모델
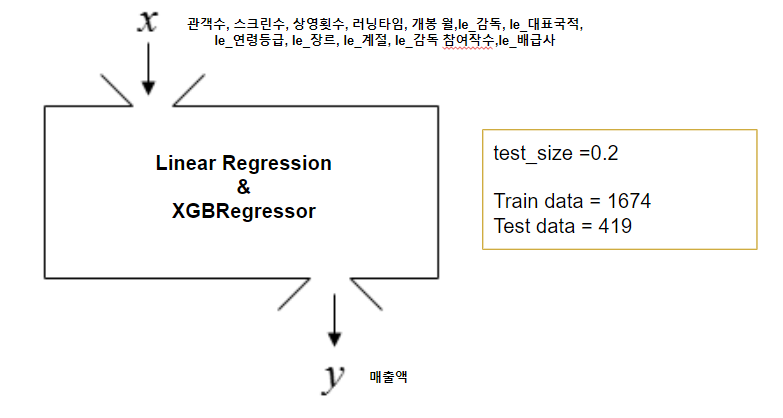
결과
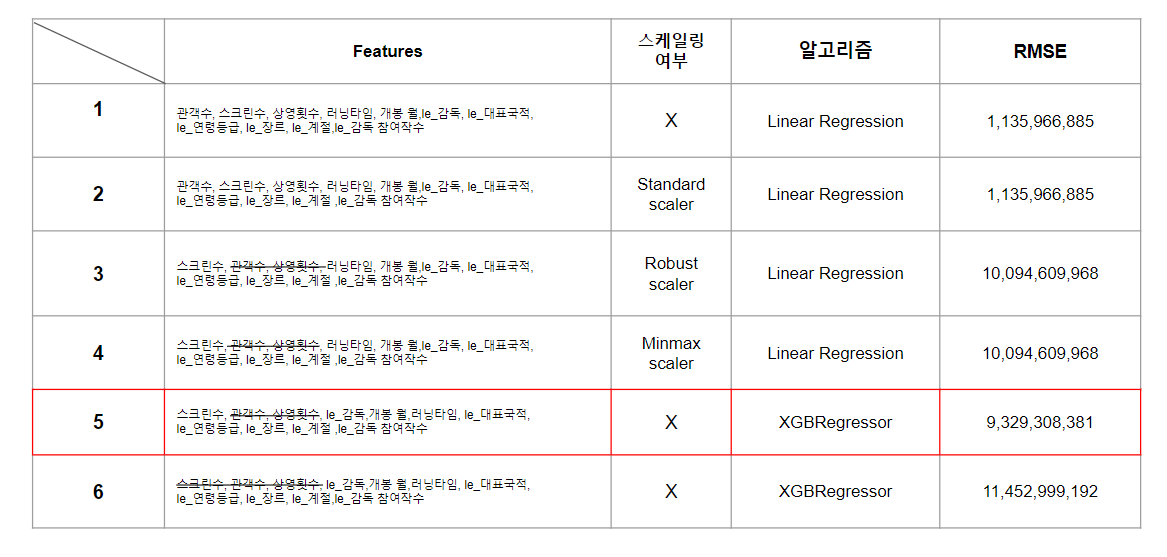
- 모델들의 성능 평가 지표로는 Rmse를 사용
- 첫번째로 모든 features를 넣고, 스케일링을 하지 않은 상태에 선형 회귀 알고리즘을 사용 --> RMSE는 14억이 나와 모델 중에서 가장 실제값과 오류값의 차이가 적은 결과. 상관 계수가 높았던 관객수, 상영횟수가 포함되어 있기에 높은 수치가 나온 것으로 해석
- 두번째 시도에는 스케일링을 하면 성능에 차이가 있을거 같아 standard scaler를 적용함 --> RMSE 차이가 없음. 더불어, Robust, minmax scaler 모두 사용해도 성능에는 차이가 없음
- 세번째, 네번째 시도로는 가장 상관관계가 높은 두 특징인 관객수, 상영횟수를 drop 하고 스케일러를 유지한 모델 --> 그 결과 관객수, 상영횟수를 유지한 모델보다 오류 수치가 약 10배가량 증가
- 다섯번째 시도는 XGB Regressor을 사용하여 스케일링 없이 관객수, 상영횟수를 drop 시킨채 성능검사 --> 네번째 모델과 비교해 봤을때 알고리즘만 다른 상태임에도, 오류값이 1억 정도 적음.
