그래프 그릴때 마커모양 변경
plt.scatter(ns_book7['도서권수'], ns_book7['대출건수'], alpha=0.1, marker='+')
plt.show()레퍼런스
여러 개의 서브플롯 출력
하나의 피겨 객체 안에 여러개의 서브플롯을 담을 수 있음, 서브플롯이란 맷플롯립의 Axes 클래스의 객체를 말하며 하나의 서브플롯은 두 개 이상의 축을 포함 각 축에는 눈금 또는 틱이 표시되며 축 이름을 나타내는 레이블이 존재
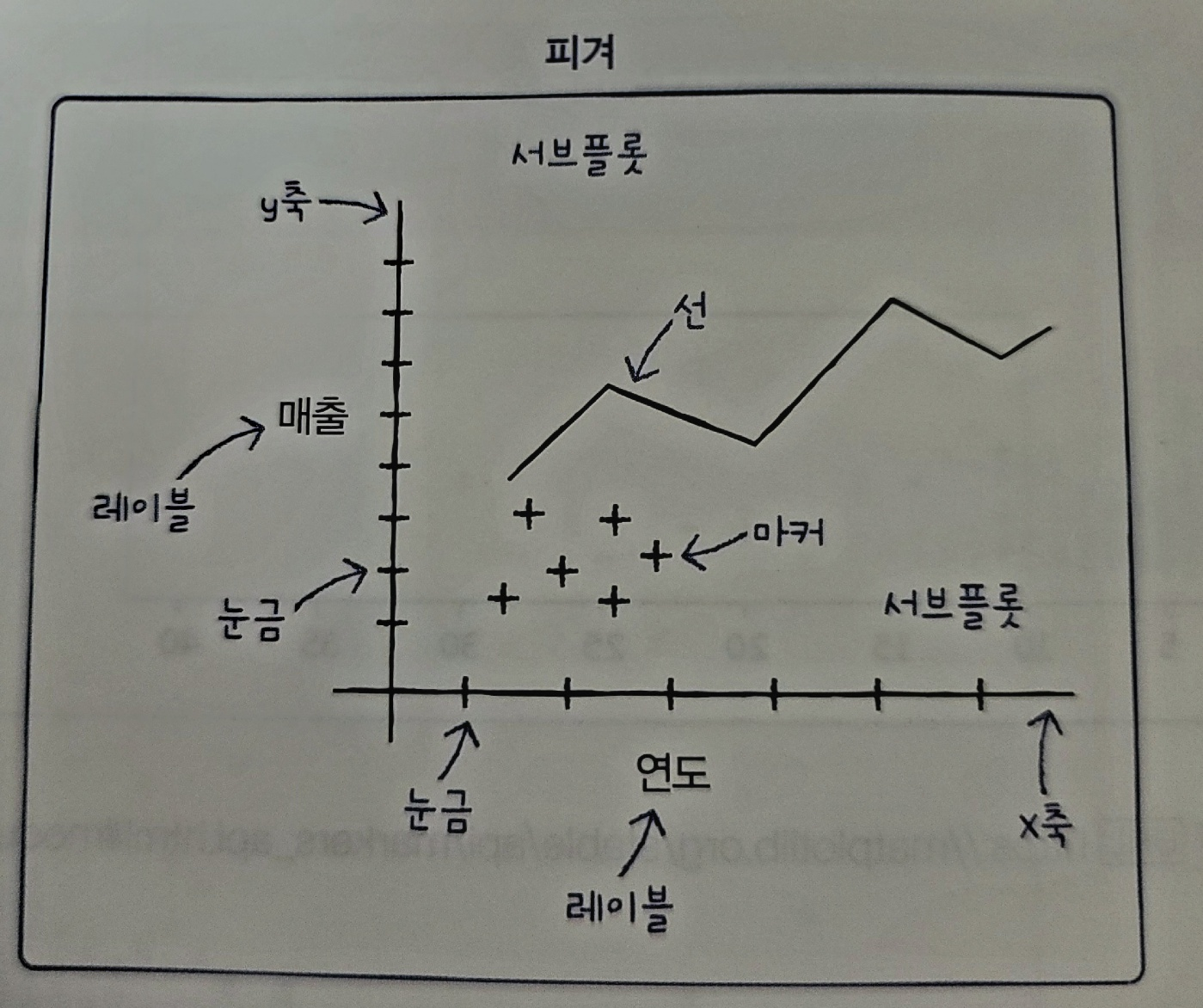
서브플롯 그리기: subplots() 함수
// 피겨 크기 지정
fig, axs = plt.subplots(2, figsize=(6, 8))
axs[0].scatter(ns_book7['도서권수'], ns_book7['대출건수'], alpha=0.1)
// 제목입력
axs[0].set_title('scatter plot')
axs[1].hist(ns_book7['대출건수'], bins=100)
axs[1].set_title('histogram')
axs[1].set_yscale('log')
fig.show()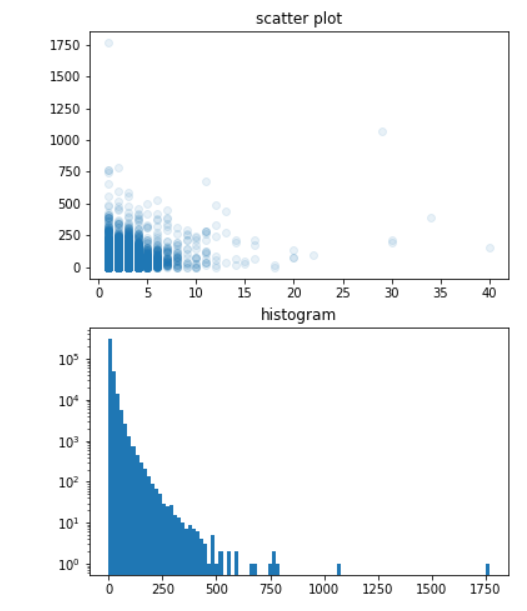
서브플롯을 가로로 나란히 출력하기
두 그래프를 가로로 나란히 정렬하려면 행과 열을 지정
fig, axs = plt.subplots(1,2, figsize=(10, 4))
axs[0].scatter(ns_book7['도서권수'], ns_book7['대출건수'], alpha=0.1)
axs[0].set_title('scatter plot')
axs[0].set_xlabel('number of books')
axs[0].set_ylabel('borrow count')
axs[1].hist(ns_book7['대출건수'], bins=100)
