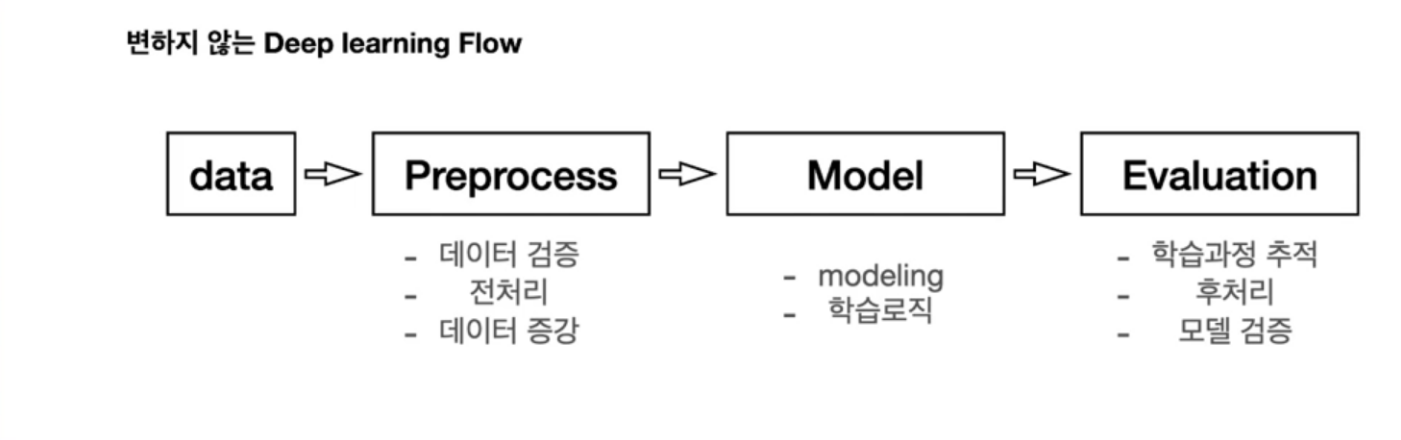
Deep Learning Flow
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline변하지 않는 Deep learning Flow
1. Data 가져오기
TensorFlow에서 제공하는 MNIST 예제
- 데이터 shape, dtype 확인하기
(train_x, train_y), (test_x, test_y) = tf.keras.datasets.mnist.load_data()print(train_x.shape)
print(train_y.dtype)
print(test_x.shape)
print(test_y.dtype)(60000, 28, 28)
uint8
(10000, 28, 28)
uint8image = train_x[77:78]
image.shape(1, 28, 28)image = train_x[51]
image.shape(28, 28)plt.imshow(image, 'gray')
plt.show()
데이터를 받으면 데이터를 이해하기 위해 노력해야합니다!
ex> 훈련용 데이터셋에는 각 숫자의 그림이 몇개씩 들어가 있나? (QUIZ)
y_unique, y_counts = np.unique(train_y, return_counts=True)y_unique, y_counts(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8),
array([5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949],
dtype=int64))df_view = pd.DataFrame({'count' : y_counts}, index=y_unique)
df_view| count | |
|---|---|
| 0 | 5923 |
| 1 | 6742 |
| 2 | 5958 |
| 3 | 6131 |
| 4 | 5842 |
| 5 | 5421 |
| 6 | 5918 |
| 7 | 6265 |
| 8 | 5851 |
| 9 | 5949 |
df_view.sort_values('count')| count | |
|---|---|
| 5 | 5421 |
| 4 | 5842 |
| 8 | 5851 |
| 6 | 5918 |
| 0 | 5923 |
| 9 | 5949 |
| 2 | 5958 |
| 3 | 6131 |
| 7 | 6265 |
| 1 | 6742 |
plt.bar(x=y_unique, height=y_counts, color='green')
plt.title('label distribution')
plt.show()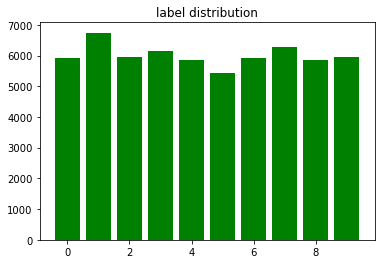
막간 퀴즈
다음 코드를 완성하여, 아래 이미지를 시계 반대 방향으로 90도 회전하고 아래위를 반전 시키기
image = tf.constant(image)plt.imshow(image, 'gray')
plt.show()
plt.imshow(tf.transpose(image), 'gray')
plt.show()
2. Preprocessing
- 데이터 검증
- 전처리
- 데이터 증강 ... (이 건 추후에!)
