
지난 번 작성한 전체 유저 목록 조회 기능에 검색 기능을 추가했다.
검색 조건은 다음과 같았다.
입력은 하나였으며, 사용자 이름, 이메일, Role, 소속 이름 총 네 개의 항목에 대해 검색할 수 있어야 했다.
문제는 소속 이름(Firm Name)과 나머지 검색 항목이 서로 다른 테이블에서 관리된다는 점이었다.
이를 해결하기 위해 어떻게 검색 조건을 통합적으로 처리할 수 있을지 고민했다.
그 결과, ILIKE와 Full-Text Search를 병합해서 사용하는 것이 가장 효율적이라는 결론을 내렸다.
이 과정에서 사용된 기술과 결과를 정리한다.
문제 정의
검색 조건:
1. 사용자 이름 (username)
2. 이메일 (email)
3. 사용자 역할 (role_type)
4. 소속 이름 (firm_name)
이 네 가지를 하나의 검색어로 처리해야 한다.
username,email,role_type은users테이블에 포함되어 있지만,firm_name은 별도의 테이블(firm)에 존재한다.
이러한 조건으로 인해 테이블 간의 JOIN이 필요했고,
또한 검색 조건이 부분 문자열 매칭인지, 단어 기반 검색인지에 따라 최적화 방법이 달라질 수 있었다.
*기본 검색 방식
1. ILIKE
- 설명:
- SQL에서 문자열 비교를 위한 연산자.
- 대소문자를 구분하지 않고 부분 문자열 검색을 수행.
- 예:
username ILIKE '%검색어%'
- 특징:
- 간단한 구현과 넓은 호환성을 제공.
- 검색어가 길거나 데이터가 많아질수록 성능 저하 가능.
- SQL 인덱스 최적화:
CREATE EXTENSION IF NOT EXISTS pg_trgm; CREATE INDEX idx_users_username_trgm ON users USING gin (username gin_trgm_ops); CREATE INDEX idx_users_email_trgm ON users USING gin (email gin_trgm_ops); CREATE INDEX idx_firm_name_trgm ON firm USING gin (firm_name gin_trgm_ops);pg_trgm확장:- PostgreSQL의 트라이그램 기반 확장 기능.
- 문자열의 부분 매칭에 대해 GIN 또는 GIST 인덱스를 제공.
gin_trgm_ops:- GIN 인덱스를 트라이그램 연산자로 활용.
2. Full-Text Search
- 설명:
- PostgreSQL의 단어 기반 검색 기능.
- 검색 필드에 가중치를 부여하여 검색 결과의 우선순위를 정할 수 있음.
- 설정 과정:
-
tsvector컬럼 생성:ALTER TABLE users ADD COLUMN search_vector tsvector; ALTER TABLE firm ADD COLUMN search_vector tsvector; -
기존 데이터 업데이트:
UPDATE users SET search_vector = setweight(to_tsvector('simple', username), 'A') || setweight(to_tsvector('simple', email), 'B') || setweight(to_tsvector('simple', CAST(role_type AS TEXT)), 'C'); UPDATE firm SET search_vector = to_tsvector('simple', firm_name); -
트리거 생성:
CREATE OR REPLACE FUNCTION update_users_search_vector() RETURNS TRIGGER AS $$ BEGIN NEW.search_vector = setweight(to_tsvector('simple', NEW.username), 'A') || setweight(to_tsvector('simple', NEW.email), 'B') || setweight(to_tsvector('simple', CAST(NEW.role_type AS TEXT)), 'C'); RETURN NEW; END; $$ LANGUAGE plpgsql; CREATE TRIGGER trigger_update_users_search_vector BEFORE INSERT OR UPDATE ON users FOR EACH ROW EXECUTE FUNCTION update_users_search_vector(); -
GIN 인덱스 생성:
CREATE INDEX idx_users_search_vector ON users USING gin (search_vector); CREATE INDEX idx_firm_search_vector ON firm USING gin (search_vector);
search_vector:- 텍스트 데이터를 검색 가능한 형태로 변환한 컬럼.
GIN인덱스:- 검색 속도를 극대화하기 위한 데이터 구조.