axs[1].set_title('histogram')
axs[1].set_yscale('log')
axs[1].set_xlabel('brrow count')
axs[1].set_ylabel('frequency')
fig.show()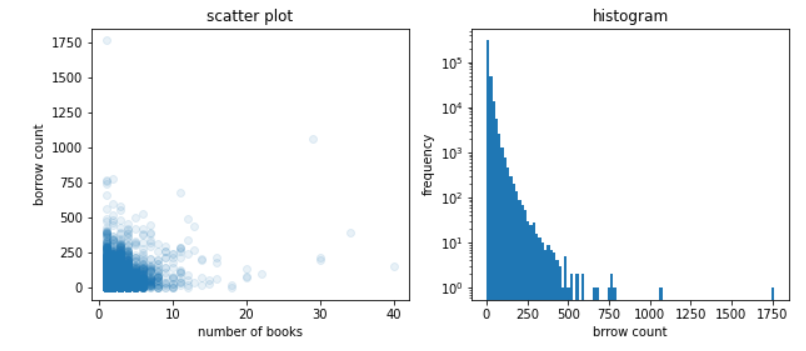
함수
| 함수 | 기능 |
|---|---|
| matplotlib.pyplot.figure() | 피겨 객체만들어 반환 |
| matplotlib.pyplot.subplots() | 피겨와 서브플롯을 생성하여 반환 |
| Axes.set_xscale() | 서브플롯의 x축 스케일 지정 |
| Axes.set_yscale() | 서브플롯의 y축 스케일 지정 |
| Axes.set_title() | 서브플롯의 제목 설정 |
| Axes.set_xlabel() | 서브플롯의 x축 이름 지정 |
| Axes.set_ylabel() | 서브플롯의 y축 이름 지정 |
선 그래프와 막대 그래프 그리기
선 그래프는 데이터 포인트 사이를 선으로 이은 그래프, 막대 그래프는 데이터 포인트의 크기를 막대 노이로 나타낸 그래프
데이터 가져오기
import gdown
gdown.download('https://bit.ly/3pK7iuu', 'ns_book7.csv', quiet=False)
import pandas as pd
ns_book7 = pd.read_csv('ns_book7.csv', low_memory=False)
ns_book7.head()연도별 도서 개수 구하기
// 기본적으로 내림차순 정렬
count_by_year = ns_book7['발행년도'].value_counts()
count_by_year
// 오름차순 정렬(인덱스 순으로 정렬)
count_by_year = ns_book7['발행년도'].value_counts().sort_index()
