데이터 불러오기
데이터 경로
data_dir = '/content/drive/MyDrive/Colab Notebooks/Deep Learning/data/dogs_vs_cats_small'
train_dir = data_dir + '/train'
val_dir = data_dir + '/validation'하나의 변수에 이미지파일 전부 다 합치기
이미지 크기 동일하게 만들어주기 (150,150)
라벨링
픽셀값 변경 0~255 (정수) > 0~1(실수)
- 값의 크기 줄이기>계산량 감소
- 분산 줄이기 > 원활한 계산 가능
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 픽셀값 변경ㅇ 기능
generator = ImageDataGenerator(rescale = 1./255)
라벨링
train_generator = generator.flow_from_directory(
directory = train_dir,
target_size = (150,150),
batch_size = 100,
class_mode = 'binary'
)
val_generator = generator.flow_from_directory(
directory = val_dir, # train이미지 경로
target_size = (150,150), # 변활할 이미지 크기
batch_size = 100,# 한번에 변활할 이미지 갯수
class_mode = 'binary' # 라벨링 (이진), 다중분류 = categorical
# 폴더의 알차벡 순서대로 레벨링 cats (0) dogs (1), 폴더 안에 있는 파일들에 적용
)
리벨링 결과 학인
print(train_generator.class_indices)
CNN모델 만들기
from tensorflow.keras import Sequential # 딥러닝 모델의 토대
from tensorflow.keras.layers import Dense, Conv2D, MaxPool2D, Flatten
# Dense: 분류부에사 틋징을 기반으로 사물 인식하는 역할
# Conv2D: 특징추출부에서 특징을 찾는 역할
# maxpool2d: ㅊ특징춫ㄹ부에서 특징이 아닌 부분을 삭제하는 역할
# flatten: 특징추출부와 분류부를 이어주는 역할, 데이터를 1차원으로 펼쳐준다#InputLayer사용
# model.add(InputLayer(input_size = 10))
# model.add(Dense(units = 32, activation = 'relu'))
#InputLayer 미사용
#model.add(Dense(units = 32, activation = 'relu', input_dim = 10))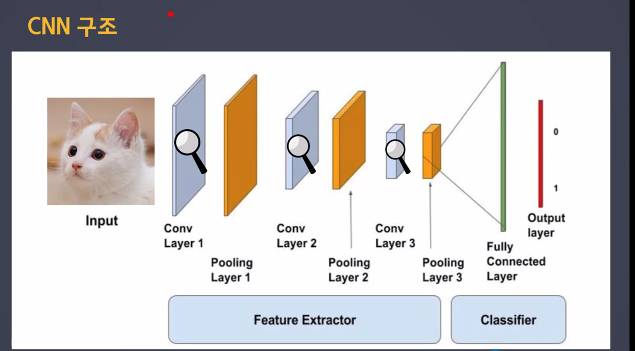
# 1. CNN모델 설계
model1 = Sequential()
# 입력층, 특징추출부, 3번해야함
# InputLayer의 역할을 담은 Conb층으로 시작
#1번
model1. add(Conv2D(
filters = 32, # 찾을 특징의 갯수
kernel_size = (3,3),# 특징의 크기
input_shape = (150,150,3),#입력 데이터의 모양, 입력층 역할, 입력 데이터의 모양 (RGB)
activation = 'relu', # 활성화함수
padding = 'same'
))
model1.add(MaxPool2D( # 특징 아닌 부분 삭제
pool_size = (2,2) #기준크기에서 1개의 값만 가져오기
# 2번
))
model1.add(Conv2D(
filters = 16, # 찾을 특징의 갯수
kernel_size = (3,3),# 특징의 크기
activation = 'relu', # 활성화함수
padding = 'same'
))
model1.add(MaxPool2D( # 특징 아닌 부분 삭제
pool_size = (2,2) #기준크기에서 1개의 값만 가져오기
# 3번
))
model1.add(Conv2D(
filters = 16, # 찾을 특징의 갯수
kernel_size = (3,3),# 특징의 크기
activation = 'relu', # 활성화함수
padding = 'same'
))
model1.add(MaxPool2D( # 특징 아닌 부분 삭제
pool_size = (2,2) #기준크기에서 1개의 값만 가져오기
))
# 특징 추출부 끝
model1.add(Flatten())#데이터를 1차원으로 만들어주기, Dense는 1차원만 학습 가능
# 분류부 시작
# 많은 층이 필요하지 않다 > 특징값을 이미 모아놓았기 때문에
model1.add(Dense(units = 32, activation = 'relu'))
model1.add(Dense(units = 16, activation = 'relu'))
# 출력층
# 이진분류
model1.add(Dense(units = 1, activation = 'sigmoid'))model1 확인
model1.summary()
# 이진분류
model1.compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy']
)학습
model1.fit(
