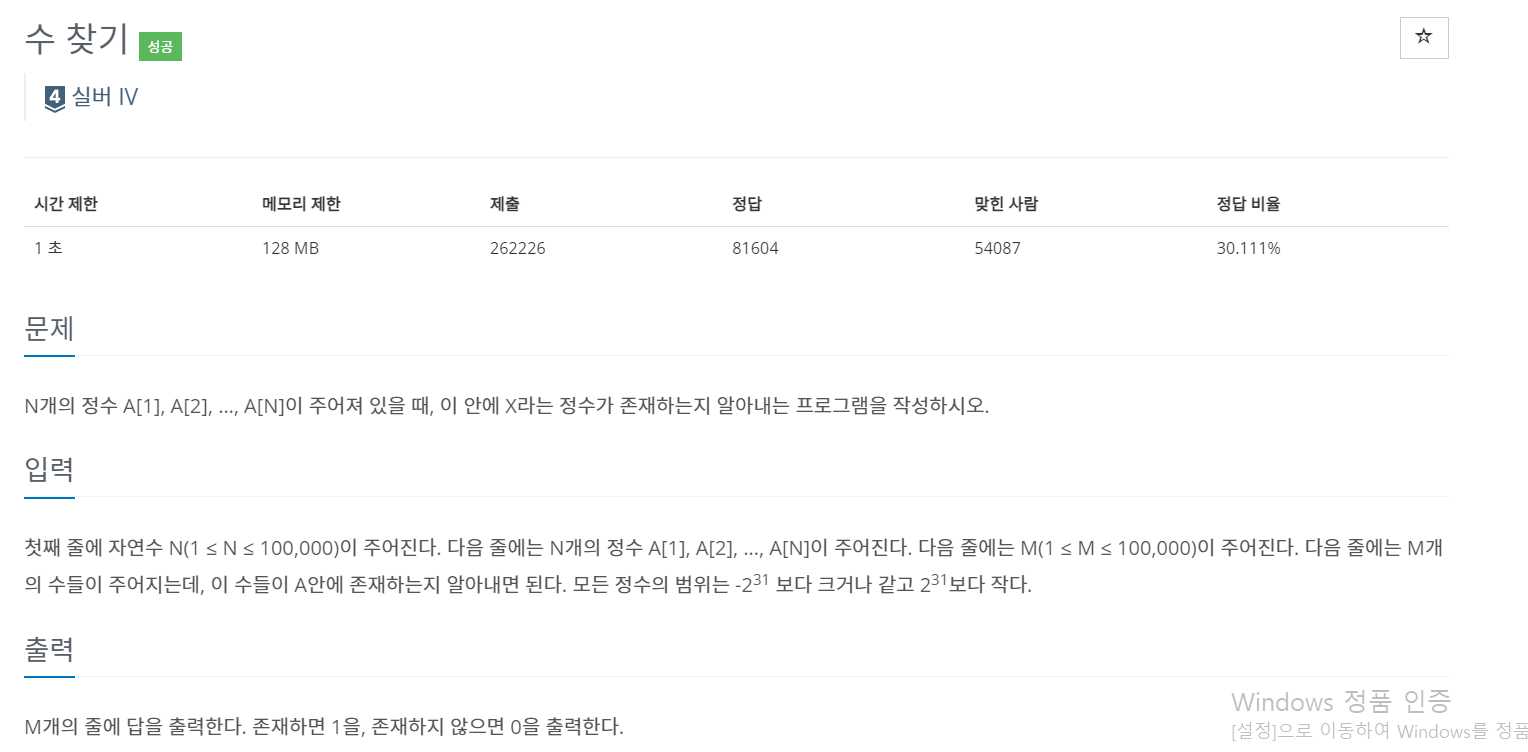
이진탐색 정리
선형탐색
전화번호부에서 'John' 이라는 사람의 연락처를 찾을 때, A -> B -> C 순으로 탐색하는 경우는 매우 비효율적이다.
이러한 탐색방법(일반적인 반복문)을 선형탐색(Linear search)라고 한다.
보통 정렬되지 않은 배열을 탐색할 때 사용한다.
시간복잡도는 O(n)이다.
이진탐색
만약 배열이 정렬되어 있다면, 또는 정렬이 가능하다면 이진탐색을 사용하는 것이 훨씬 효율적이다.
만약 타겟이 J이고, lo가 a, hi가 z일 때 범위를 줄이면서 j를 찾아나가면 매우 빠르다.
단, 배열은 무조건 정렬되어있어야한다. 오름차순/내림차순은 상관 없으며 정렬되어 있다는 것이 중요하다.
cf.
오름차순 정렬된 데이터에서 이진 탐색을 사용할 경우, 중간 값과 타겟 값을 비교하여 타겟 값이 중간 값보다 클 경우 오른쪽 부분 리스트를, 작을 경우 왼쪽 부분 리스트를 탐색 대상으로 한다.