// 2030년보다 작거나 같은 데이터만 추출
count_by_year = count_by_year[count_by_year.index <= 2030]주제별 도서 개수 구하기
NaN 값을 -1로 변경
import numpy as np
def kdc_1st_char(no):
if no is np.nan:
return '-1'
else:
return no[0]
couny_by_subject = ns_book7['주제분류번호'].apply(kdc_1st_char).value_counts()
couny_by_subject선 그래프 그리기 : plot() 함수
import matplotlib.pyplot as plt
// 해상도 변경
plt.rcParams['figure.dpi'] = 100
plt.plot(count_by_year.index, count_by_year.values)
plt.title('Books by year')
plt.xlabel('year')
plt.ylabel('number of books')
plt.show()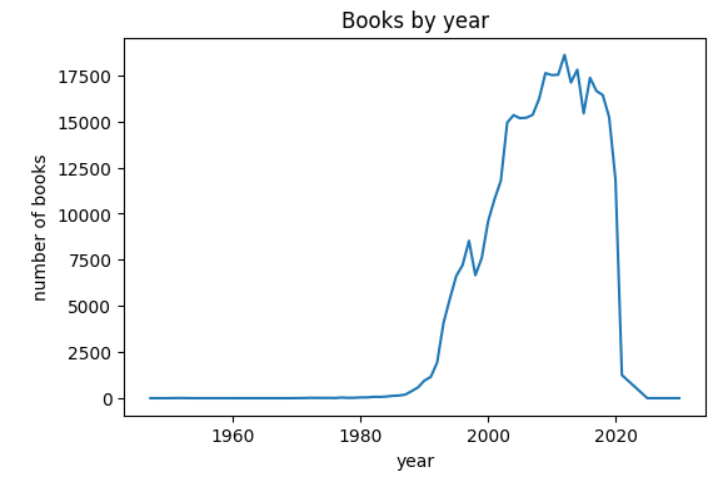
선 모양과 색상 바꾸기
plot()함수의 linestyle 매개변수를 이용하며 color 매개변수에 #ff0000 혹은 red처럼 색상을 부여할 수 있음, marker 매개변수도 제공
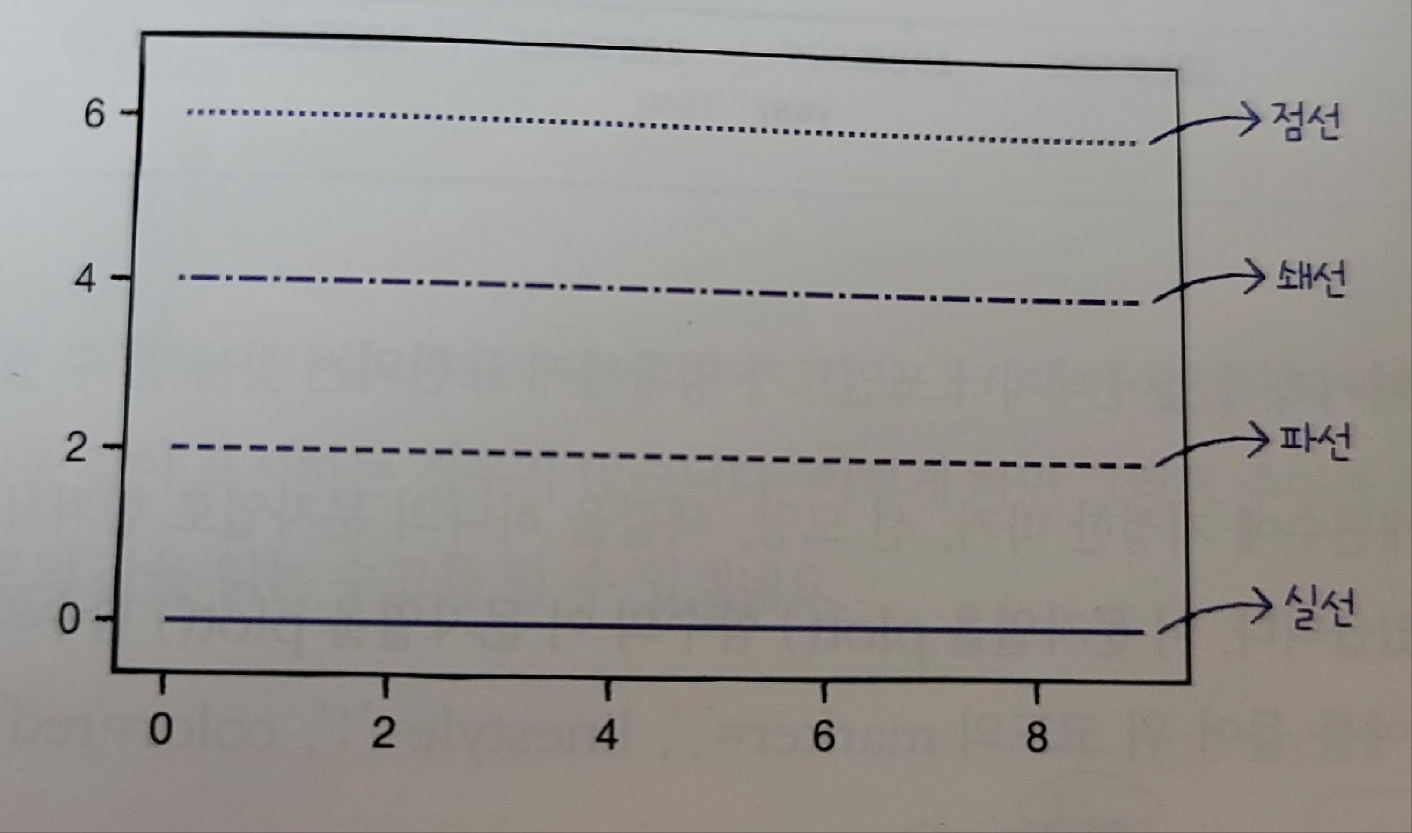
| 항목 | 값 |
|---|---|
| 실선 | ‘-’ |
| 점선 | ‘:’ |
| 쇄선 | ‘-.’ |
| 파선 | ‘--’ |
plt.plot(count_by_year, marker='.', linestyle=':', color='red')
plt.title('Books by year')
plt.xlabel('year')
plt.ylabel('number of books')
