938. Range Sum of BST

low 이상 high 이하 사이에 있는 모든 노드들을 더하는 문제다.
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {
}
TreeNode(int val) {
this.val = val;
}
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
public class Solution {
public int rangeSumBST(TreeNode root, int low, int high) {
if (root == null) {
return 0;
}
int currentVal = (root.val >= low && root.val <= high) ? root.val : 0;
int leftSum = rangeSumBST(root.left, low, high);
int rightSum = rangeSumBST(root.right, low, high);
return currentVal + leftSum + rightSum;
}
}
class App {
public static void main(String[] args) {
Solution sol = new Solution();
// 트리 노드 생성
TreeNode root = new TreeNode(10);
root.left = new TreeNode(5, new TreeNode(3), new TreeNode(7));
root.right = new TreeNode(15, null, new TreeNode(18));
int low = 7;
int high = 15;
System.out.println(sol.rangeSumBST(root, low, high)); // 32
}
}-
재귀함수를 통해 dfs를 구현한다.
-
기본 조건 확인: 먼저, 현재 노드 root가 null인지 확인한다.
만약 root가 null이라면, 더 이상 탐색할 노드가 없으므로, 0을 반환한다. -
현재 노드 값 검사: 현재 노드 root의 값이 주어진 범위 [low, high]에 속하는지 확인한다. 만약 속한다면, 현재 노드의 값 root.val을 currentVal에 할당한다. 속하지 않는다면, currentVal은 0이 된다.
-
왼쪽 서브트리 탐색: 현재 노드의 왼쪽 자식 노드 root.left를 시작으로, 같은 함수 rangeSumBST를 재귀적으로 호출하여, 왼쪽 서브트리에서 주어진 범위에 속하는 노드들의 합 leftSum을 계산한다.
-
오른쪽 서브트리 탐색: 현재 노드의 오른쪽 자식 노드 root.right를 시작으로, 같은 함수 rangeSumBST를 재귀적으로 호출하여, 오른쪽 서브트리에서 주어진 범위에 속하는 노드들의 합 rightSum을 계산한다.
-
합 반환: 마지막으로, 현재 노드의 값 currentVal과 왼쪽 서브트리의 합 leftSum, 오른쪽 서브트리의 합 rightSum을 모두 더한 값을 반환한다.
-
루트 노드(10): 루트 노드의 값 10은 범위 내에 있으므로 currentVal은 10이 된다.그리고 함수는 왼쪽 자식(5)과 오른쪽 자식(15)에 대해 재귀적으로 호출된다.
-
왼쪽 서브트리 처리 (노드 5): 노드 5는 범위 내에 있다. 따라서 currentVal은 5다. 왼쪽 자식(3)과 오른쪽 자식(7)에 대해서도 재귀적으로 함수를 호출한다.
-
노드 3: 범위 내에 있으므로 currentVal은 3이다. 왼쪽과 오른쪽 자식 모두 없으므로 여기서 더 이상의 재귀 호출은 없다.
-
노드 7: 범위 내에 있으므로 currentVal은 7이다. 왼쪽과 오른쪽 자식 모두 없으므로 여기서 더 이상의 재귀 호출은 없다.
-
오른쪽 서브트리 처리 (노드 15): 노드 5의 컨텍스트에서 벗어나 루트 노드 (10) 의 컨텍스트로 복귀한다(재귀호출). 노드 15는 범위 밖에 있으므로 currentVal은 0이다. 오른쪽 자식(18)에 대해 재귀적으로 함수를 호출한다.
-
노드 18: 범위 밖에 있으므로 currentVal은 0이다. 왼쪽과 오른쪽 자식 모두 없으므로 여기서 더 이상의 재귀 호출은 없다.
