
데이터 페치 이원화의 이유: Authorization을 포함한 데이터요청이냐 아니냐
All That Arsenal 프로젝트에서는 비즈니스 로직에 따라 데이터 페치 방식을 두 가지로 분리하여 효율성을 높였습니다. Next.js 의 데이터 페치 방식 중 하나인 서버 컴포넌트에서의 페치와 클라이언트 컴포넌트에서의 TanStack Query 를 조합하여 사용했습니다
Next.js Fetch를 단독으로 사용시 나타나는 문제점
Next.js의 기본 데이터 페치 방식은 서버 캐시를 사용하여 모든 데이터 요청의 응답을 캐시합니다. 이 방식은 개인화된 요청에서도 모든 사용자에게 동일한 응답이 반환되는 문제가 발생했습니다.
또한 개인적인 요청과 그에 대한 응답까지 서버컴포넌트에서 캐싱한다는 것은 서버자원을 낭비하는 것이라고 생각했습니다.
그래서 개인화된 요청과 공통된 요청을 구분하여 데이터 페치 방식을 이원화했습니다
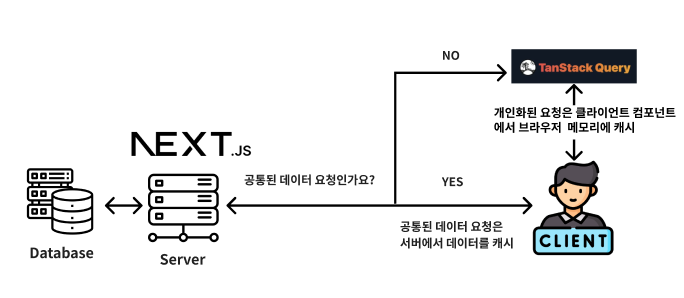
1-1) Authorization을 포함한 데이터 요청: TanStack Query
Authorization을 포함한 데이터 요청을 처리하기 위해 TanStack Query를 사용했습니다. Next.js fetch에서 no-store 옵션을 설정하여 캐싱을 방지할 수도 있었지만, 이 경우 새로 고침이나 캐시 만료 시마다 API 호출이 발생하여 비용이 증가하는 문제가 있었습니다. 이를 해결하기 위해, 개인화된 요청은 클라이언트 컴포넌트에서 TanStack Query로 브라우저 메모리에 캐시하고, queryKey와 staleTime으로 캐시를 관리했습니다. 검색 엔진 노출이 필요 없는 개인화된 요청은 클라이언트 컴포넌트에서 처리하여 서버 부하를 줄였습니다.
본 프로젝트에서는 선수별 댓글 및 즐겨찾기와 같은 Authorization이 필요한 요청을 클라이언트 컴포넌트에서 TanStack Query를 사용하여 관리했습니다.
1-2) 공통된 요청: Next.js Fetch
개인화되지 않은 데이터는 Next.js 서버 컴포넌트에서 Next.js fetch를 사용하여 관리했습니다. 서버 컴포넌트(RSC, React Server Component)는 데이터 페치 로직을 서버로 옮겨 데이터베이스와 더 가깝게 처리할 수 있는 장점이 있습니다. Next.js 서버 컴포넌트에서 데이터를 페치하면, 서버 요청과 배포 전반에 걸쳐 캐싱된 데이터를 유지할 수 있습니다. 이를 통해, 개인화되지 않은 정적 데이터를 효율적으로 캐싱하여 사용할 수 있습니다. 본 프로젝트에서는 선수 정보, 경기 일정 등의 개인화되지 않은 정적 데이터를 효율적으로 캐싱하여 사용하기 위해 Next.js의 서버 컴포넌트에서 data fetch를 하여 관리하였습니다.
