데이터 수집 및 전처리 2
1. 구글 이미지 크롤링하기
jupyter notebook에서 BeautifulSoup과 selenium의 크롬 웹드라이버를 사용하여 구글에 음식 키워드로 검색하였을 때 나오는 음식이미지들을 추가로 300개씩 저장하였다. 그리고 관련이 없는 이미지를 직접 제거해준다.
import urllib.request
from urllib.request import urlopen
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.common import exceptions
search_name = ["된장찌개", "명란젓",
"당고", "오코노미야끼", "우메보시", "스키야키",
"훠궈", "동파육", "월병", "마파두부", "쟈오즈", "빠오즈", "만터우", "홍샤오로우", "베이징카오야"]
count = 200
driver = webdriver.Chrome(r"C:\Users\seenw\Downloads\chromedriver_win32\chromedriver.exe")
img_count = len(driver.find_elements_by_tag_name("img"))
driver.implicitly_wait(2)
for j in range(len(search_name)):
url = "https://www.google.com/search?q=" + str(search_name[j]) + "&hl=ko&tbm=isch"
driver.get(url)
folder = "C:/Users/seenw/OneDrive - inu.ac.kr/2021_4학년1학기/RISE/4주차/archive/Dishes/추가하기/" +search_name[j]+ "/"
for i in range(count):
img = driver.find_elements_by_tag_name("img")[i]
img.screenshot(folder + str(3000*j+i)+ ".png")
driver.close()이미지 저장한 폴더들:
크롤링 과정:
2. 구글 클라우드에 업데이트
3. 데이터 확인 및 전처리
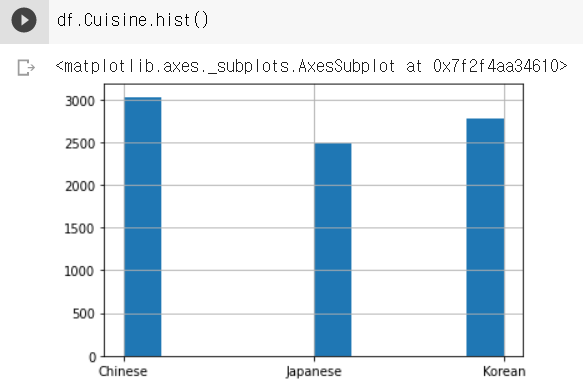
지난 번에 사용한 코드를 이용하여 데이터가 추가된 것을 확인하고 ImageDataGenerator를 이용하여 데이터 전처리까지 해준다.
결과1:
결과2:
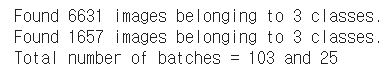

hi