1379. Find a Corresponding Node of a Binary Tree in a Clone of That Tree

/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
TreeNode target, res;
public final TreeNode getTargetCopy(final TreeNode original,
final TreeNode cloned, final TreeNode target) {
this.target = target;
inorder(original, cloned);
return res;
}
// Placeholder for the traversal method
public void inorder(TreeNode orig, TreeNode cloned) {
if (orig != null) {
// Traversal -> Inorder(Left, Root, Right)
inorder(orig.left, cloned.left);
if (orig == target) {
res = cloned;
} else {
inorder(orig.right, cloned.right);
}
}
}
}inorder 메소드는 중위 순회를 구현한다.
중위 순회는 왼쪽 서브트리를 방문한 다음, 루트 노드를 처리하고, 마지막으로 오른쪽 서브트리를 방문하는 순서로 진행된다.
순회 중 원본 트리의 노드가 대상 노드와 동일한지 확인한다.
동일한 경우, 해당 순간의 복제된 트리의 노드(cloned)를 결과 변수 res에 할당한다.
이 방식으로 원본 트리의 노드와 동일한 위치에 있는 복제된 트리의 노드를 찾을 수 있다.
897. Increasing Order Search Tree
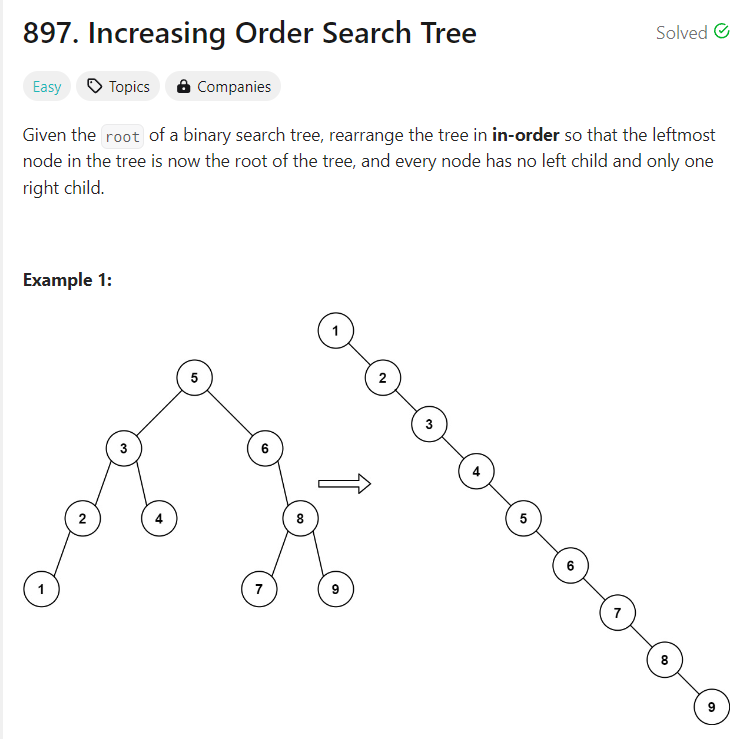
class Solution {
TreeNode newRoot = null;
public TreeNode increasingBST(TreeNode root) {
DFS(root);
return newRoot;
}
private void DFS(TreeNode root){
if(root == null){
return;
}
DFS(root.right);
newRoot = new TreeNode(root.val, null, newRoot);
DFS(root.left);
}좀 더 간단한 트리로 알아보자.
5
/ \
3 8
/ / \
2 11 12
/
1- DFS 시작 (노드 5에서 시작)
오른쪽 서브 트리로 이동: 노드 8 - 노드 8 처리
오른쪽 서브 트리로 이동: 노드 12 - 노드 12 처리
더 이상 오른쪽 자식이 없으므로, 연결 리스트에 12를 추가 - 노드 8로 돌아와서 연결 리스트에 8 추가
왼쪽 서브 트리로 이동: 노드 11 - 노드 11 처리
더 이상 자식이 없으므로, 연결 리스트에 11을 추가 - 노드 5로 돌아와서 연결 리스트에 5 추가
왼쪽 서브 트리로 이동: 노드 3 - 노드 3 처리
오른쪽 서브 트리가 없으므로, 연결 리스트에 3을 추가
왼쪽 서브 트리로 이동: 노드 2 - 노드 2 처리
오른쪽 서브 트리가 없으므로, 연결 리스트에 2를 추가
왼쪽 서브 트리로 이동: 노드 1 - 노드 1 처리
더 이상 자식이 없으므로, 연결 리스트에 1을 추가
최종 결과: 연결 리스트는 1 -> 2 -> 3 -> 5 -> 8 -> 11 -> 12 순서로 구성됨.
