- Phân lớp tuyến tính lấy vào các đặc trưng và đưa ra quyết định kết quả đầu vào thuộc về một lớp nào đó. Thường bài toán này sẽ đưa ra một/các số là các xác suất đầu vào rơi vào một lớp nào đó. Trong bài toán có m lớp, thuật toán này sẽ trả lại m số trong khoảng (0,1), cố tổng bằng 1, tạo thành một phân bố rời rạc không trùng.(0,1)1
Ví dụ: phân loại chó mèo, phân loại trong ảnh có xúc xích hay không (phân lớp nhị phân), nhận biết ảnh chữ số (phân lớp 10 loại: các chữ số từ 0 đến 9), v.v.
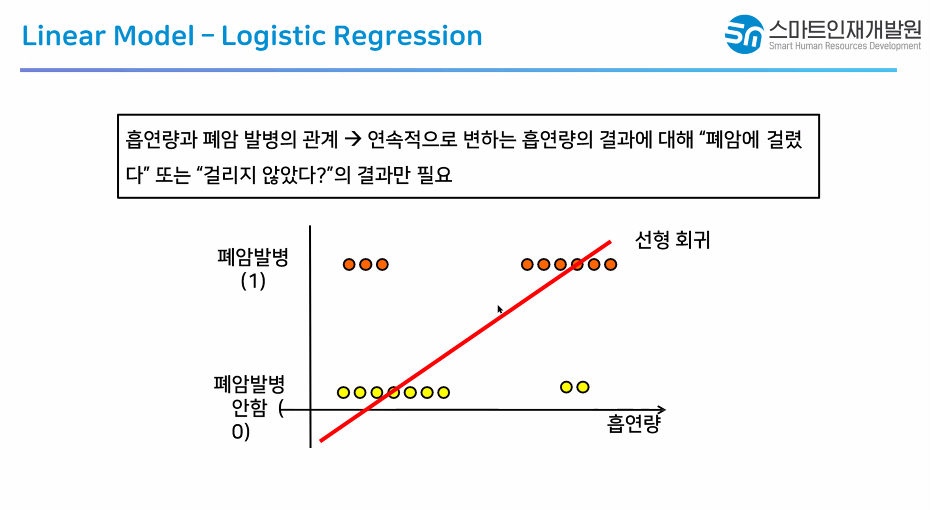
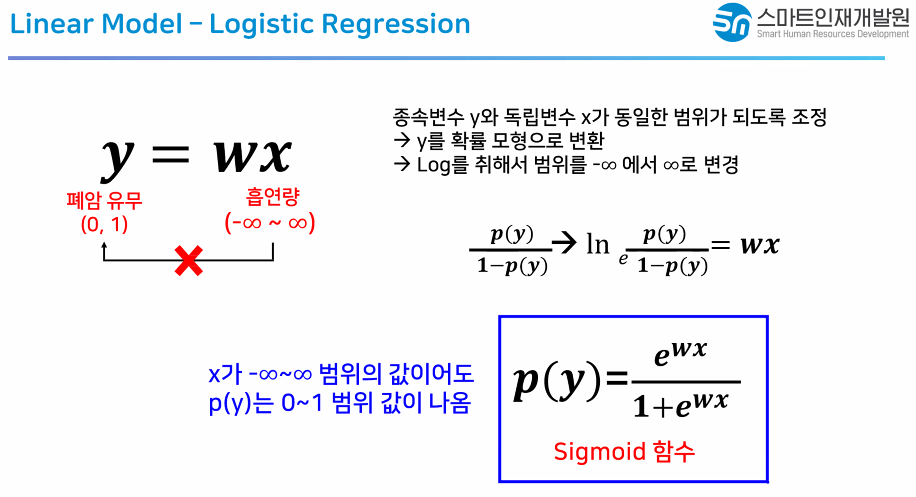
- Hồi quy tuyến tính lấy vào các đặc trưng và đưa ra một số thực trong dải
(−∞,+∞)
(−∞,+∞)
Ví dụ: bài toán định giá nhà đất (giá trị không dương ám chỉ lỗ/không đáng mua), bài toán định giá cổ phiếu (giá trị âm gợi ý nên dùng một lựa chọn phái sinh thích hợp), v.v.

