Trie Structure
Trie란
Trie 자료구조는 접두사 트리라고도 하며 노드 단위로 문자를 관리하고 루트에서 노드까지 경로를 문자열로 표현하는 방법을 말합니다. 이진 검색 트리의 검색 시간 복잡도인 O(m lon n)에 비해 검색 시간 복잡도가 O(m)입니다.(이 때 m은 문자열의 길이, n은 노드 수 입니다.)
Trie 자료 구조는 문자열의 대규모 컬렉션을 검색하고 저장하는 상황에서 뛰어나지만, 메모리 공간이 많이 필요하다는 등 신경써야 할 부분이 있습니다.
Trie 장점
- 문자열을 검색하는게 빠릅니다.
- 공통 접두사가 많은 경우 효율적으로 관리할 수 있습니다.
Trie 단점
- 노드로 표현되는 키가 작은 상황에서 값을 검색하는 건 효율적이지 않습니다. 즉, 공통 접두사가 적은 상황은 적합하지 않습니다.
- 복잡한 조건으로 검색할 때, 구현이 어려워집니다.
- 많은 메모리 공간을 필요로 합니다.
Trie Structure 메커니즘
입력
hello 단어를 입력하게 되면 ROOT 부터 문자 하나씩 Node 단위로 차례대로 저장하게 됩니다.