데이터 검증
- 데이터 중에 학습에 포함 되면 안되는 것이 있는가? ex> 개인정보가 들어있는 데이터, 테스트용 데이터에 들어있는것, 중복되는 데이터
- 학습 의도와 다른 데이터가 있는가? ex> 얼굴을 학습하는데 발 사진이 들어가있진 않은지(가끔은 의도하고 일부러 집어넣는 경우도 있음)
- 라벨이 잘못된 데이터가 있는가? ex> 7인데 1로 라벨링, 고양이 인데 강아지로 라벨링
- ... 등
def validate_pixel_scale(x):
return 255 >= x.max() and 0 <= x.min()validated_train_x = np.array([x for x in train_x if validate_pixel_scale(x)])
validated_train_y = np.array([y for x, y in zip(train_x, train_y) if validate_pixel_scale(x)])print(validated_train_x.shape)
print(validated_train_y.shape)(60000, 28, 28)
(60000,)전처리
- 입력하기 전에 모델링에 적합하게 처리!
- 대표적으로 Scaling, Resizing, label encoding 등이 있다.
- dtype, shape 항상 체크!!
Scaling
def scale(x):
return (x / 255.0).astype(np.float32)sample = scale(validated_train_x[777])sns.displot(sample)<seaborn.axisgrid.FacetGrid at 0x2928fbd0490>
scale_train_x = np.array([scale(x) for x in validated_train_x])Flattening
- 이번에 사용할 모델은 기본적인 Feed-Forward Neural Network
- 1차원 벡터가 Input의 샘플 하나가 된다. (2차원 텐서라는 말)
flattend_train_x = scale_train_x.reshape((60000, -1))flattend_train_x.shape(60000, 784)Label encoding
- One-Hot encoding
tf.keras.utils.to_categorical사용!
tf.keras.utils.to_categorical(5, num_classes=10)array([0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], dtype=float32)ohe_train_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_train_y])ohe_train_y.shape(60000, 10)보통은 큰 작업을 하나의 클래스로 만들어서 관리한다.
class DataLoader():
def __init__(self):
(self.train_x, self.train_y), (self.test_x, self.test_y) = tf.keras.datasets.mnist.load_data()
def validate_pixel_scale(self, x):
return 255 >= x.max() and 0 <= x.min()
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
feature, target = dataset
validated_x = np.array([x for x in feature if self.validate_pixel_scale(x)])
validated_y = np.array([y for x, y in zip(feature, target) if self.validate_pixel_scale(x)])
# scale
scaled_x = np.array([self.scale(x) for x in validated_x])
#flatten
flatten_x = scaled_x.reshape((scaled_x.shape[0], -1))
# label encoding
ohe_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in validated_y])
return flatten_x, ohe_y
def get_train_dataset(self):
return self.preprocess_dataset((self.train_x, self.train_y))
def get_test_dataset(self):
return self.preprocess_dataset((self.test_x, self.test_y))mnist_loader = DataLoader()train_x, train_y = mnist_loader.get_train_dataset()test_x, test_y = mnist_loader.get_train_dataset()print(train_x.shape)
print(train_y.shape)
print(test_x.shape)
print(test_y.shape)(60000, 784)
(60000, 10)
(60000, 784)
(60000, 10)3. Modeling
- 모델 정의
- 학습 로직 - 비용함수, 학습파라미터 세팅
- 학습
모델 정의
from tensorflow.keras.layers import Dense, Activation# 모델에 들어있는 tf.keras.Sequential() 라는 classes
