
6달 늦은 15GG 후기
첫 개발기를 작성한 10월초 부터 12월 말까지 쉴 시간도 없이 15GG에 투자했다. 개발을 하면서 틈틈이 만났던 이슈를 처리하는 과정을 기록하려고 마음은 열심히 먹었는데.. 잘 되지는 않았다.
결론부터 말하자면 15GG를 나름 성공적으로 마무리 했다. 각종 교내 대회에서 상을 싹쓸이 할 정도의 퀄리티가 나왔다고 개인적으로 생각했었는데, 심사위원인 학교 교수님들은 게임 도메인을 별로 좋아하지 않는다. 심지어는 창의학기제 최종 결과 발표를 하러 갔는데 "이게 왜 필요한거지? E-스포츠에도 토토가 있나?" 라는 질문도 들어왔다..
어찌됐던 왜 이제와서 이걸 쓰냐? 하면 SW마에스트로에서 내 PR을 하면서 15GG 소개를 엄청 많이 했는데, 이걸 소개할 때 마다 많은 관심들을 보여주셨기 때문이다. 그래서 조금이라도 기억이 남아있을 때 프로젝트를 어떻게 진행해갔는지 기록하려고 한다!
최종 프로젝트 구조
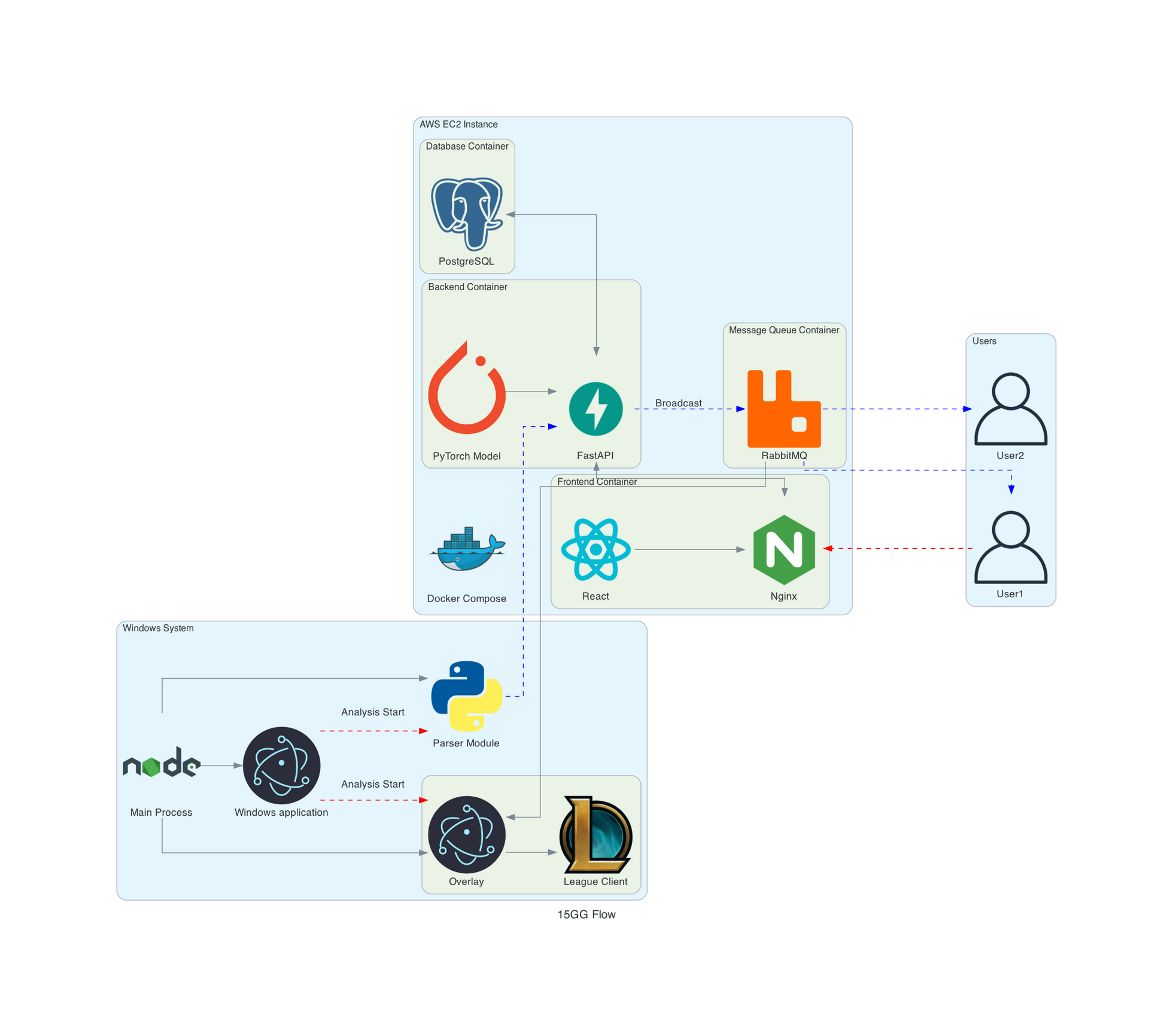
이때 고민했던 내용들은 CI/CD 빼고는 거의 다 적용했다. 크게 새롭게 적용한 기술들과 적용한 이유는 다음과 같다.