내림차순 정렬된 데이터에서 이진 탐색을 사용할 경우에도 중간 값과 타겟 값을 비교하지만, 타겟 값이 중간 값보다 클 경우 왼쪽 부분 리스트를, 작을 경우 오른쪽 부분 리스트를 탐색 대상으로 한다. 즉 반대가 된다.
public class BinarySearchExample {
// 이진 탐색 함수
public static int binarySearch(int[] arr, int target) {
int left = 0;
int right = arr.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
// 타겟 값을 찾았을 경우
if (arr[mid] == target) {
return mid;
}
// 타겟 값이 중간값보다 크면 왼쪽 범위를 좁힘
if (arr[mid] < target) {
left = mid + 1;
} else {
// 타겟 값이 중간값보다 작으면 오른쪽 범위를 좁힘
right = mid - 1;
}
}
// 타겟 값을 찾지 못했을 경우
return -1;
}
public static void main(String[] args) {
int[] arr = {1, 3, 5, 20}; // 탐색할 배열
int target = 20; // 찾고자 하는 값
int result = binarySearch(arr, target);
if (result != -1) {
System.out.println("타겟 " + target + " 의 위치: " + result);
} else {
System.out.println("타겟 " + target + " 을(를) 찾을 수 없습니다.");
}
}
}
target이 array에 있는 경우
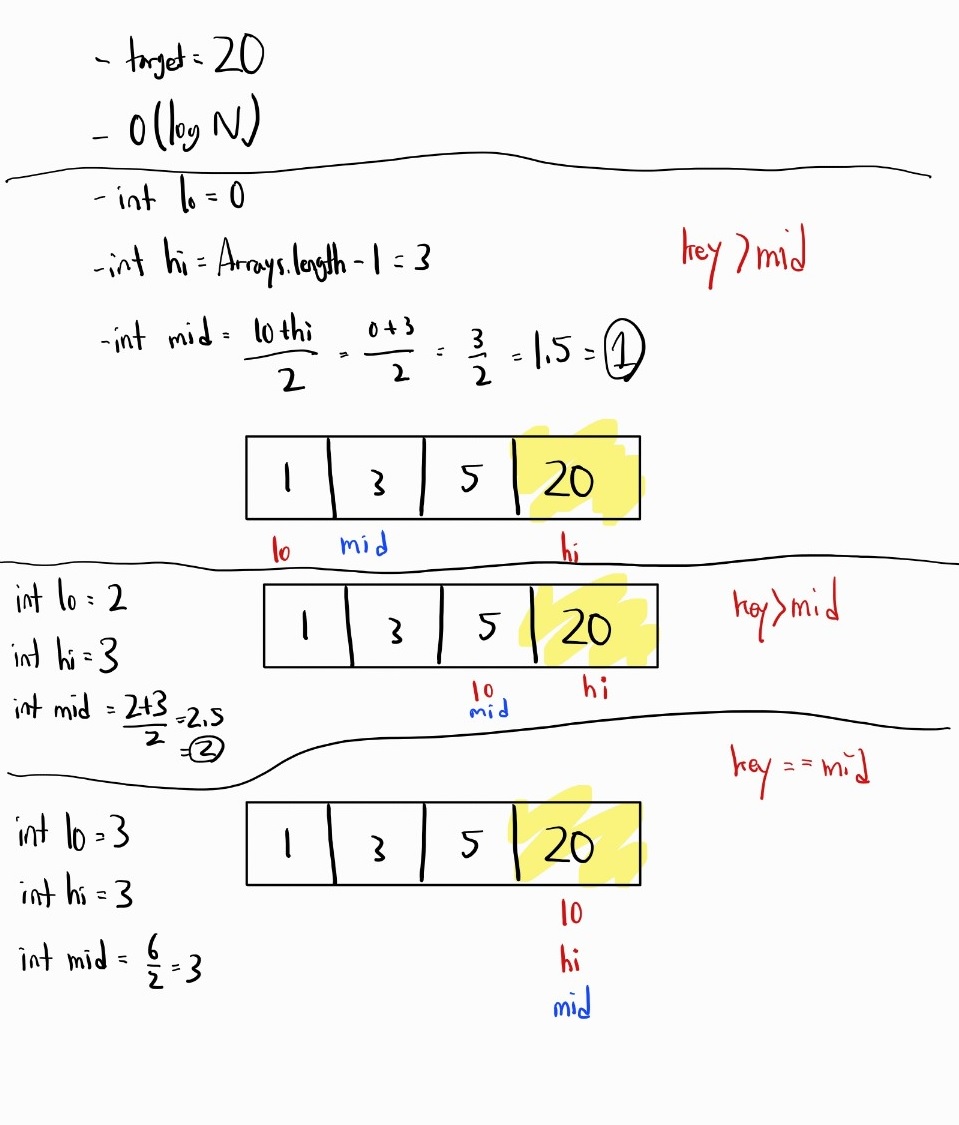
target이 array에 없는 경우
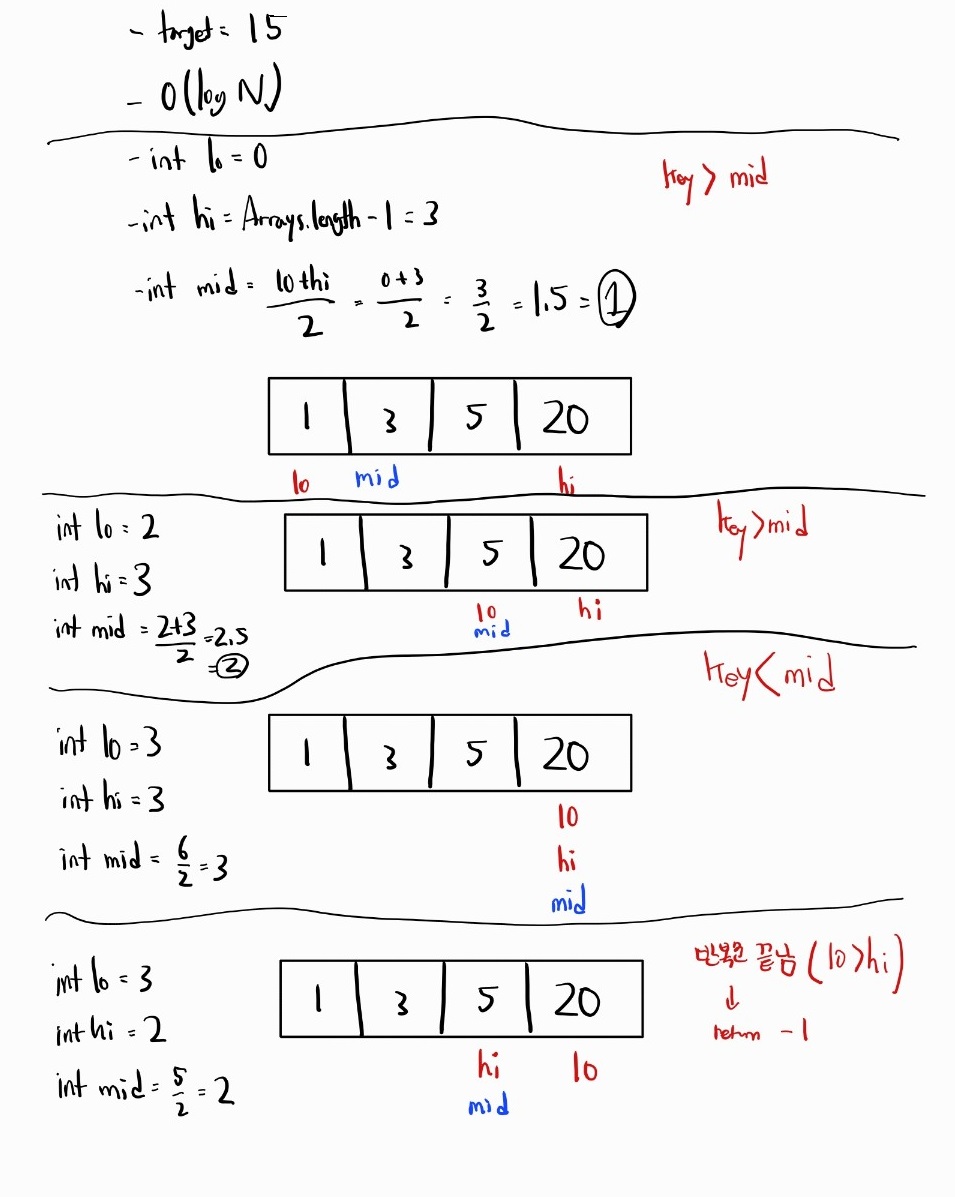
- 반복문 규칙을 벗어나므로 -1을 반환 및 반복문 종료
제출코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.*;
public class Main {
public static int[] array;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
array = new int[N];
StringTokenizer st = new StringTokenizer(br.readLine(), " ");
for (int i = 0; i < N; i++) {
array[i] = Integer.parseInt(st.nextToken());
}
// 이진탐색 이전에 무조건 배열을 정렬한다.