# Sequential()은 add 함수를 통해서 layer들을 추가 할 수 있고,
# summary()라는 명령어를 통해서 이 layer들이 추가된 결과, 즉 모델의 정보를 출력할 수 있다.
model = tf.keras.Sequential()model.add(Dense(15, input_dim=784))
model.add(Activation('sigmoid'))
model.add(Dense(10))
model.add(Activation('softmax'))model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 15) 11775
activation (Activation) (None, 15) 0
dense_1 (Dense) (None, 10) 160
activation_1 (Activation) (None, 10) 0
=================================================================
Total params: 11,935
Trainable params: 11,935
Non-trainable params: 0
_________________________________________________________________학습 로직
opt = tf.keras.optimizers.SGD(0.03) # learning-rate = 0.03
loss = tf.keras.losses.categorical_crossentropy # 분류 문제는 대부분 이 loss 값을 사용한다.# metrics --> 학습에 영향 없이, 학습 과정에서 이 모델이 잘 학습하고 있는가 가늠하는 역할
model.compile(optimizer=opt, loss=loss, metrics=['accuracy'])학습 실행
hist = model.fit(train_x, train_y, epochs=10, batch_size=256)Epoch 1/10
235/235 [==============================] - 0s 2ms/step - loss: 0.5888 - accuracy: 0.8754
Epoch 2/10
235/235 [==============================] - 1s 2ms/step - loss: 0.5561 - accuracy: 0.8794
Epoch 3/10
235/235 [==============================] - 0s 2ms/step - loss: 0.5287 - accuracy: 0.8829
Epoch 4/10
235/235 [==============================] - 0s 2ms/step - loss: 0.5054 - accuracy: 0.8856
Epoch 5/10
235/235 [==============================] - 0s 2ms/step - loss: 0.4855 - accuracy: 0.8878
Epoch 6/10
235/235 [==============================] - 0s 2ms/step - loss: 0.4683 - accuracy: 0.8894
Epoch 7/10
235/235 [==============================] - 0s 2ms/step - loss: 0.4533 - accuracy: 0.8914
Epoch 8/10
235/235 [==============================] - 0s 2ms/step - loss: 0.4401 - accuracy: 0.8931
Epoch 9/10
235/235 [==============================] - 0s 2ms/step - loss: 0.4284 - accuracy: 0.8946
Epoch 10/10
235/235 [==============================] - 0s 2ms/step - loss: 0.4179 - accuracy: 0.8960# history를 이용해 학습과정이 잘 진행이 되었는지 tracking 할 수 있다.
hist.history{'loss': [0.5888213515281677,
0.556081235408783,
0.5286503434181213,
0.5054345726966858,
0.4854888617992401,
0.46829521656036377,
0.45333197712898254,
0.4401417672634125,
0.4284108281135559,
0.41793185472488403],
'accuracy': [0.8754333257675171,
0.8793833255767822,
0.8828999996185303,
0.8855833411216736,
0.8877666592597961,
0.8894166946411133,
0.8913833498954773,
0.8930500149726868,
0.8946499824523926,
0.896049976348877]}4. Evaluation
- 학습 과정 추적
- Test / 모델 검증
- 후처리학습 과정 추적
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.plot(hist.history['loss'])
plt.subplot(122)
plt.plot(hist.history['accuracy'])
plt.show()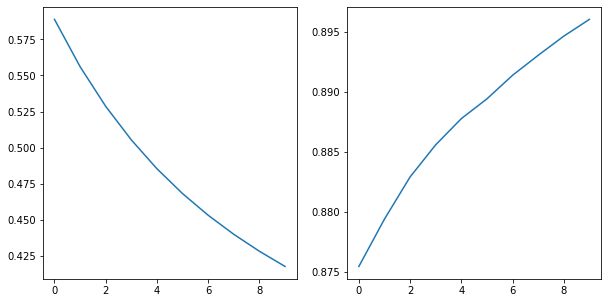
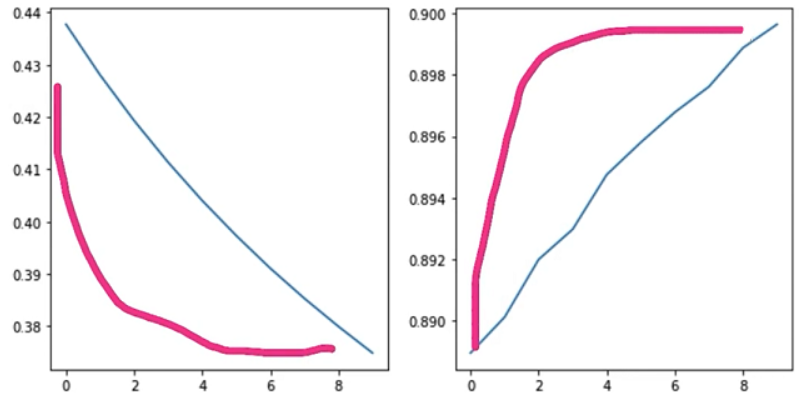
- 이런 그래프가 될 때까지 학습이 더 필요하다.
모델 검증
model.evaluate(test_x, test_y)1875/1875 [==============================] - 3s 1ms/step - loss: 0.4128 - accuracy: 0.8969
[0.4127863347530365, 0.8968833088874817]후처리
pred = model.predict(test_x[:1])predarray([[0.12319393, 0.00610622, 0.0074201 , 0.3975122 , 0.00044884,
0.40951982, 0.00674142, 0.02930495, 0.01512059, 0.00463186]],
dtype=float32)pred.argmax()5test_x[0].shape(784,)sample_img = test_x[0].reshape((28, 28)) # * 255 --> matplotlib에서 0에서 1사이의 값도 지원 하므로...test_y[0]array([0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], dtype=float32)plt.imshow(sample_img, cmap='gray')
plt.show()

THEO's velog