- 웹소켓
- 실시간으로 데이터가 오가는 파이프라인에서 소켓 통신이 꼭 필요했다.
- 소켓통신으로 롤 클라이언트를 킨 데스크톱에서 서버로 1초에 한번씩 데이터를 파싱하고 전처리해서 서버로 전송한다.
- 서버에서 AI 모델로 예측한 승률값이 포함된 데이터를 웹과 오버레이에서 소켓통신으로 받아본다.
- 메세지큐
- 롤 클라이언트에서 받아온 데이터를 여러 사용자들에게 동시에 실시간으로 보여주는 과정에서 필요했다.
- Kafka를 쓸 정도의 규모있는 데이터를 쓸게 아니라고 판단해서 RabbitMQ를 간단하게 적용했다.
- Docker
- 서버 구조가 꽤나 복잡해졌다. 백엔드 API, DB, MQ, 프론트 앱 등등 많아졌는데, 이 모든걸 따로 따로 관리하는건 말이 안된다고 생각해서 사용했다.
- DockerFile로 15GG의 여러 서비스들을 관리하도록 했다.
내가 한 일들
일단 기본적으로 팀의 전반적인 기술을 리드했다. 주간 회의에서 팀원들의 코드리뷰(대부분은 회의하며 라이브로 함) 를 해주긴 했지만 마감이 임박할 즈음에는 여유가 없어서 끝까지 이어지진 못했다.
DataNashor
우선, 데이터셋을 파싱하는 스크립트부터 짜기 시작했다. 지금 생각해봐도 이름은 잘 지은 것 같다 ㅋㅋㅋㅋ. 가장 처음 롤 클라이언트를 켜서 리플레이 파일에서 데이터를 받아오는 것부터 연구하기 시작했고, 다행히도 라이엇에서 제공하는 API가 있었다. 롤 게임이 시작되면 localhost에 API가 열리는데, 여기에 요청을 보내서 현재 진행중인 게임의 정보를 일부 얻어올 수 있었다! 롤을 시작한지 10년만에 처음 안 사실.. 아무튼 데이터를 받아올 수 있는건 OK, 근데 데이터셋을 수집하려면 이걸 모두 자동화 해야했다. 그래서 여러 오픈소스들을 참고해서 롤 클라이언트 실행하기, 클라이언트에서 리플레이 파일 다운받기, 리플레이 파일 실행하기, 실행한 뒤에 배속을 8배속으로 높히기를 전부 자동화할 수 있었다. 이 글을 보는 사람중에 롤 클라이언트에 관련해서 프로젝트를 한다면 DataNashor를 참고하면 좀 도움이 될지도? 아무튼 전부 개발한 뒤에 이와 비슷한 작업을 하는 사람들을 위해서 오픈소스로 공개하고, 패키지화 해서 PyPI에 올렸다. pip install DataNashor를 하면 쉽게 사용할 수 있다는 사실! 현재 유지보수는 안하고 있긴 한데, 현재 패치버전을 잘 명시해주면 데이터를 잘 파싱할 수 있을 것 같다!