- 마지막으로 관객수, 상영횟수 다음으로 높은 상관관계인 스크린수도 제거 --> 성능에 가장 영향을 많이 끼치는 세 변수를 모두 드롭시키니 가장 성능이 낮아짐.
모델 선택
- 기획한 머신러닝 모델은 개봉 예정작들의 영화 매출액을 예측하는 모델이므로,
- 머신러닝 입장에서는 앞으로 개봉될 영화의 관객수와, 상영횟수에 대한 정보는 학습 불가
- 그러므로 관객수와, 상영횟수를 drop 한 모델을 써야하고, 관객수와 상영횟수를 features에서 제거한 모델 중 에서 가장 성능이 높은 ‘xgb regressor’ 를 최종 모델로 선정!
머신러닝 예측값 VS 실제값
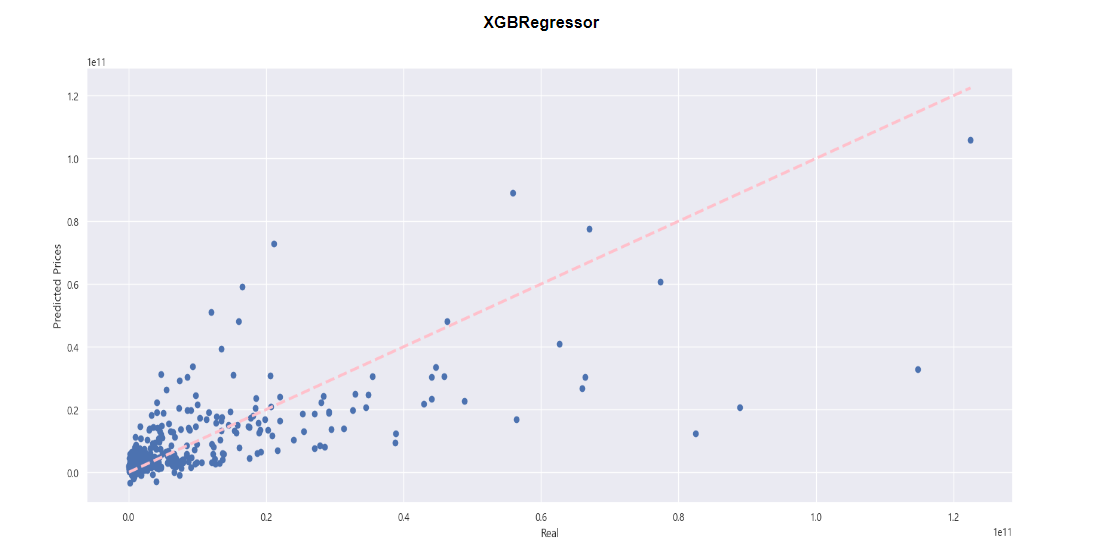
- 파란 점들이 핑크색 선에 가까울수록 머신러닝이 정확하게 예측을 했다고 판단
- 실제 매출액보다 머신러닝이 예측한 값이 많은 경우도 있고, 실제 매출액이 더 적은 경우도 존재
- 몇몇개를 제외하면 큰 오차 없이 머신러닝이 예측하고 있는 것을 확인
결론
변수들

- 상관관계가 높을 것이라고 예상했었던 특징인 관객수, 상영횟수, 스크린수가 역시나 매출액에 막중한 영향을 미침
- 뻔한 결과를 원하지 않아, ‘배급사, 대표국적, 연령등급, 장르, 계절, 감독, 감독참여작 수 ‘ 와 같은 예상 밖의 다른 특징들이 매출액과 어떤 관련이 있을까 에 대해 좀 더 매진