train_generator,
epochs = 20,
validation_data = val_generator
)에측
import PIL.Image as pimg
import matplotlib.pyplot as plt
# 이미자 불러오기
img = pimg.open('/content/drive/MyDrive/Colab Notebooks/Deep Learning/data/KakaoTalk_20240110_115301266.jpg')
plt.imshow(img)
import cv2
img = '/content/drive/MyDrive/Colab Notebooks/Deep Learning/data/KakaoTalk_20240110_115301266.jpg'
pre_img = cv2.imread(img,cv2.IMREAD_COLOR)
pre_img = cv2.cvtColor(pre_img, cv2.COLOR_BGR2RGB)
pre_img = cv2.resize(pre_img,(150,150))
pre_img = pre_img.reshape((1,150,150,3))
result = model1.predict(pre_img)
if result > 0.5 :
print('개')
else :
print('고양이')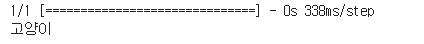
신경만 성능 개선
2. dropout 사용 - 신경망 설계
# 1. CNN모델 설계
model2 = Sequential()
# 입력층, 특징추출부
# InputLayer의 역할을 담은 Conb층으로 시작
model2. add(Conv2D(
filters = 32, # 찾을 특징의 갯수
kernel_size = (3,3),# 특징의 크기
input_shape = (150,150,3),#입력 데이터의 모양, 입력층 역할, 입력 데이터의 모양 (RGB)
activation = 'relu', # 활성화함수
padding = 'same',
strides = (2,2) # 행과 열단위로 몇 픽셀씩 건너뛰면서 계산할건지
))
model2.add(MaxPool2D( # 특징 아닌 부분 삭제
pool_size = (2,2) #기준크기에서 1개의 값만 가져오기
))
model2.add(Dropout(0.3))
model2.add(Conv2D(
filters = 16, # 찾을 특징의 갯수
kernel_size = (3,3),# 특징의 크기
activation = 'relu', # 활성화함수
padding = 'same'
))
model2.add(MaxPool2D( # 특징 아닌 부분 삭제
pool_size = (2,2) #기준크기에서 1개의 값만 가져오기
))
model2.add(Conv2D(
filters = 16, # 찾을 특징의 갯수
kernel_size = (3,3),# 특징의 크기
activation = 'relu', # 활성화함수
padding = 'same'
))
model2.add(MaxPool2D( # 특징 아닌 부분 삭제
pool_size = (2,2) #기준크기에서 1개의 값만 가져오기
))
# 특징 추출부 끝
model2.add(Flatten())#데이터를 1차원으로 만들어주기, Dense는 1차원만 학습 가능
# 분류부 시작
# 많은 층이 필요하지 않다 > 특징값을 이미 모아놓았기 때문에
model2.add(Dense(units = 32, activation = 'relu'))
model2.add(Dropout(0.3))
model2.add(Dense(units = 16, activation = 'relu'))
# 출력층
# 이진분류
model2.add(Dense(units = 1, activation = 'sigmoid'))2. compile
model2.compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy']
)2. 학습 - 데이터 확장
# 데이터확장하기
aug_generator = ImageDataGenerator(
rescale = 1./255, # 픽셀값
rotation_range = 20, # 시계방향 회전 범위
width_shift_range = 0.1, #수평이동 범위
height_shift_range = 0.1, # 수직이동 범위
shear_range = 0.1, #반시계 방향 회전
zoom_range = 0.1, #확대/축소 번위
horizontal_flip = True,# 수평 뒤집기
fill_mode = 'nearest' # 가까운 값으로 채움
)
train_aug_generator = aug_generator.flow_from_directory(
train_dir,
target_size = (150,150),
batch_size = 100,
class_mode = 'binary'
)model2.fit(
train_aug_generator,
epochs = 20,
validation_data = val_generator)
3. 전이학습
from tensorflow.keras.applications import VGG16
conv_base =VGG16(
weights ="imagenet",
include_top = False, #분류부 사용할것인가?