-
검색 성능 비교
테스트 데이터
users테이블: 46개의 사용자 데이터.- 검색 조건: "전준영", "준영", "영", "디스", "디스커버리".
케이스 1. ILIKE + Full-Text Search 조합
ts_query = func.plainto_tsquery(text("'simple'"), condition)
query = query.outerjoin(Firm, UserModel.firm_id == Firm.id).filter(
or_(
UserModel.username.ilike(f"%{condition}%"), # ILIKE로 검색
UserModel.email.ilike(f"%{condition}%"), # ILIKE로 검색
cast(UserModel.role_type, String).ilike(f"%{condition}%"), # ENUM 처리
Firm.firm_name.ilike(f"%{condition}%"), # ILIKE로 검색
UserModel.search_vector.op('@@')(ts_query), # Full-Text Search
Firm.search_vector.op('@@')(ts_query) # Full-Text Search
)
)성능 결과:
- 검색어: "전준영" → 176ms, 172ms, 176ms
- 검색어: "준영" → 182ms, 184ms, 173ms
- 검색어: "영" → 170ms, 183ms, 173ms
- 검색어: "디스" → 157ms, 178ms, 191ms
- 검색어: "디스커버리" → 182ms, 184ms, 191ms
케이스 2. ILIKE + JOIN 조합
query = self.db.query(UserModel).outerjoin(Firm, UserModel.firm_id == Firm.id).filter(
or_(
UserModel.username.ilike(f"%{condition}%"),
UserModel.email.ilike(f"%{condition}%"),
cast(UserModel.role_type, String).ilike(f"%{condition}%"),
Firm.firm_name.ilike(f"%{condition}%")
)
)성능 결과:
- 검색어: "전준영" → 177ms, 177ms, 171ms
- 검색어: "준영" → 194ms, 172ms, 217ms
- 검색어: "영" → 170ms, 199ms, 171ms
- 검색어: "디스" → 196ms, 184ms, 193ms
- 검색어: "디스커버리" → 188ms, 189ms, 200ms
결론 및 성능 분석
- 짧은 키워드 검색:
- "영", "준영"과 같은 짧은 검색어에서는 ILIKE가 Full-Text Search와 비슷하거나 더 나은 성능을 보였다.
- 이는 Full-Text Search가 짧은 키워드에서 더 많은 데이터를 스캔하기 때문이다.
- 긴 키워드 검색:
- "디스커버리"와 같이 긴 검색어에서는 Full-Text Search가 더 나은 성능을 보였다.
- 이는 Full-Text Search가 인덱스를 기반으로 단어 매칭을 빠르게 수행하기 때문이다.
- 혼합 전략의 필요성:
- 실제 서비스에서는 키워드 길이에 따라 ILIKE와 Full-Text Search를 병행하는 방식이 유효하다.
- 예를 들어, 짧은 검색어는 ILIKE를 사용하고, 긴 검색어는 Full-Text Search를 우선 적용한다.
맺음말
이번에는 ILIKE와 풀텍스트 검색(Full-Text Search)을 조합해 사용자 목록 조회 기능에 검색을 추가한 사례를 다뤘다. PostgreSQL의 다양한 기능을 활용하면서 효율적인 검색 방법을 고민했고, 작지만 의미 있는 성과를 확인할 수 있었다.
다만, 솔직히 말하자면 이 과정에서 몇 가지 고민이 들었다. 우선 테스트 데이터가 1000건으로 작다 보니, 실제 대규모 데이터 환경에서는 어떤 문제가 발생할지 명확히 예측하기 어렵다. 예를 들어, 데이터가 수백만 건으로 늘어나거나 삽입/업데이트 작업이 잦아진다면 현재 설계가 여전히 효과적일지 확신하기 어렵다. 또, GIN 인덱스의 유지 비용이나 JOIN 연산의 성능 문제를 어떻게 해결해야 할지도 아직은 막연하다.