- 여러 라벨 인코딩을 시도 해보고, 문자열 데이터를 숫자로 바꾸는 과정에서 여러 기준을 두고 바꿔보았지만 상관관계가 0.4인 감독을 제외하고는 별다른 관계를 찾지 못함
영화 매출액 예상
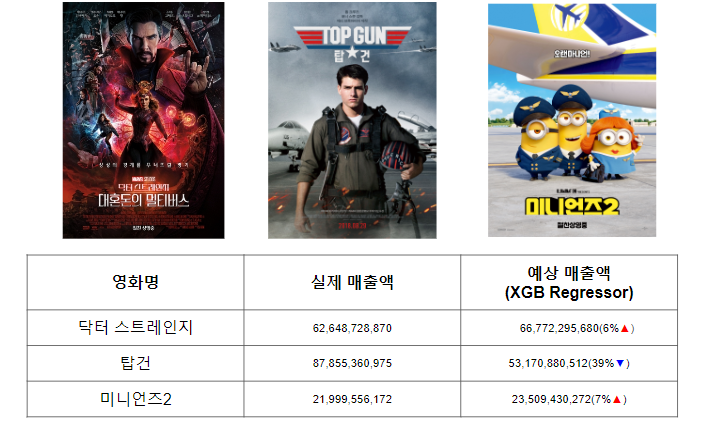
- 현재 머신러닝이 학습한 데이터는 2007 – 2021년 까지의 데이터
- 머신러닝 입장에서는 2022년 개봉된 닥터스트레인지, 탑건, 미니언즈2 는 미래에 개봉될 영화
봉준호 감독이 ‘자전차왕 엄복동’을 감독했다면 매출액에 변화가 있을까?
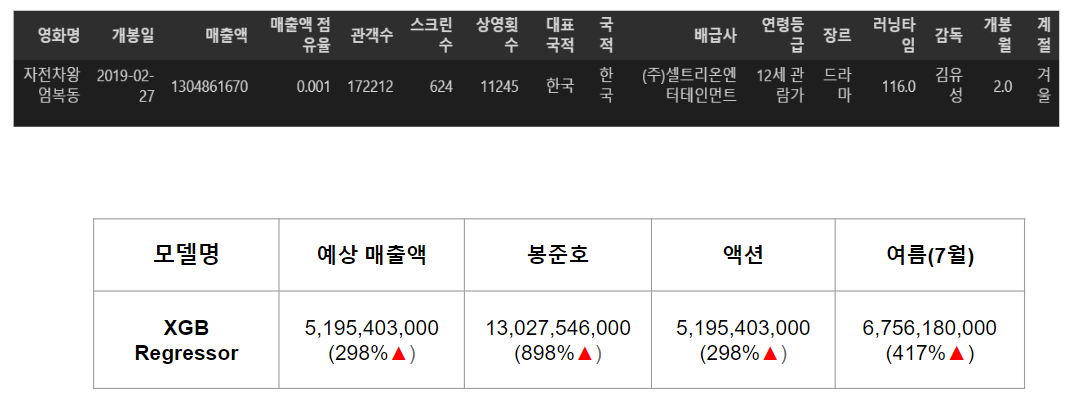
- 아무런 조작없이 단순히 머신러닝 모델이 예측한 엄복동의 예상 매출액은 51억 가량으로, 약 300% 높은 수치의 영화 매출액을 예측.
- 아마 머신 러닝도 이렇게 까지 엄복동이 흥행에 참패 할거라고는 생각하지 못했나봄
- 두번째 시도로, 다른 변수를 그대로 두고, 영화 감독을 봉준호로 변경시켜 주었을 때는 실제 영화 매출액 대비 약 900% 높게, 아주 큰 폭으로 영화 매출액 상승을 예언
- 장르만 액션으로 바꿨을 때는 전혀 영향이 없는 것으로 확인
- 계절만 여름으로 바꿨을 때 역시 매출액이 상승
- 여러 features 중에서 계절, 개봉월, 장르 보다’ 감독’을 바꿨을때, 가장 큰 폭으로 영화 매출액이 상승
머신러닝 프로젝트를 마치며..
작성 예정~

THEO's velog