그래서 실제로 이걸 갖고 2주동안 과실에서 쓸 수 있는 데스크톱들을 긁어모아 9대를 풀가동해서 29517경기의 데이터를 수집했다. JSON으로만 약 20GB 정도의 분량이였는데, 이 경험도 진짜 재밌었다. 가끔 컴퓨터 죽으면 새벽에 과실 달려가서 다시 살려놓고.. 추억보정 된듯ㅋㅋ
데이터 파이프라인 구성
위의 프로젝트 구조를 잘 보면 데이터가 결국 롤 클라이언트에서 시작되어 결국 엔드유저에게 도달하기까지 엄청나게 많은 과정을 거친다. 우선 롤을 실행하고 있는 클라이언트에서 시작해서 데이터를 1차 가공하여 웹소켓을 통해 백엔드 서버로 전송한다. 백엔드 서버에서는 데이터를 모아 시계열 데이터의 형태로 변환하고 (5분 단위의 time windowing 전략을 썼다) 이를 AI모델에 통과시킨다. 그렇게 나온 현재 시점의 승률 데이터는 메세지큐 서버로 전송하고, 메세지큐에서는 현재 연결된 모든 consumer에게 broadcasting 된다. 이중 하나는 필수적으로 롤 클라이언트 위에 띄워진 오버레이가 있고, 또 다른 하나는 웹앱에서 발행한 OTP화면이 자동으로 분석창으로 넘어간다.
이 전반적인 구조를 설계하고 파이프라인을 구성하는 것이 솔직히 시작하기 전에는 엄청 챌린징 했는데, 막상 하고 나니까 할만하다고 생각했다. 메세지큐가 상당히 무거워서 우리의 프리티어 ec2 인스턴스로는 버티기 힘들어서 4~5명 이상이 동시에 분석을 요청하기 시작하면 서버가 죽기 십상이였는데, 최적화하는 작업을 해보면 재밌을 것 같다.
AI 모델
사실 이 프로젝트의 가장 알멩이(?)인 AI 모델링을 했다. 나는 2022년 1학기부터 기계학습 수업을 처음 듣고, 15GG와 인공지능 수업을 같이 병행하고 있었다. 지금까지는 회귀나 분류 문제들을 간단한 데이터 형식을 위주로 다루고, 이미지 형식의 데이터를 다루기 시작하던 때였다. 이 상황에서 우리가 모은 데이터는 매우 난해했다. 게임 시작부터 끝날 때 까지 지표의 변화량이 시간별로 찍히고, 결국 그 경기가 블루팀이 승리했는지, 레드팀이 승리했는지 밖에 알 수 없었기 때문이다. 설상가상으로 나는 AI 파트만 맡은 것이 아니라 다른 작업들도 많았고, 학습데이터가 준비된 시점도 프로젝트 마감 1달 전이였다.
우리가 했던 가장 큰 고민은 "지금까지 푼 문제들은 정답이 정해져있었는데, 이건 정답이 정해져있지 않아서 이걸 어떻게 해결해야하느냐?" 였다. 생각해보자. 0분 시점에 아무 일도 일어나지 않았을 때에도 블루팀이 승리했다면 라벨이 블루팀 승리인데, 0분부터 AI가 블루팀이 승리한다고 하면 알면 말이 안되지 않나? 이걸 알 수 있으면 로또 예측기부터 만들어야겠다.
결론은 그냥 학습 시키는거였다. 이게 처음에는 이상했는데, 모델에 학습데이터를 집어넣을 때 블루팀 승리와 레드팀 승리를 똑같은 비율로 집어넣으면 게임이 시작하자 마자 0분일 시점에는 0.5로 예측하는 것이 당연했다. 왜냐면 10000경기는 답이 0이고 10000경기는 답이 1이면 이 모델은 0.5로 예측할꺼기 때문이다! 아무튼 그러면서 어느정도 지표의 변화가 생기면 0혹은 1쪽으로 값이 치우져질 것이고, 이를 팀의 승률이라고 해석해도 되는 것이였다. 이걸 깨닫기까지가 엄청 오래 걸렸다. 우리처럼 실시간으로 데이터를 집어넣고 값을 뽑아온 논문들이 많이 없었고, 있어도 해석하기가 좀 어려웠지만.. 결국 해냈다!