Linear Model - Logistic Regression👧
Logistic regression’s output lies between 0 and 1 as the algorithm is designed to predict a binary outcome for an event based on the previous observations of a data set. It uses independent variables to predict the occurrence or failure of specific events.
Sigmoid 함수 사용
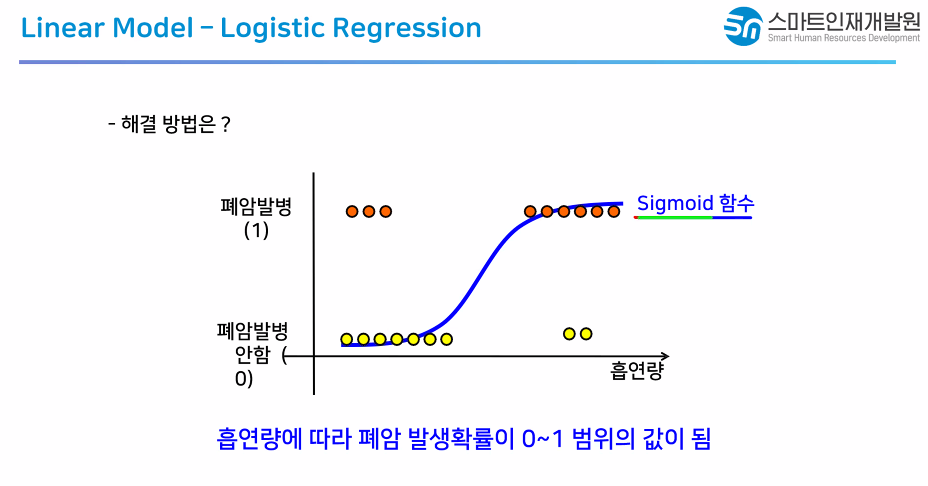
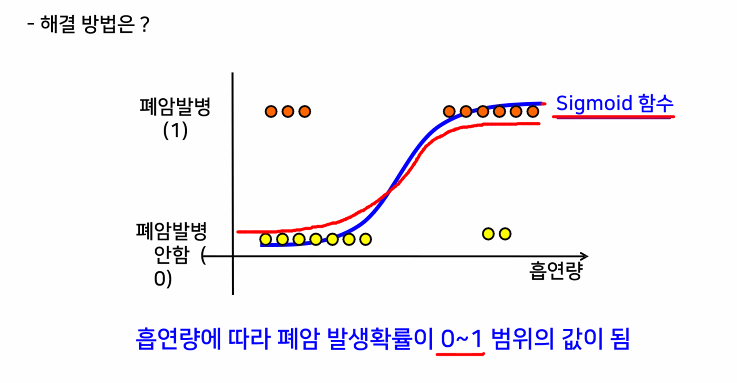
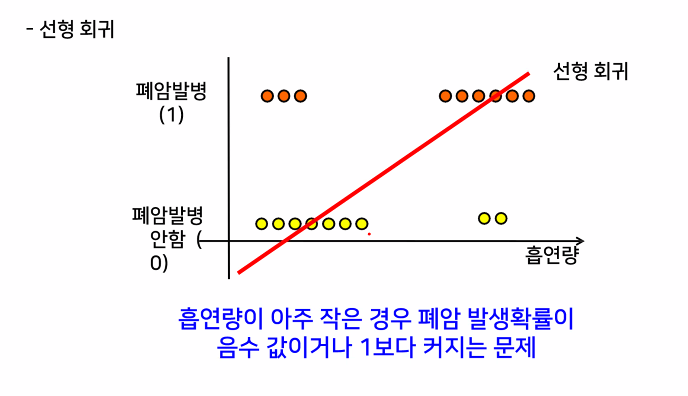
Because that straight line can not get all the data that out of the line, so the sigmoid function is created to get the missed value that out of the line
직선으로 수분할 수 없는 문제 해결
확률이 100%를 넘어가는 문제 해결

문법:
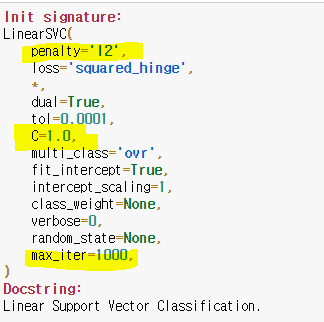
LogisticRegression(C, max_iter)c: the smaller, the regulation stronger
max_ iter: need to get big num
if there is no special data use L2, if not use L1
Practice
- import library
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()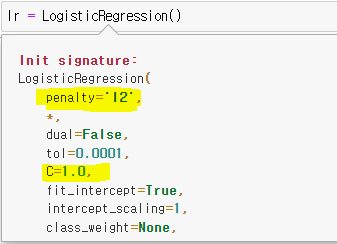
normally always use L2 because dun wanna miss any value