Node 는 현재 저장하는 문자와 뒤에 이어질 문자들을 가지게 되며, 마지막 문자에 문자열의 끝을 알리는 flag를 추가합니다.
class Node {
private String string;
private Map<String, Node> nodes;
private boolean flag;
}hi 입력하게 된다면 문자가 h 인 Node에서 새로운 문자가 추가되게 됩니다.
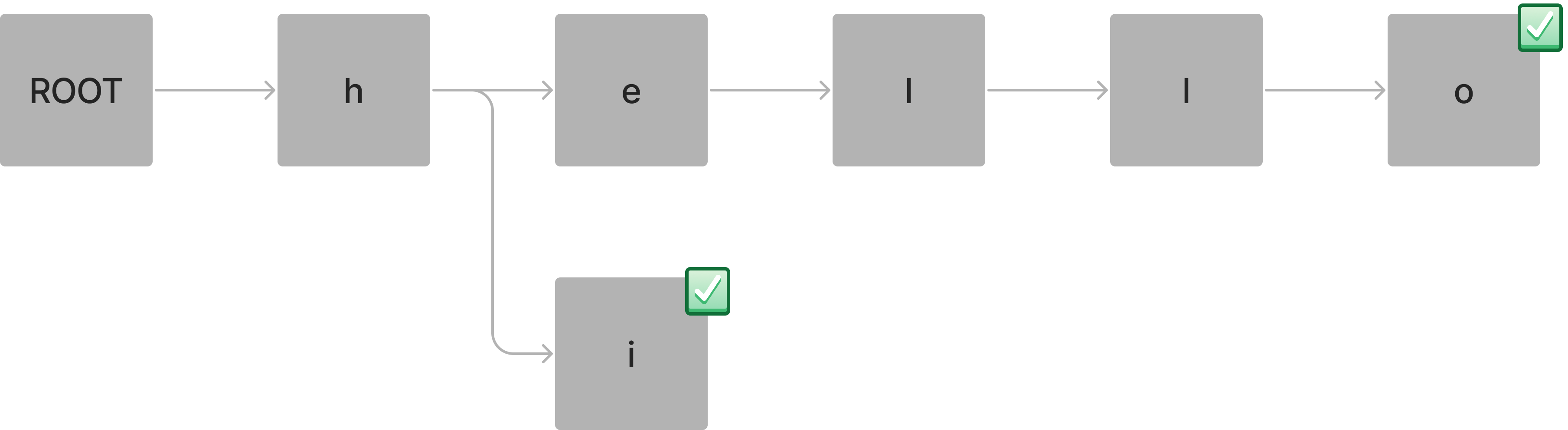
검색
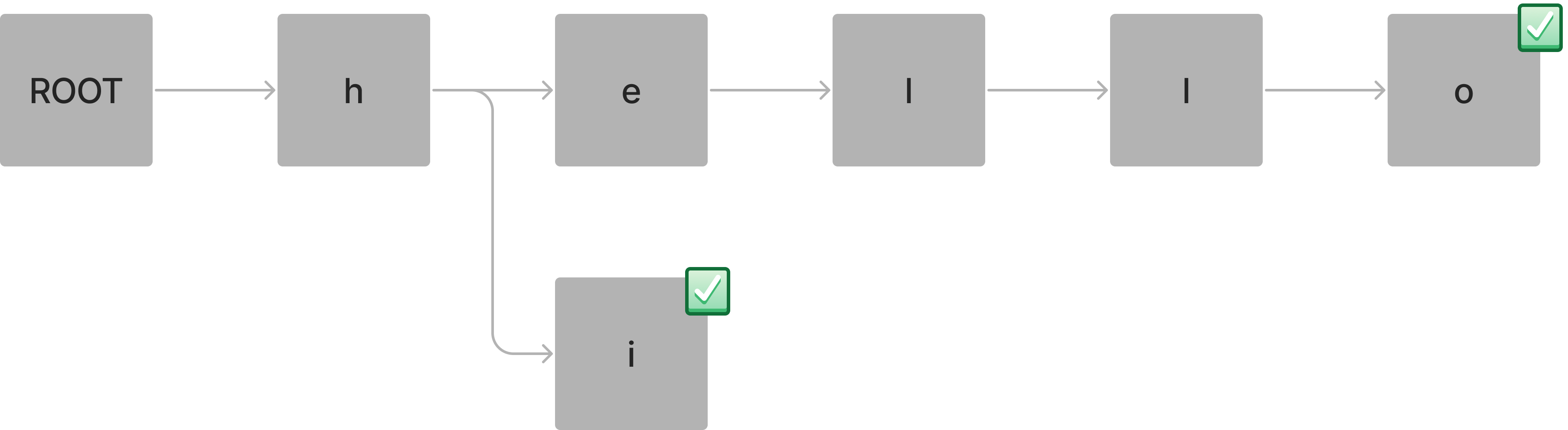
단어를 검색할 때 문자 하나씩 포함되어 있는지 확인하면서 마지막 flag가 true인지 검사하게 됩니다. hello 단어를 검색할 때는 true라는 값을 가질 수 있습니다.
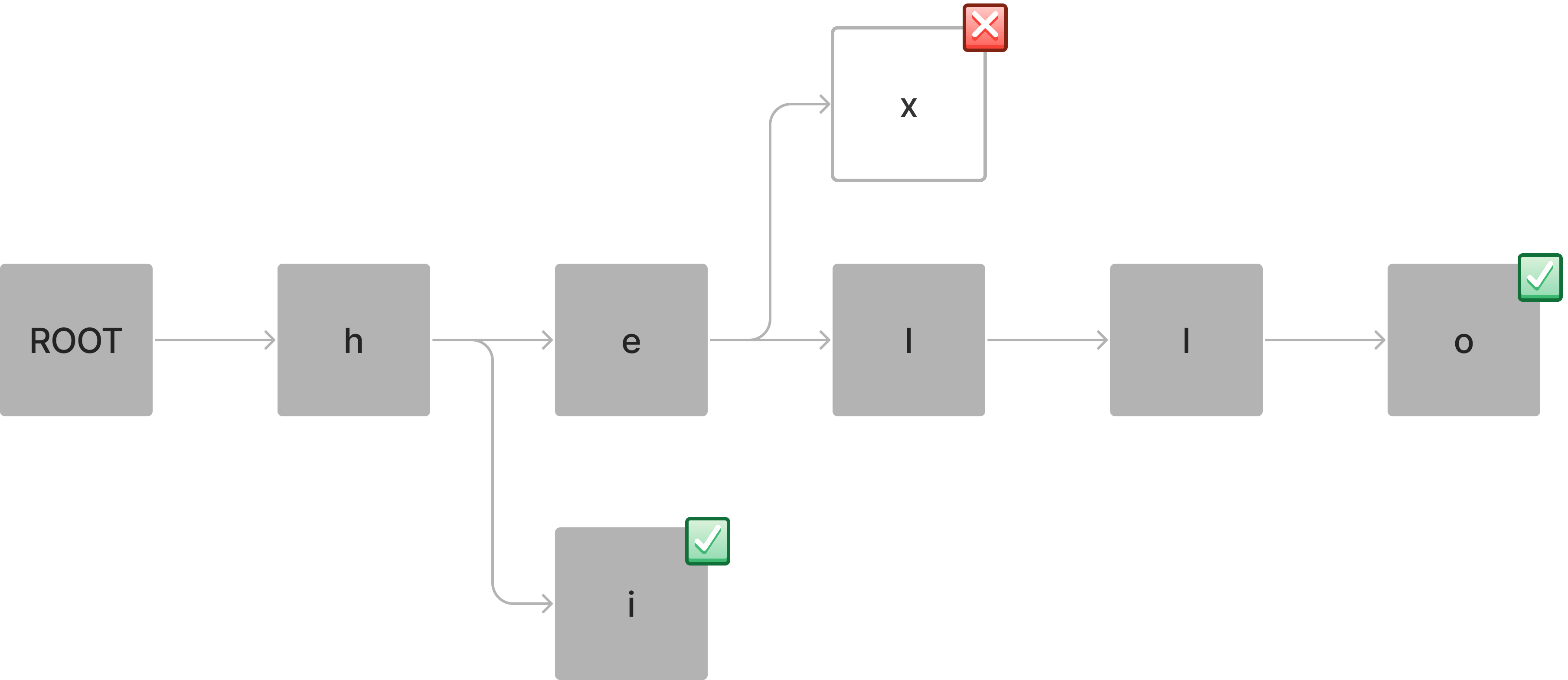
저장하지 않는 단어 hex를 검색한다면 e 문자를 가진 Node에서 x 값을 가진 Node를 검색할 수 없습니다.