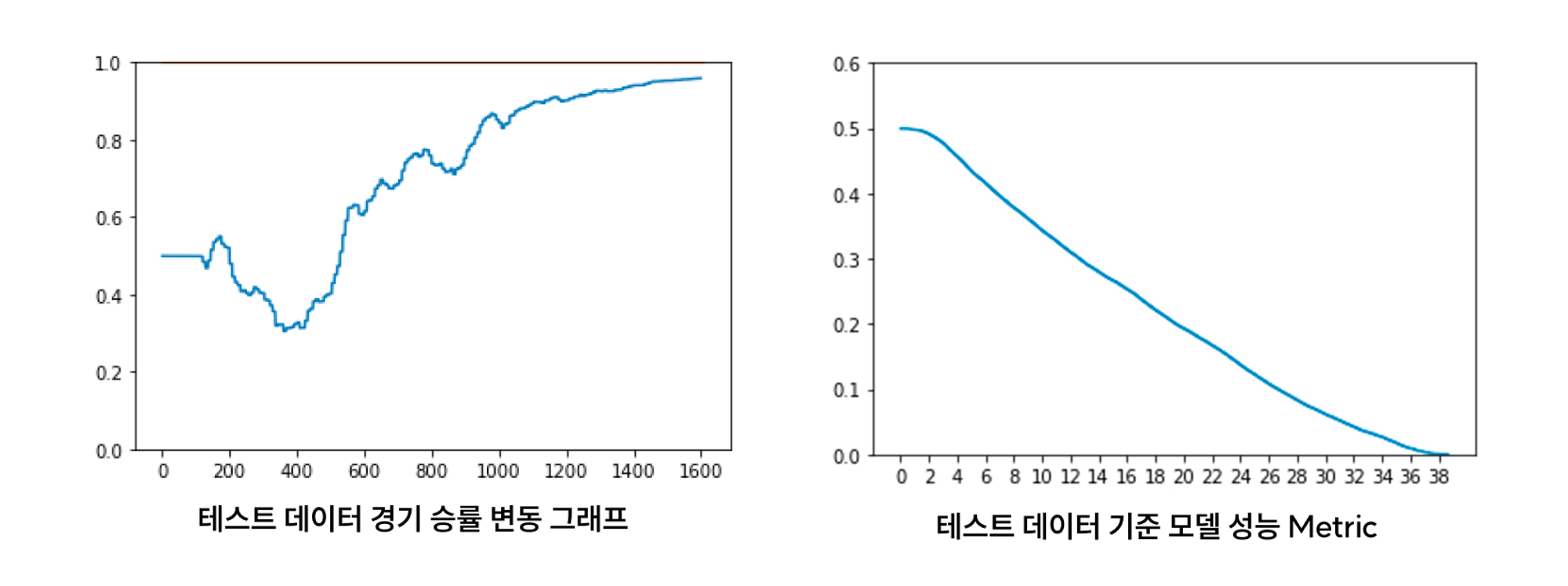
이게 우리 모델의 지표인데, 왼쪽은 한 경기에 대한 승률이 변동하는 그래프다. 앞서 말했듯이 0초일 때는 0.5로 시작한다. 100초쯤부터 양쪽 팀이 주고 받다가, 400초 쯤에 레드팀이 점점 역전을 하더니 그대로 게임을 굳혔다. (0이 블루팀, 1이 레드팀 승리이다)
오른쪽 그래프가 우리 모델의 성능을 평가한 그래프다. 분 단위로 모델이 얼마나 승리하는 팀을 잘 예측하는지 보여주는 것인데, 0분일 때는 당연히 0.5이기 때문에 틀릴 확률도 50%이다. 13분 정도 지나면 모델이 조금이라도 우세하다고 예측하는 팀이 70% 확률로 승리하고 있고, 25분정도 지나면 88% 확률로 이기는 팀을 맞추고 있다. 인상적인 점은 우리 데이터에는 용이나 드래곤과 같은 오브젝트에 대한 직접적인 정보가 없음에도 불구하고, 꽤나 잘 맞추고 있는 것이다!
우리는 모델을 GRU모델을 사용했는데, 시간이 조금 더 주어졌다면 Transformer 모델을 써봤을 것 같다.. 특히 요즘 GPT가 너무너무 핫한데, 제일 성능 좋은 최신 모델을 사용하지 못한게 좀 아쉽다. 이때 몇 개 시도를 해보다가 GRU가 제대로 학습이 돼서 그냥 다른 모델을 찾기보단 GRU 모델을 튜닝하기 시작했다..
학습이 제대로 안되던 시절..
해결 못한 문제
이걸 하면서 "할 수는 있는데 시간상 일단 하지 말자" 라고 한 것들이 몇개 있는데 (Transformer 모델이라던지..) 해결을 못한 문제는 딱 하나 있었다.