plt.show()
// 다음처럼 쓸수도 있음
plt.plt(count_by_year, '.:r')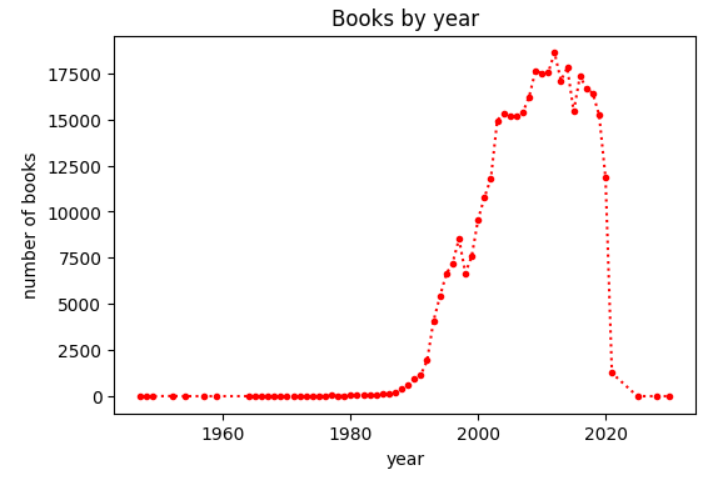
선 그래프 눈금 개수 조절 : xticks(), yticks() 함수
plt.plot(count_by_year, '*-g')
plt.title('Books by year')
plt.xlabel('year')
plt.ylabel('number of books')
plt.xticks(range(1947, 2030, 10))
for idx, val in count_by_year[::5].items():
// val: 그래프에 나타낼 물자열, (idx, val) 텍스트가 나타날 x,y 좌표
plt.annotate(val, (idx, val))
plt.show()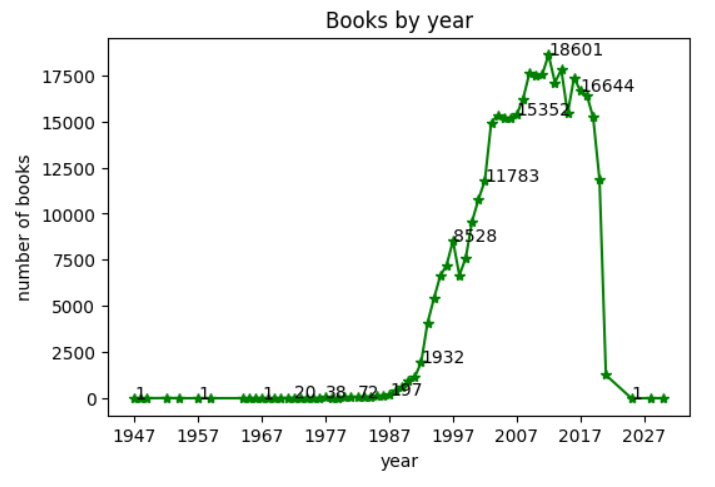
xytext 위치 이동
plt.plot(count_by_year, '*-g')
plt.title('Books by year')
plt.xlabel('year')
plt.ylabel('number of books')
plt.xticks(range(1947, 2030, 10))
for idx, val in count_by_year[::5].items():
// xytext x축은 1만큼 y축은 10만큼 이동해서 텍스트 표시
plt.annotate(val, (idx, val), xytext=(idx+1, val+10)
plt.show()y축의 스케일을 고려한 위치 이동
plt.plot(count_by_year, '*-g')
plt.title('Books by year')
plt.xlabel('year')
plt.ylabel('number of books')
plt.xticks(range(1947, 2030, 10))