이런 상황이 오면 어떤 대안이 적절할지, 그리고 그 대안을 어떻게 준비해야 할지 잘 모르겠다. 왜냐하면 아직 내 경험과 공부가 부족하기 때문이다. 하지만 분명한 것은, 이러한 고민을 마주할 때마다 배움과 경험을 쌓아가면서 조금씩 더 나아질 수 있을 거라는 믿음이다.
앞으로 데이터가 많아지고 복잡한 요구 사항이 추가되면, Redis 같은 캐싱 시스템이나 Elasticsearch 같은 전문 검색 엔진을 사용하는 방법도 고민하게 될 것이다. 그 시점이 오면, 그때의 나에게 더 나은 답을 기대해본다.
추가개념
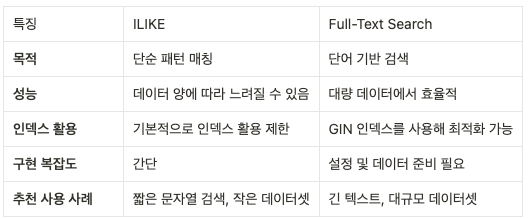
Ilike 와 풀텍스트 검색의 이해
PostgreSQL에서 ILIKE는 대소문자를 구분하지 않고 패턴 매칭을 수행하는 연산자다.
예를 들어, ILIKE '%검색어%'와 같이 사용하면 특정 문자열을 포함하는 모든 레코드를 찾을 수 있다.
하지만 이 방식은 인덱스를 효율적으로 사용하지 못해 대량의 데이터에서 성능 저하를 초래할 수 있다.
반면, 풀텍스트 검색은 자연어 처리를 통해 문서 내의 단어를 기반으로 검색을 수행한다.
이를 위해 tsvector와 tsquery 데이터 타입을 사용하며, 인덱스를 통해 빠른 검색이 가능하다.
GIN (Generalized Inverted Index) 인덱스
정의
- PostgreSQL에서 GIN 인덱스는 여러 키를 포함하는 데이터 타입을 위한 고성능 검색 인덱스
- 일반적으로
ARRAY,JSONB,tsvector, 그리고pg_trgm과 함께 사용
GIN 인덱스의 특징
- 다중 키 데이터 타입에 적합
- 한 컬럼에 여러 키를 포함하는 데이터(예: 텍스트, 배열 등)에 대해 효율적으로 검색 가능
- 빠른 검색
- 많은 키를 포함하는 데이터를 인덱싱하고, 특정 키를 빠르게 찾을 수 있다
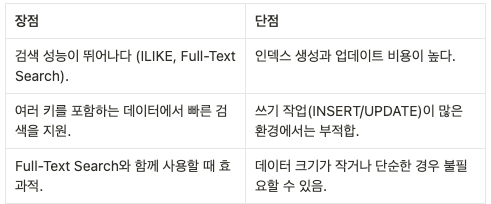
- 비용
- GIN 인덱스는 데이터 삽입/업데이트 시 오버헤드가 높음
- 하지만 검색 속도는 매우 뛰어나며, 대량의 읽기 작업이 필요한 워크로드에 적합
- 지원 데이터 타입
tsvector(Full-Text Search)pg_trgm(문자열 유사도)JSONB(JSON 데이터 검색)ARRAY
GIN 인덱스 생성
-
기본 명령어
CREATE INDEX idx_users_search_vector ON users USING gin (search_vector); CREATE INDEX idx_users_email_trgm ON users USING gin (email gin_trgm_ops);USING gin: GIN 인덱스를 생성.gin_trgm_ops:pg_trgm확장을 사용해ILIKE와 같은 연산 최적화.
-
활용 사례
- Full-Text Search:
CREATE INDEX idx_users_search_vector ON users USING gin (search_vector); ILIKE최적화 (pg_trgm):CREATE INDEX idx_users_username_trgm ON users USING gin (username gin_trgm_ops);
- Full-Text Search:
GIN 인덱스의 장단점
Ref.
https://www.postgresql.org/docs/current/textsearch.html
https://www.slingacademy.com/article/using-like-and-ilike-in-postgresql/
https://www.postgresql.org/docs/current/functions-matching.html
https://www.postgresql.org/docs/current/datatype-textsearch.html
https://www.postgresql.org/docs/current/gin.html