Linear SVC (Support Vector Machines)👨🦳

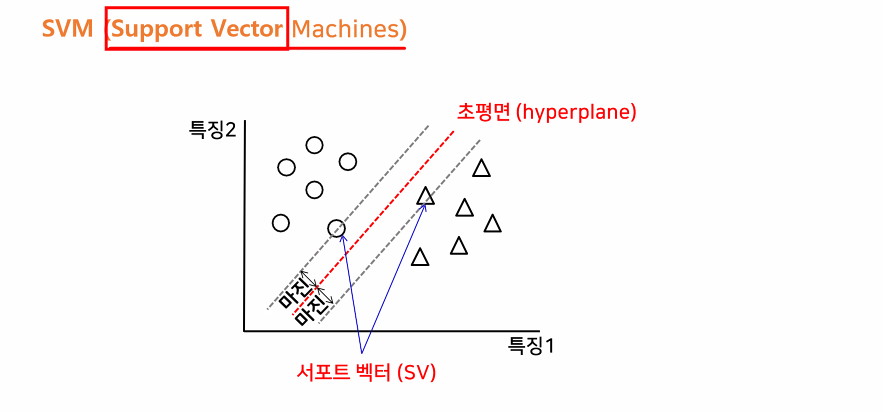

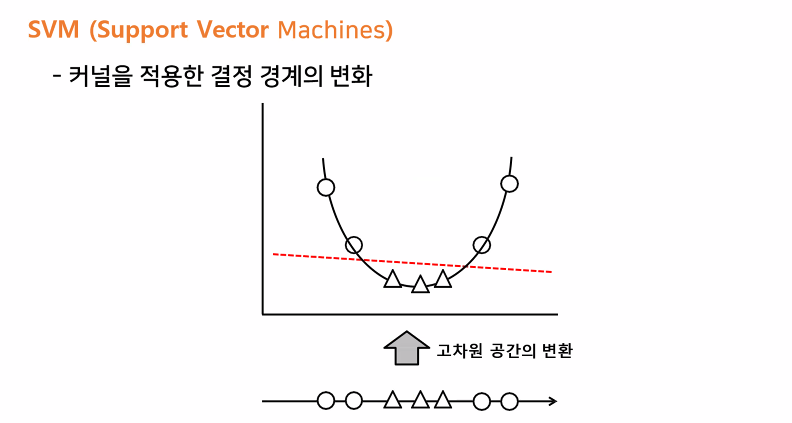
it is a line ( hyperoplane) that the distance from the that point to the line (margin) is the same
And this line need to divide into 2 parts to classify clearly (one side is circle and one site is 세모)
SVM là viết tắt của cụm từ support vector machine. Đây là một thuật toán khá hiệu quả trong lớp các bài toán phân loại nhị phân và dự báo của học có giám sát. Thuật toán này có ưu điểm là hoạt động tốt đối với những mẫu dữ liệu có kích thước lớn và thường mang lại kết quả vượt trội so với lớp các thuật toán khác trong học có giám sát.
SVM :
- support vector: 결정경계를 이루는 직선과 가장 가깝게 있는 데이터
- 마진: 결정경계와 supporter vector 사이의 거리
- 마진의 거리가 최대가되고, 마진끼리의 거리가 비슷한 결정경계 찾기
- 초평만(결정경계)을 사용하여 데이터를 나눈다
Ưu điểm của SVM đó là:
Đây là thuật toán hoạt động hiệu quả với không gian cao chiều (high dimensional spaces).
Thuật toán tiêu tốn ít bộ nhớ vì chỉ sử dụng các điểm trong tập hỗ trợ để dự báo trong hàm quyết định.
Chúng ta có thể tạo ra nhiều hàm quyết định từ những hàm kernel khác nhau. Thậm chí sử dụng đúng kernel có thể giúp cải thiện thuật toán lên đáng kể.
Chính vì tính hiệu quả mà SVM thường được áp dụng nhiều trong các tác vụ phân loại và dự báo, cũng như được nhiều công ty ứng dụng và triển khai trên môi trường production. Chúng ta có thể liệt kê một số ứng dụng của thuật toán SVM đó là:
**Mô hình chuẩn đoán bệnh. Dựa vào biến mục tiêu là những chỉ số xét nghiệm lâm sàng, thuật toán đưa ra dự báo về một số bệnh như tiểu đường, suy thận, máu nhiễm mỡ,…
Trước khi thuật toán CNN và Deep Learning bùng nổ thì SVM là lớp mô hình cực kì phổ biến trong phân loại ảnh.
**Mô hình phân loại tin tức. Xác định chủ đề của một đoạn văn bản, phân loại cảm xúc văn bản, phân loại thư rác.
**Mô hình phát hiện gian lận.

import library
from sklearn.svm import LinearSVC
svm = LinearSVC()