이를 좀더 풀어서 작성하면 아래와 같다.
class Solution {
public TreeNode increasingBST(TreeNode root) {
ArrayList<Integer> al = new ArrayList<>();
inorder(root, al);
return buildTree(al);
}
private TreeNode buildTree(ArrayList<Integer> al){
if(al.size() == 0) return null;
TreeNode root = new TreeNode(al.remove(0));
root.right = buildTree(al);
return root;
}
private void inorder(TreeNode root, ArrayList<Integer> al){
if(root == null) return;
inorder(root.left, al);
al.add(root.val);
inorder(root.right, al);
}
}104. Maximum Depth of Binary Tree
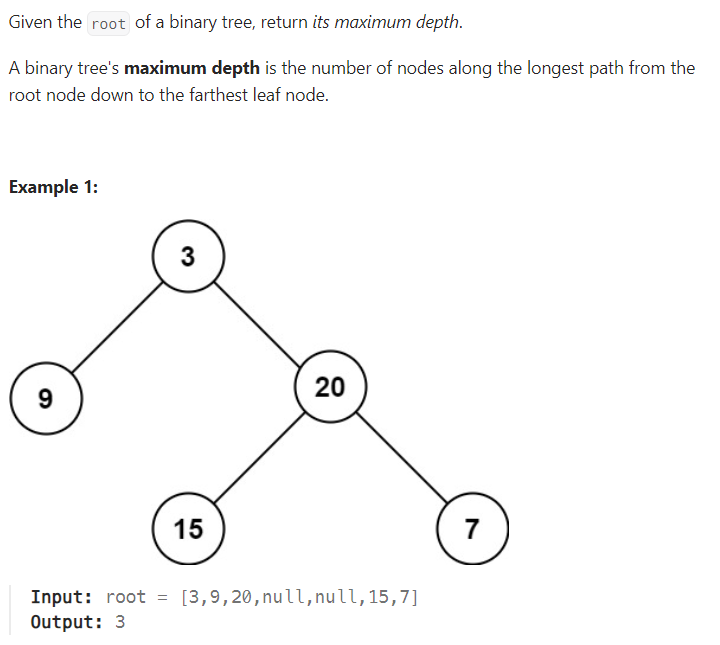
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
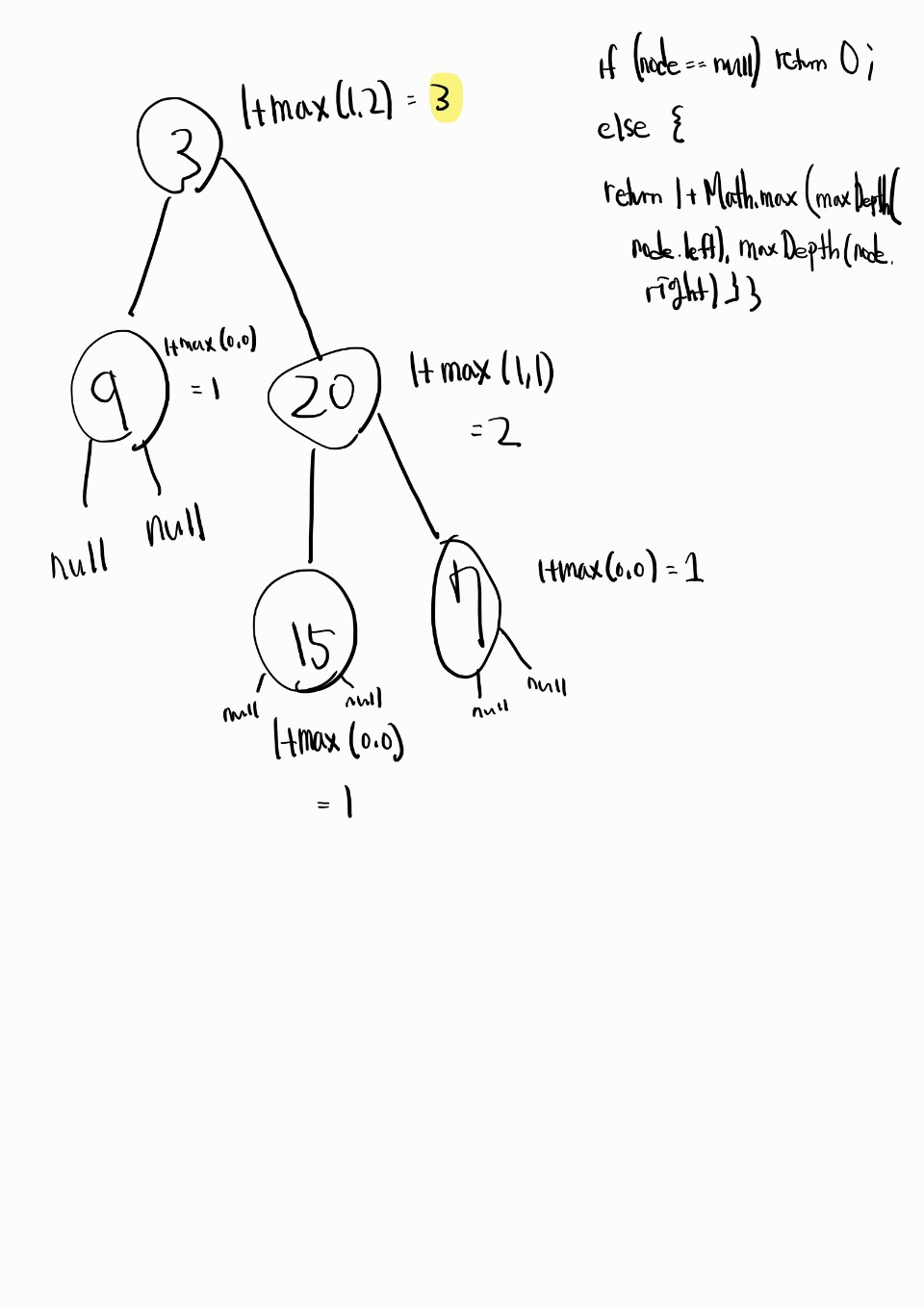
class Solution {
public int maxDepth(TreeNode root) {
if (root == null) return 0;
return 1 + (Math.max(maxDepth(root.left), maxDepth(root.right)));
}
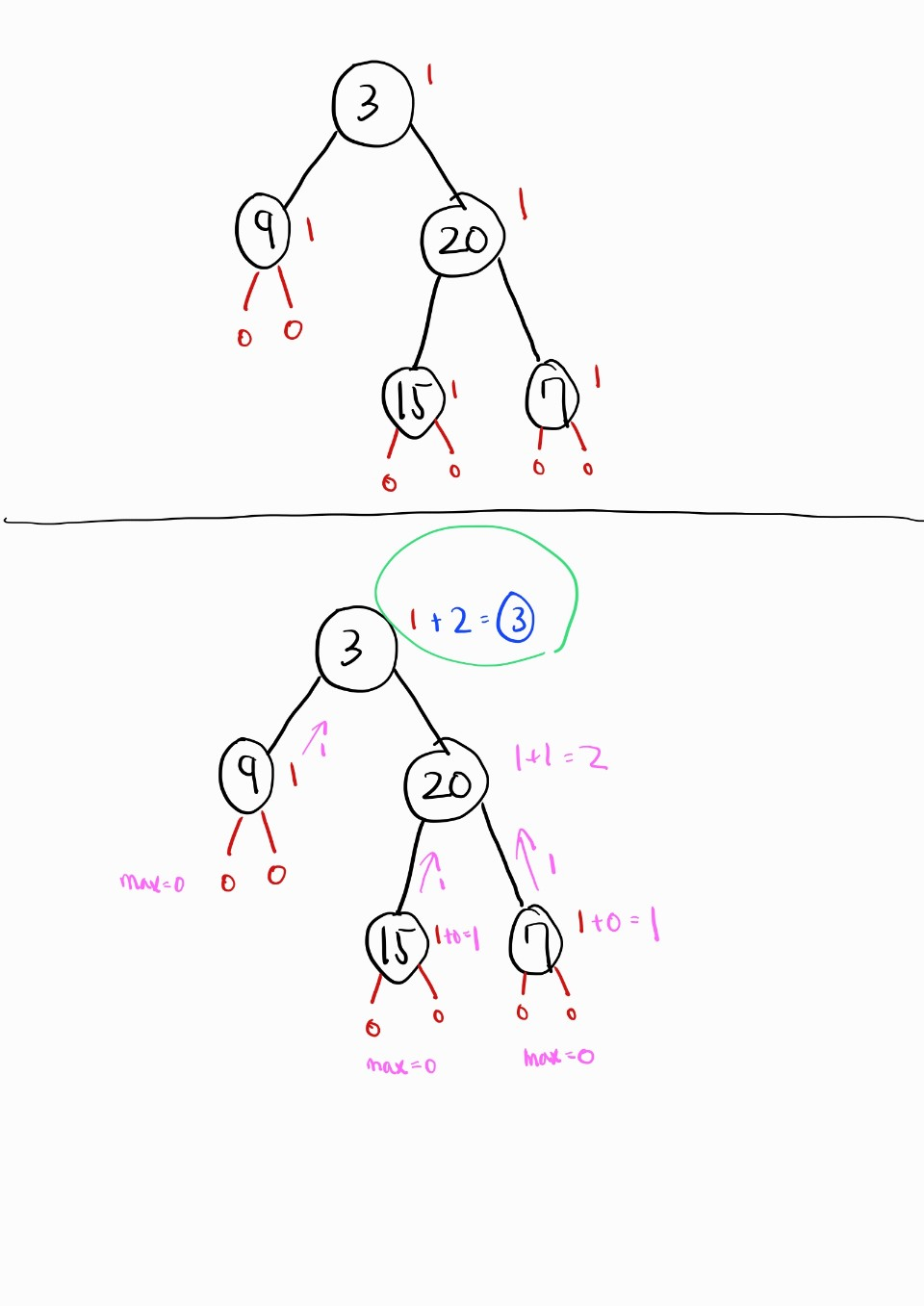
}초기 호출: maxDepth 함수는 트리의 루트 노드인 3으로 호출된다.
루트 노드 처리 (root = 3):
루트 노드가 null이 아니므로 else 블록이 실행된다.
왼쪽 자식 노드인 9와 오른쪽 자식 노드인 20에 대해 maxDepth(node.left)와 maxDepth(node.right)가 호출된다.
왼쪽 서브트리 처리 (node = 9):
노드 9는 리프 노드이므로 maxDepth(node.left)와 maxDepth(node.right)는 모두 0을 반환한다.
따라서 노드 9의 최대 깊이는 1 + Math.max(0, 0) = 1이다.
오른쪽 서브트리 처리 (node = 20):
노드 20에 대해 왼쪽 자식인 15와 오른쪽 자식인 7에 대해 maxDepth(node.left)와 maxDepth(node.right)가 호출된다.
