[Python]N+1 문제와 ORM 관계 설정: SQLAlchemy selectinload 사례+subqueryload로 업그레이드
실무 Spring, Python, DB, 인프라

- SQLAlchemy의 N+1 문제 해결:
selectinload와subqueryload활용하기
이번 블로그에서는 N+1 문제와 ORM 관계 설정에서 발생할 수 있는 실무적인 문제를 다루려고 한다.
현재 서비스에서 User 모델과 Firm 모델이 1:N 관계를 가지며, 유저는 기업(Firm)에 소속될 수 있다.
관리자 페이지에서 전체 유저 목록을 조회하면서 각 유저의 소속 정보(Firm)를 함께 로드해야 했다. 하지만 초기 코드에서는 ORM 쿼리가 제대로 동작하지 않아 일부 유저의 Firm 정보가 누락되거나 조회 속도 느릴 수도 있다는 생각을 했다. 이는 ORM의 기본 로딩 전략에 대한 이해 부족과 잘못된 쿼리 방식으로 인해 발생한 문제였다.
이를 해결하기 위해 SQLAlchemy의 options와 selectinload를 활용해 쿼리를 최적화하고, ORM 관계 설정을 재검토했다.
모델 관계 설정
서비스에서 정의된 User와 Firm은 아래와 같은 관계를 가지고 있다.
User모델: 유저 정보를 저장하며,Firm과 N:1 관계를 가짐.Firm모델: 기업 정보를 저장하며,User와 1:N 관계를 가짐.
class User(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True)
username = Column(String(80), nullable=False)
..
..
firm_id = Column(Integer, ForeignKey("firm.id"), nullable=True)
firm = relationship("Firm", back_populates="members")
class Firm(Base):
__tablename__ = "firm"
id = Column(Integer, primary_key=True)
firm_name = Column(String(100), nullable=False)
..
..
members = relationship("User", back_populates="firm")문제 정의
처음 작성된 get_users_query는 다음과 같았다.
def get_users_query(self):
return self.db.query(UserModel).all()이 코드는 단순히 User 모델 데이터를 리스트 형태로 반환한다. 여기까지는 문제가 없어 보였지만, 유저의 Firm 데이터를 함께 가져와야 할 때 다음과 같은 문제가 발생했다.
-
N+1 문제 발생 가능성
Firm데이터는 Lazy Loading으로 로드되기 때문에, 각User의Firm에 접근할 때마다 별도의 쿼리가 실행된다.예를 들어, 유저가 100명이라면
User데이터를 가져오는 쿼리 1개 + 각Firm을 가져오는 100개의 추가 쿼리가 실행되어 101개의 쿼리가 발생한다. -
성능 문제
Lazy Loading은 작은 데이터에서는 문제가 없을 수 있지만, 데이터 양이 많아질수록 성능에 큰 영향을 준다. 특히, 다중 관계를 가진 데이터의 경우 문제가 더 심각해진다.
-
페이징, 필터링 문제
.all()메서드는 결과를 리스트로 반환하므로, 이후 필터링이나 페이징 작업을 적용하기 어렵다.
SQL 쿼리 실행 흐름:
User테이블에서 전체 유저 목록 조회 (1개의 쿼리 실행).- 각 유저마다
Firm정보를 조회하기 위한 쿼리 실행 (N개의 쿼리 실행).
결과적으로, 유저가 100명이라면, 총 101개의 쿼리가 실행된다.
기존 코드가 가진 문제의 원인
get_users_query에서 기본적인query(UserModel).all()만 호출했기 때문에,Firm모델과의 관계가 로드되지 않았다.Firm정보를 로드하기 위해 JOIN 쿼리를 작성하지 않았으므로, ORM이 기본적으로 지연 로딩(lazy loading)을 수행했다.lazy loading은 각 유저에 대해Firm정보를 개별 쿼리로 조회하면서 N+1 문제가 발생하게 된다.
해결 과정
문제를 해결하기 위해 SQLAlchemy의 options와 selectinload를 사용했다.
개선된 코드
def get_users_query(self):
return self.db.query(UserModel).options(selectinload(UserModel.firm))options: 쿼리 옵션을 정의하여 ORM이 데이터를 로드하는 방식을 제어한다.- 문제를 해결하기 위해 SQLAlchemy의
options와selectinload를 사용했다. 이후 추가적으로subqueryload도 테스트해 보았다.
SQL 쿼리 실행 흐름:
User테이블에서 전체 유저 목록 조회 (1개의 쿼리 실행).- 조회된 유저들의
Firm정보를 한 번의 쿼리로 로드 (1개의 추가 쿼리 실행).
이제 유저가 100명이라도 총 2개의 쿼리만 실행된다.
결과 및 성능 개선
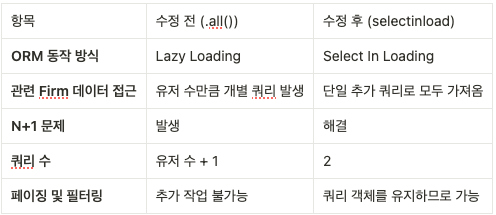
수정 전과 수정 후의 SQL 실행 흐름 비교는 아래와 같다.