Docker 컨테이너로 백엔드와 프론트를 하나의 인스턴스 안에서 관리를 해서 Docker 내부 네트워크로 서로 데이터를 주고받게 구조를 설계했는데, 계속 CORS 오류가 났었다. 분명 백엔드에서는 CORS를 Whitelist 처리를 했는데도 그랬다. 그래서 열심히 검색한 결과 이 Stack Overflow글을 찾았다. 보안상 이유로 내부 네트워크를 통해서 통신을 하기 위해서는 HTTPS 연결을 꼭 사용해야한다고 하는 것이였다. 그래서 정말 마음에는 안들지만 프론트에서 백엔드의 외부 ip로 요청을 하게 임시방편으로 해결했었는데 (같은 집안에서 말하면 되는데 굳이 카톡으로 하는 느낌?), 이 뒤의 과정을 해보지 않아서 잘 모르겠다. HTTPS를 적용해서 확실히 해결을 해봤어야 했는데.. 이 뒤의 과정을 해보지 못해서 이것도 조금 아쉬웠다.
결론
지금은 추억보정이 많이 된 상태지만 이 프로젝트가 끝날 때는 번아웃이 와서 아무것도 하기 싫었다. 리드미 정리나, 이런 회고를 쓸 생각도 안했다. 그래도 확실한건 지금까지 한 프로젝트들 중에서 앞으로도 제일 기억에 남을 것 같다. 내가 제일 좋아하는 도메인의 프로젝트를 내가 주도적으로 이끌어가는 경험은 정말 소중했던 것 같다.
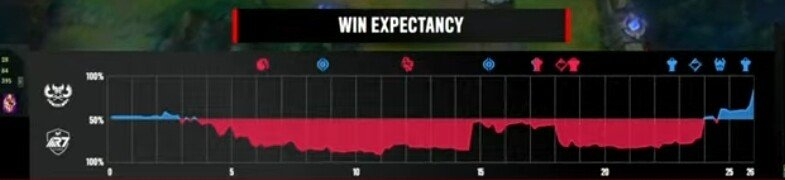
끝으로 2023년 Mid Season Invitational (대충 큰 국제대회)에서 우리가 하고싶었던 것이 실제로 등장했다. 역시.. 인생은 타이밍이다!

7개의 댓글

안녕하세요! 롤 관련 웹사이트를 개발하려고 찾아보던 중에 이 벨로그를 발견했는데 너무 유용하네요.. 정말정말 너무 감사합니다.. 혹시 개발하면서 질문이 생기면 질문 드려도 될까요??

안녕하세요 궁금한게 있어서 여쭤보려고 글 남깁니다ㅠㅠ
인공지능 연습을 위해서 롤 API로 데이터를 가져와서 이것저것 해보고 있는데, 이번에 롤드컵에서 AWS에서 XGBOOST로 실시간 승률 예측을 하는걸보고 따라해보려다가 관련 궁금한게 있어서 들어왔습니다..
-
시계열 분석으로 할 경우, 일정한 크기로 시퀀셜 데이터를 넣어줄텐데.. 실시간 타임라인 데이터들을 input으로 준걸까요? 이 때 게임 길이가 30분인경우랑 1분인 경우는 데이터의 길이가 달라서 못넣을텐데 패딩으로 다 0값으로 데이터를 넣어주셨던걸까요?
-
근데 생각을 해보면,, 각 타임라인마다의 데이터를 학습시키는건 너무 많은 데이터들이 있고 시간이 달라서 차원들이 다를텐데,, 그냥 매치데이터 값으로만 학습을 한걸까요?
-
제 생각에는 매치데이터값을 이용해서 win, lose 나눠서 몇가지 지표를 이용해서 학습시키셨을것 같은데.. 그렇게 되면 실시간 예측은 타임라인을 이용해서 그 지표로 환산한다음 input으로 주는걸까요? (혹시 어떤 지표들을 이용하셨는지 공유가 가능할까요...)
-
보통 이길 확률이면.. red값을 주고 이길지 질지 확률을 구하고 그걸 그냥 확률로 표시하는거...죠? 각 red blue 팀별로 구하시는게 아니라.
뭔가 애매하게 알아서하다보니 막히는것 같은데.. 너무 많이 물어봤지만.. 가르쳐주시면 감사하겠습니다ㅠㅠ
+. 롤 리플레이 화면에 승률을 띄워놓으셨던데,, 이건 어떻게 하신걸까요?

재미잇게 읽었어요