노드 15 처리:
노드 15는 리프 노드이므로 maxDepth(null) 호출은 0을 반환하고, 최대 깊이는 1 + Math.max(0, 0) = 1이다.
노드 7 처리:
마찬가지로 노드 7도 리프 노드이므로 최대 깊이는 1 + Math.max(0, 0) = 1이다.
노드 20의 최대 깊이 계산:
노드 20의 왼쪽과 오른쪽 서브트리 모두 최대 깊이가 1이므로, 노드 20의 최대 깊이는 1 + Math.max(1, 1) = 2다.
루트 노드의 최대 깊이 계산:
루트 노드의 왼쪽 서브트리(노드 9)의 최대 깊이는 1이고, 오른쪽 서브트리(노드 20)의 최대 깊이는 2다.
따라서 루트 노드 3의 최대 깊이는 1 + Math.max(1, 2) = 3이다.
결론적으로, 이진 트리 [3,9,20,null,null,15,7]의 최대 깊이는 3으로 계산된다.
100. Same Tree

class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
if (p == null || q == null) {
// 같으면 true, 다르면 false를 반환한다.
return p == q;
}
/**
기본 조건 검사를 통과하면, 현재 p와 q의 val값을 비교하고,
동시에 isSameTree(p.left, q.left)와
isSameTree(p.right, q.right)를 호출하여 재귀적으로 왼쪽 자식 노드와
오른쪽 자식 노드를 비교한다.
*/
return p.val == q.val && isSameTree(p.left, q.left)
&& isSameTree(p.right, q.right);
}
}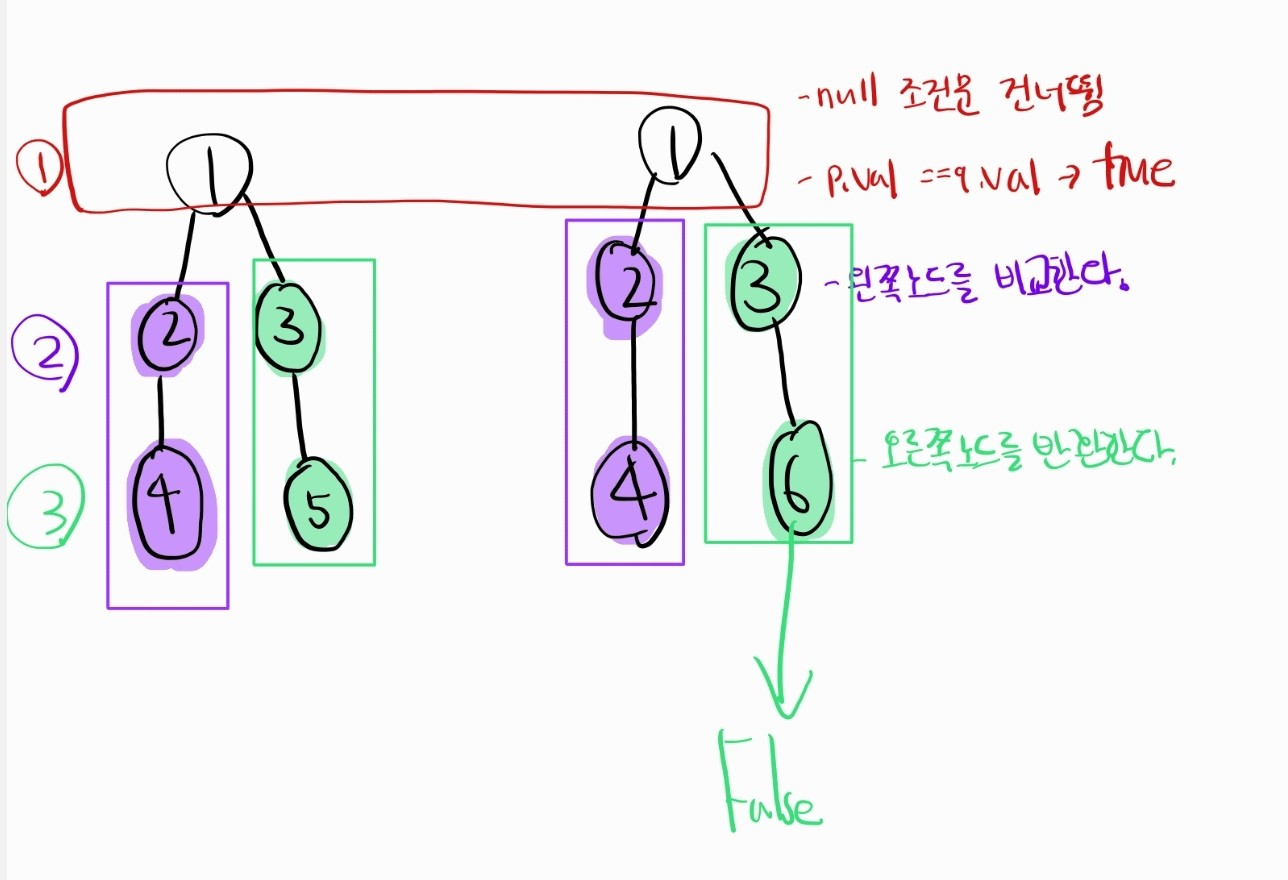
p = [1,2,3,4,5], q = [1,2,3,4,6] 이라고 가정하자.
-
초기 함수 호출: isSameTree(p,q)는 루트 노드 '1'의 값을 가진 두 트리 p,q를 대상으로 처음 호출한다.
-