Arrays.sort(array);
int M = Integer.parseInt(br.readLine());
st = new StringTokenizer(br.readLine(), " ");
StringBuilder sb = new StringBuilder();
for (int i = 0; i < M; i++) {
// 찾고자 하는 값이 있을 경우 1, 없을 경우 0을 출력한다.
if (binarySearch(Integer.parseInt(st.nextToken())) >= 0) {
sb.append(1).append('\n');
} else {
sb.append(0).append('\n');
}
}
System.out.println(sb);
}
/**
* key = 5이고, array가 {1,2,3,4,5} 일 때의 예시
*
* 1. 초기 설정: lo = 0, hi = 4 (배열의 처음과 끝 인덱스).
* 첫 번째 중간지점(mid) 계산: mid = (0 + 4) / 2 = 2.
* 배열의 중간 값은 array[2] = 3
* 5는 3보다 크므로, lo를 mid + 1인 3으로 조정한다.
*
* 2. 새로운 범위에서 중간지점 계산: lo = 3, hi = 4.
* mid = (3 + 4) / 2 = 3 (!!자바에서는 소수점 이하를 버림!!).
* 배열의 중간 값은 array[3] = 4
* 5는 4보다 크므로, lo를 mid + 1인 4로 조정한다.
*
* 3. 이제 lo = 4, hi = 4다. 범위가 좁혀졌고 lo와 hi가 같다.
* 중간지점 계산: mid = (4 + 4) / 2 = 4.
* 배열의 중간 값은 array[4] = 5이며, 이는 찾고자 하는 key와 일치한다.
* 따라서, 찾고자 하는 값의 인덱스인 4를 반환한다.
*/
public static int binarySearch(int key) {
int lo = 0;
int hi = array.length - 1;
// lo가 hi보다 커지기 전까지 반복한다.
while (lo <= hi) {
int mid = (lo + hi) / 2;
if (key < array[mid]) {
hi = mid - 1;
}
if (key > array[mid]) {
lo = mid + 1;
}
if (key == array[mid]) {
return mid;
}
}
// 찾고자 하는 값이 없는 경우
return -1;
}
}시간복잡도
- 정렬 : O(n log n)
- 이진탐색 : 기본적인 시간복잡도는 O(log n)가 소요된다.
하지만 이 문제에서는 M개의 쿼리에 대해 이진탐색을 실행한다.
M * O(log n) = O(M log N) - 합계: O(n log n + M log n)
인상깊었던 점
-
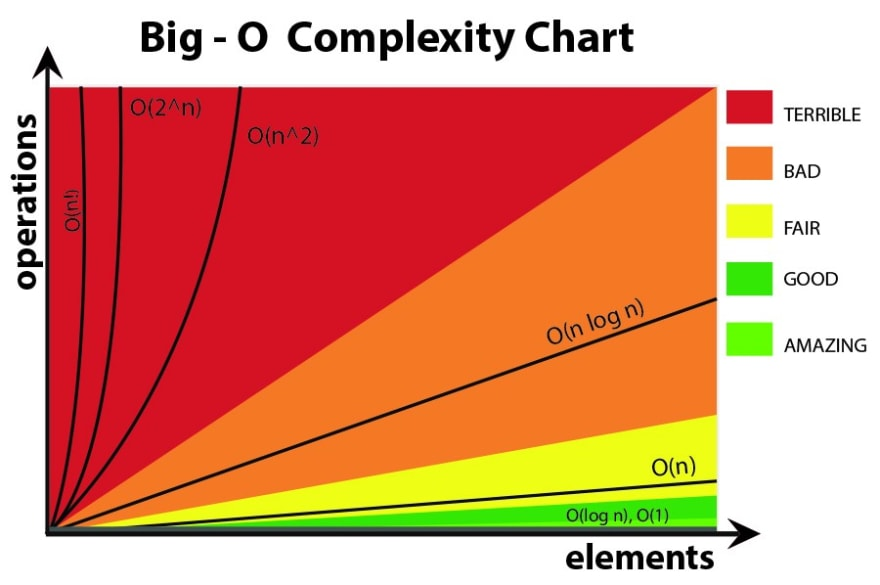
그래프 상으로 보면 O(n)과 O(log n)의 차이는 그렇게 커보이지는 않는데 실행시간에 있어서 얼마나 차이가 날지 알아보았다.
-
만약 데이터의 크기가 1,000,000(백만)이라고 가정할 때, (O(n)) 알고리즘은 데이터를 한 번에 하나씩 처리하기 때문에 최대 백만 번의 연산을 수행한다.
반면, (O(\log n)) 알고리즘은 데이터의 크기가 백만이라 할지라도 대략 20번 정도의 연산(밑이 2인 로그를 사용할 경우)만으로 처리가 가능하다. -
따라서, 큰 데이터를 다룰 때 (O(\log n))의 알고리즘은 (O(n))에 비해 훨씬 더 효율적이다. 이 차이는 데이터의 양이 증가함에 따라 더욱 명확해진다.