for idx, val in count_by_year[::5].items():
// textcoords를 offset points(포인트) 혹은 offset pixels(픽셀 단위)로 변경
plt.annotate(val, (idx, val), xytext=(2, 2), textcoords='offset points')
plt.show()막대 그래프 그리기 : bar() 함수
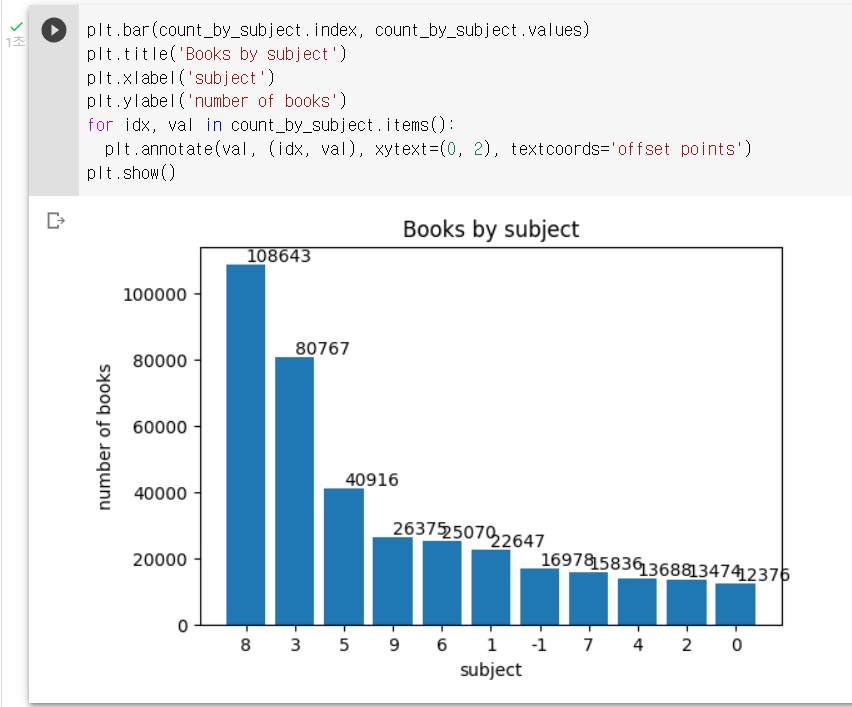
plt.bar(count_by_subject.index, count_by_subject.values)
plt.title('Books by subject')
plt.xlabel('subject')
plt.ylabel('number of books')
for idx, val in count_by_subject.items():
plt.annotate(val, (idx, val), xytext=(0, 2), textcoords='offset points')
plt.show()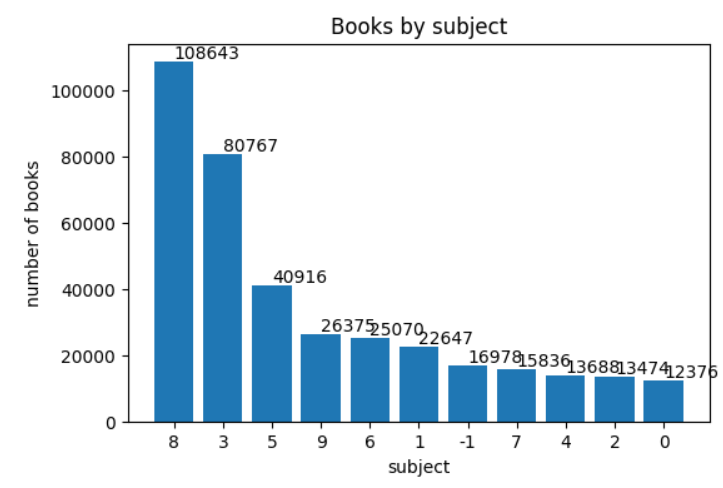
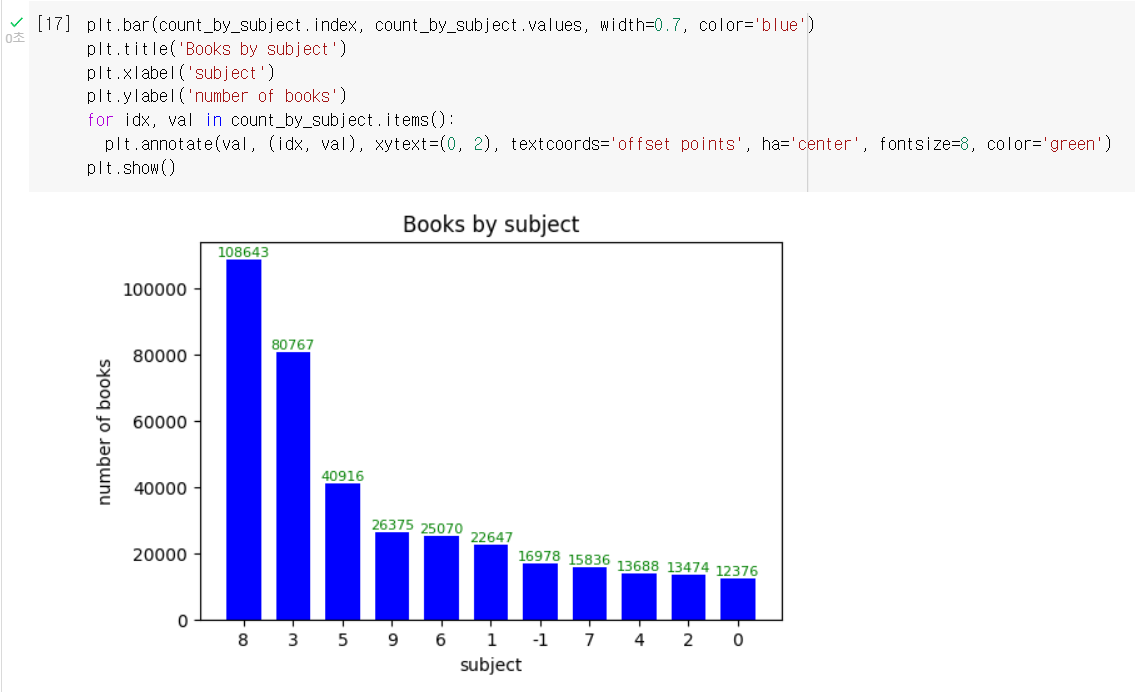
텍스트 정렬, 막대 조절 및 색상 바꾸기
텍스트 위치 조절은 annotate() 함수의 ha 매개변수를 이용, 텍스트가 서로 겹치는걸 방지하여 fontsize 매개변수로 크기변경, 텍스트 색상은 color 매개변수사용
막대 두께 조절은 bar() 함수의 width 매개변수 사용, 색상은 color 매개변수 사용
plt.bar(count_by_subject.index, count_by_subject.values, width=0.8, color='blue')
plt.title('Books by subject')
plt.xlabel('subject')
plt.ylabel('number of books')