input_shape = (150,150,3)
)conv_base.summary()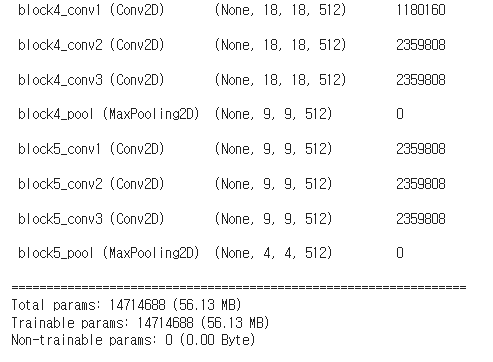
# 현재 상황은 전체 파라미터(가중치)가 학습 가능한 상황
# 학습을 진행하면 기준ㄴ에 사지거 있던 1000개의 사문에서 특징을 추출하는 방법이 덮어쒸워진다
# 특징추출부의 학습이 불가능하도록 변경
# 동결 = 가중치가 갱신되는것을 막는것
conv_base.trainable = False# 모델설계
model3 = Sequential()
# 특징추출부 가져오기
model3.add(conv_base) # conv 13개 층 쌓기, pool 5개층 추가
model3.add(Flatten())
model3.add(Dense(units = 64, activation = 'relu'))
model3.add(Dense(units = 1, activation = 'sigmoid'))model3.summary()
model3.compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy']
)model3.fit(
train_generator,
epochs = 20,
validation_data = val_generator
)Test
import PIL.Image as pimg
import cv2
img = '/content/drive/MyDrive/Colab Notebooks/Deep Learning/data/corgi.jpg'
# 이미지 불러오기
pre_img = cv2.imread(img,cv2.IMREAD_COLOR)
# 색상 체널 변경 (RGB > BGR) python에서는 bgr순서로 데이터 읽음
pre_img = cv2.cvtColor(pre_img, cv2.COLOR_BGR2RGB)
#아미지 크기 변경
pre_img = cv2.resize(pre_img,(150,150))
# 이미지 차원 변경 (데이터 수, 세로, 가로, rgb채널)
pre_img = pre_img.reshape((1,150,150,3))
result = model1.predict(pre_img)
if result > 0.5 :
print('개')
else :
print('고양이')
전이학습 - 미세조정방식
특징 추출부를 조김씩 수정
- 한번에 많이 수정학되면 기존의 방식을 잃어버릴 수 있다
- 조금씩 여러번 수저을해야 기존의 바ㅇ식과 새로운 특징추출방법이 잘 어울어짐
- 특징추출방식에 비해서 더 좋은 성능을 낼 수 있다
- 수종조절이 많이 필요하다
from tensorflow.keras.applications import VGG16
conv_base = VGG16(
weights = 'imagenet',
include_top = False,
input_shape = (150,150,3)
)# 0.
for layer in conv_base.layers :
layer.trainable = False# 모델설계
model4 = Sequential()
model4.add(conv_base)
model4.add(Flatten())
model4.add(Dense(units = 64, activation = 'relu'))
model4.add(Dense(units = 1, activation = 'sigmoid'))
model4.compile(
loss = 'binary_crossentropy',
optimizer = 'adam',
metrics = ['accuracy']
)model4.fit(
train_generator,
epochs = 20,
validation_data = val_generator
)# block-conv1부터 동결 해제
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable :
layer.trainable = True
else:
layer.trainable = False
model4.fit(
train_generator,
epochs = 20,
validation_data = val_generator
)
열심히 공부합시다! The best is yet to come! 💜