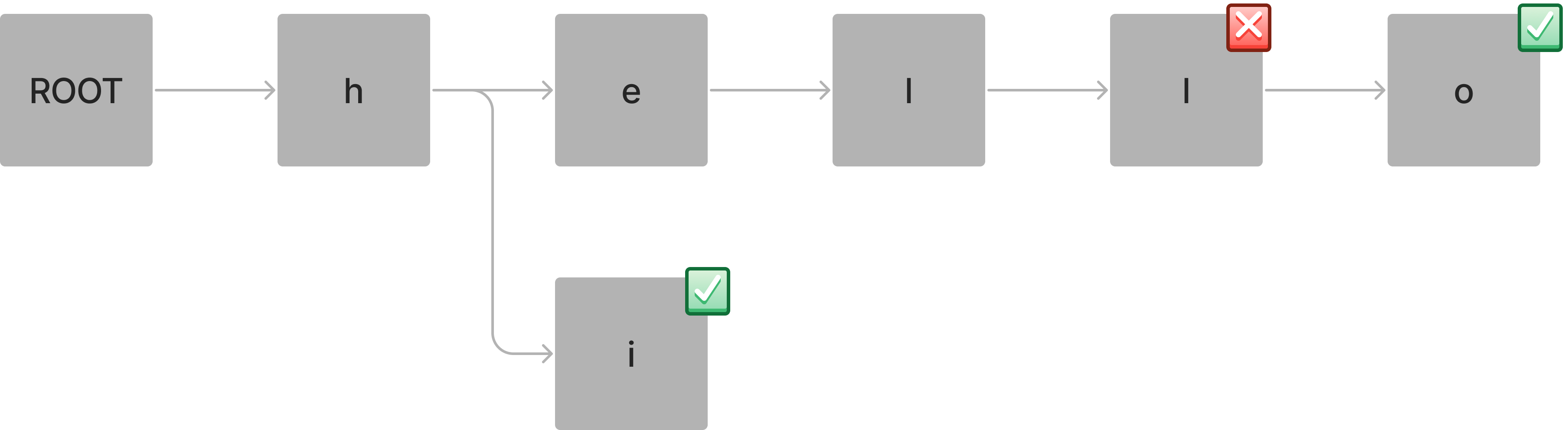
hell 단어를 검색하게 될 때는 검색이 가능하지만 flag가 false이기 때문에 저장된 단어가 아니라는 것을 파악할 수 있습니다.
구현 코드
자바에서 Trie 자료구조를 구현했습니다.
public class Trie {
private Node root;
public Trie() {
root = new Node(null);
}
class Node {
private String string;
private Map<String, Node> nodes;
private boolean flag;
public Node(String string) {
this.string = string;
this.nodes = new HashMap<>();
this.isStrings = false;
}
}
public void add(String word) {
String[] splitWord = word.split("");
Node node = root;
for (String s : splitWord) {
if (!node.nodes.containsKey(s)) {
node.nodes.put(s, new Node(s));
}
node = node.nodes.get(s);
}
node.isStrings = true;
}
public boolean search(String word) {
String[] splitWord = word.split("");
Node node = root;
for (String s : splitWord) {
if (!node.nodes.containsKey(s)) {
return false;
}
node = node.nodes.get(s);
}
return node.flag;
}
}Trie Structure 활용
자동 완성
접두사부터 입력이 되는 입력창에서 쉽게 구현이 가능합니다. 접두사 끝에 도달하면 트리를 재귀적으로 순회하고 해당 노드 아래에 있는 단어들을 목록에 추가하면 쉽게 구현이 가능합니다.
IP 라우팅
Tre 자료 구조를 활용해 IP 주소 라우팅 테이블을 효율적으로 저장하고 검색하는 데 사용할 수 있었습니다. 라우팅 테이블에 저장된 많은 IP 주소를 Trie 자료구조를 활용하면 쉽게 관리가 가능합니다.
Trie Structure 문제
마지막으로
Trie 자료구조는 검색과 삽입이 빠른 자료구조이며, 추가한 데이터가 많은 경우, 일반적인 검색보다 빠른 속도를 보입니다. 반면 문자열의 길이가 길어지면 효율적이지 못한 자료구조이기 때문에 신중해서 사용할 필요가 있습니다.
입력의 특성과 Trie 자료구조 특성을 잘 살려 자동 완성 기능을 제공할 수 있습니다. 추가로 라우팅 테이블에 저장된 많은 IP 주소를 Trie 자료구조를 활용해 관리가 가능합니다.