for idx, val in count_by_subject.items():
plt.annotate(val, (idx, val), xytext=(0, 2), textcoords='offset points', ha='center', fontsize=8, color='green')
plt.show()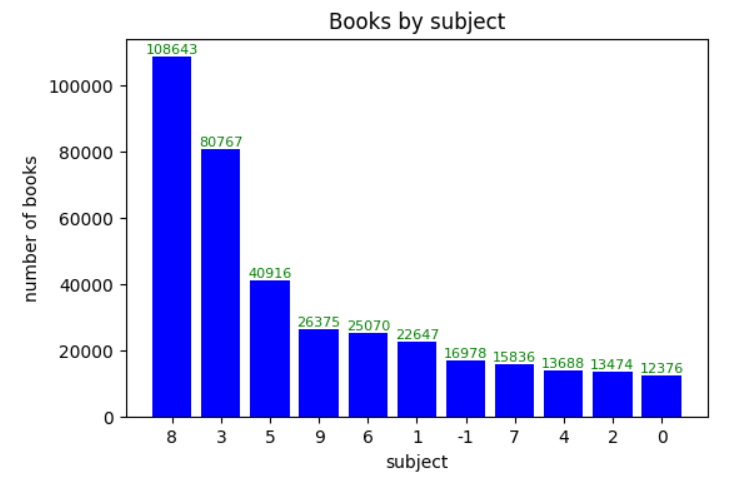
가로 막대 그래프 그리기 : barh() 함수
가로 막대 그래프의 두께는 height 매개변수 사용, x축과 y축의 이름을 바꾸어 사용해야함
plt.barh(count_by_subject.index, count_by_subject.values, height=0.7, color='blue')
plt.title('Books by subject')
plt.xlabel('number of books')
plt.ylabel('subject')
for idx, val in count_by_subject.items():
plt.annotate(val, (val, idx), xytext=(2, 0), textcoords='offset points', fontsize=8, va='center', color='green')
plt.show()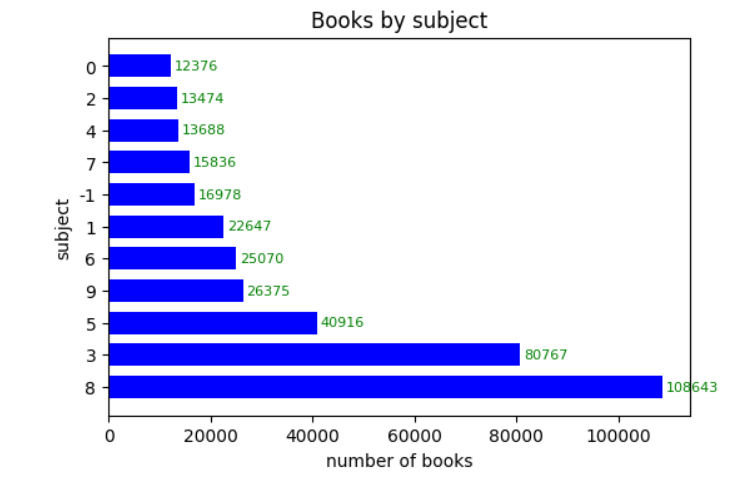
이미지 출력하고 저장하기
import sys
if 'google.colab' in sys.modules:
!wget https://bit.ly/3wrj4xf -O jupiter.png참고 : 코랩에서 !를 입력하는 것은 리눅스의 명령어를 실행하라는 뜻이라고함 그리고 !wget에 빨간줄로 에러 처리가되지만 정상적으로 다운로드됨… 이유는..? 모르겠음
이미지 읽기 : imread() 함수
img = plt.imread('jupiter.png')