수정 전:
User데이터를 가져오는 쿼리 (1개)- 각
Firm데이터를 가져오는 쿼리 (유저 수만큼 실행)- 예: 유저 100명 → 총 101개의 쿼리 실행
수정 후:
User데이터를 가져오는 쿼리 (1개)- 관련된
Firm데이터를 가져오는 추가 쿼리 (1개)- 예: 유저 100명 → 총 2개의 쿼리 실행
결과 비교
추가 selectinload 활용
퇴근하고 다른 방법이 더 없을까 고민하다가 selectinload라는 것을 찾았다.
벤치마킹을 통해 좀 더 나은 성능을 보였고, 이를 추가로 활용해 보았다.
ORM 사용 시 성능 개선 방법
ORM이 생성하는 쿼리를 기반으로 작업할 때 중요한 것은 모델 구성과 쿼리 옵션을 통해 성능 병목을 해결하는 것이다.
1. selectinload 활용
- 이미 적용한
selectinload는 N+1 문제를 해결하는 데 매우 효과적이다. 하지만 상황에 따라subqueryload가 더 적합할 수 있다. selectinloadvssubqueryload:selectinload: 관계 데이터가 적고, 즉시 로드가 필요한 경우.subqueryload: 관계 데이터가 많아SELECT쿼리를 분리하여 처리하는 것이 더 효율적일 때.
- 테스트를 통해 둘 중 어떤 것이 더 적합한지 확인 후 적용한다.
users = db.query(User).options(selectinload(User.firm)).order_by(User.id.desc()).all()
# 실행 시간 예시: 259ms, 138ms, 123ms, 200ms, 127ms, 117msusers = db.query(User).options(subqueryload(User.firm)).order_by(User.id.desc()).all()
# 실행 시간 예시: 129ms, 155ms, 160ms, 153ms, 69ms, 64ms, 65ms, 137ms, 65ms, 64ms, 68ms, 187ms2. subqueryload가 더 빠른 이유
-
서브쿼리 방식
subqueryload는 부모 데이터를 가져온 후, 자식 데이터를 서브쿼리로 한 번에 가져온다. 추가 쿼리를 최소화하며, 데이터베이스 옵티마이저가 서브쿼리를 효율적으로 처리할 수 있다. -
N+1 문제 회피
selectinload는 부모 데이터를 가져온 후 각 부모에 대해 자식 데이터를 개별 쿼리로 실행한다. 부모 데이터가 많아질수록 쿼리 수가 증가하여 N+1 문제가 발생할 수 있다. 반면subqueryload는 한 번의 서브쿼리로 자식 데이터를 모두 가져온다. -
데이터 크기와 복잡성
부모 데이터와 자식 데이터의 크기가 크고 복잡할수록
subqueryload가 더 효율적이다. JOIN을 직접 사용하지 않기 때문에 관계가 많은 경우에도 성능이 유지된다.
3. selectinload가 더 빠른 경우
-
부모 데이터가 적을 때
부모 데이터가 적고, 관계 데이터가 작을 경우
selectinload가 더 간단한 쿼리로 빠르게 처리할 수 있다. -
데이터베이스 옵티마이저 차이
일부 데이터베이스는 서브쿼리보다 IN 절로 데이터를 가져오는 방식(
selectinload)을 더 효율적으로 처리할 수 있다. -
자식 데이터가 크지 않을 때
자식 데이터가 크지 않거나, 부모-자식 관계에서 자식 데이터가 가벼운 경우
selectinload가 더 빠를 수 있다. -
특정 캐싱 상황
부모 데이터가 캐싱되어 있는 경우, 추가적인 자식 데이터를 가져오는
selectinload가 서브쿼리보다 빠르게 작동할 수 있다.
3. 선택 기준
subqueryload사용:- 부모 데이터가 많고, 자식 데이터가 크거나 관계가 복잡한 경우.
- 데이터베이스가 서브쿼리를 잘 최적화할 수 있는 경우.
selectinload사용:- 부모 데이터가 적고, 간단한 관계를 처리하는 경우.
- 서브쿼리가 비효율적으로 처리되는 데이터베이스를 사용하는 경우.
맺음말
subqueryload와 selectinload 모두 상황에 따라 다르게 작동한다. 최적화를 위해 데이터를 분석하고 테스트를 통해 적합한 로딩 방식을 선택하는 것이 중요하다. 특히, 대규모 데이터베이스 환경에서는 다양한 로딩 전략을 실험해보고 가장 효율적인 방법을 선택하는 것이 성능 향상에 큰 도움이 된다.
이번 포스트에서는 User와 Firm 모델을 예시로 들어 N+1 문제를 해결하는 과정을 살펴보았다. 실제 프로젝트에서도 이러한 접근 방식을 통해 ORM의 성능을 최적화할 수 있으니, 상황에 맞는 로딩 전략을 적극 활용해 보시기 바란다.
ㅋㅋ
Ref.