null 체크: p 또는 q가 null 인지 체크한다. 만약 둘 중 하나라도 null이면, p와 q가 같은지(둘 다 null인지) 검사한다. 만약 같다면 true(null,null)를, 만약 다르다면 (ex. null, [1,2,3]) false를 반환한다.
cf. 자바에선 == 연산자가 반환하는 값은 두 변수의 비교결과에 따라 true 혹은 false를 반환한다. -
노드 값 비교: p.val == q.val을 통해 현재 노드의 값이 동일한지 확인한다.
맨처음엔 1 == 1이므로 true다. -
재귀 호출 - 왼쪽 자식: 왼쪽 자식노드를 비교한다. 이 과정에서 2번,3번을 다시 거친다. 왼쪽 자식노드는 모두 2다. '2'의 왼쪽 자식 노드 '4', '5'(p의 경우), '4', '6'(q의 경우)까지 내려가 비교한다.
-
왼쪽 자식 노드에 대한 재귀적 비교는 '4'까지는 참을 반환하지만, '5'와 '6'을 비교하는 단계에서 p.val == q.val가 거짓이 되므로 false를 반환한다.
-
이러한 값을 탐색하는 과정은 왼쪽 자식 노드를 따라가면서 이루어지며, 정확한 단계는 트리의 구조에 따라 다를 수 있지만, p의 왼쪽 자식 노드 '5'와 q의 동일 위치에 있는 '6'을 비교할 때 false가 발생한다. 따라서, 이 단계에서 비교 작업이 중단되고 최종적으로 false가 반환된다.
- 함수 종료: 모든 비교 절차가 완료되고, 'p'와 'q'가 완전히 동일하지 않음이 확인되면, 함수는 false를 최종적으로 반환한다.
Q) 왜 모든 재귀함수가 true를 반환해야만 최종 반환값이 true인 것이고, 왜 하나라도 false를 반환하면 최종 반환값이 false인걸까?
A)
return p.val == q.val && isSameTree(p.left, q.left) && isSameTree(p.right, q.right);이 코드블럭 때문에 그렇다. 세 가지 조건을 모두 만족해야만 true를 반환하도록 되어있다. 아까 위에서 연산자 ==의 역할을 참고하라.