img.shape
# 출력 (높이,너비, 채널)
(1561, 1646, 3)이미지 화면에 출력 : imshow() 함수
기본적으로 원본 이미지의 가로세로 비율을 유지하며 x, y의 눈금은 axis() 함수를 off로 지정
plt.imshow(img)
plt.show()
# 눈금 없애기
plt.axis('off')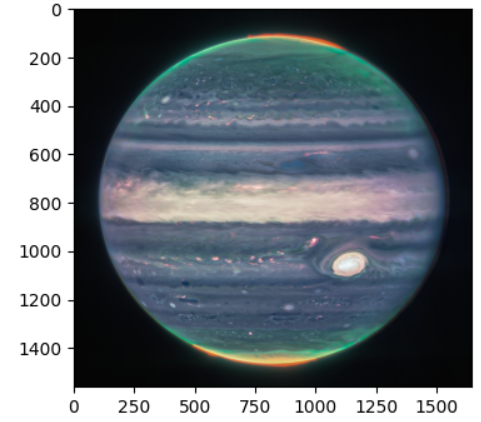
이미지 저장하기 : imsave() 함수
plt.imsave('jupiter.jpg', img)그래프를 이미지로 저장하기 : savefig() 함수
# 그래프를 저장할때 따로 사용할 dpi
plt.rcParams['savefig.dpi']
plt.barh(count_by_subject.index, count_by_subject.values, height=0.7, color='blue')
plt.title('Books by subject')
plt.xlabel('number of books')
plt.ylabel('subject')
for idx, val in count_by_subject.items():
plt.annotate(val, (val, idx), xytext=(2, 0), textcoords='offset points',
fontsize=8, va='center', color='green')
plt.savefig('books_by_subject.png')
plt.show()
# 저장된 파일 출력
pil_img = Image.open('books_by_subject.png')
pil_img = plt.imread('books_by_subject.png')
plt.figure(figsize=(8, 6))
plt.imshow(pil_img)
plt.axis('off')
plt.show()
plt.figure(figsize=(8, 6))
plt.imshow(pil_img)
plt.axis('off')
plt.show()p.323에서 저장된 파일을 출력할때 Pillow패키지를 이용해서 출력했지만 이부분은 참고부분이기 때문에 맷플롯립의 imread()함수를 사용하는것이 흐름상 적합해 보임 적합하지 않다면 p.324에 표로 정리된 함수에서는 왜 Pillow패키지에 관한내용이 없는지….
내말이 맞아!
함수
| 함수 | 기능 |
|---|---|
| matplotlib.pyplot.plot() | 선 그래프를 표현 |
| matplotlib.pyplot.title() | 그래프 제목 설정 |
| matplotlib.pyplot.xlabel() | x축 이름 지정 |
| matplotlib.pyplot.ylabel() | y축 이름 지정 |
| matplotlib.pyplot.xticks() | x축의 눈금 위치와 레이블 지정 |
| matplotlib.pyplot.annotate() | 지정한 좌표에 텍스트 출력 |
| matplotlib.pyplot.bar() | 세로 막대 그래프 표현 |
| matplotlib.pyplot.barh() | 가로 막대 그래프 표현 |
| matplotlib.pyplot.imread() | 이미지 파일을 넘파이 배열로 읽음 |
| matplotlib.pyplot.imshow() | 이미지 출력 |
| matplotlib.pyplot.imsave() | 넘파이 배열을 이미지 파일로 저장 |
| matplotlib.pyplot.savefig() | 그래프를 이미지로 저장 |
미션
- 필수미션
- 선택미션
오탈자 : p.325 확인 문제 2번의 보기 3번이 ‘.-’ 아니라 ‘-.’로 표시되어야 합니다. 마찬가지로 p.486 답안지의 05-2의 2번에 보기 3번이 ‘.-’ 아니라 ‘-.’로 표시되어야합니다.
오탈자 찾는데 재미들린거 같기도...
