Machine Learning
1.Machine Learning - Regression
UntitledTypically, you need regression to answer whether and how some phenomenon influences the other or how several variables are related. For exampl
2.Machine Learning - Confusion matrix
06. 🍑Confusion Matrix Chap06_Logistic Regression, SVM, 분류평가지표, GridSearch.pdf Overview Là một phương pháp đánh giá kết quả của những bài toán phân
3.Machine Learning - Boston Crime - House Price Predict
보스턴 집값 데이터를 활용해서 집값을 예측해보자회귀문제Untitled\*\*7. 예측 및 평가\*\*
4.Machine Learning - LinearReg-Lasso, Ridge
Lasso and Ridge are two regularization techniques used in machine learning, especially in linear regression, to prevent overfitting and improve the mo
5.Machine Learning - Data Scaling
Data scaling is the process of transforming the values of the features of a dataset till they are within a specific range, e.g. 0 to 1 or -1 t
6.Machine Learning - Practice Titanic
titanic 데이터를 사용해서 생존자 와 사망자 예측해보기kaggle train,test데이터 downloadimport library결측치 처리이상치 처리UntitledUntitled도움이 안될거같아탑승한 항구 empty data fillfullUntitledUnt
7.Machine Learning - Decision Tree

from character → to number→ separate into embarked → then just one-hot encoding 0 or 1but weakness is need to use many columnsImport library 🍏\*\*데이터
8.Machine Learning - KNN Practice - Iris Flower Analysis 🌸

붓꽃의 꽃잎 갈이, 꽃잎 너비, 꽃받침 길이, 꽃받침 머비 특징을 활용해 3가지 품종을 분류해보자KNN모델의 이웃의 숫자를 조절해보자petal: 꽃잎/sepal: 꽃받침 🌸🌺문제와 답 데이터 분리훈련세트와 평가 세트로 분리훈련세트/데이터: 머신러닝 모델을 학습할 때
9.Machine Learning - 🕵️♂️ Supervised Learning

🕵️♂️ Supervised Learning In machine learning, both classification and regression are types of supervised learning tasks, but they are used for diff
10.Linear Model - Classification (Logistic+ SVC) ☕

Phân lớp tuyến tính lấy vào các đặc trưng và đưa ra quyết định kết quả đầu vào thuộc về một lớp nào đó. Thường bài toán này sẽ đưa ra một/các số là cá
11.Machine Learning - Text mining🧁

What is text mining? > Text mining consists in using Machine Learning for text analysis. Discover all you need to know: definition, functioning, tech
12.Machine Learning - Text mining practice - Movie reviews dataset analysis

https://ai.stanford.edu/~amaas/data/sentiment/앞축풀기 -> delete folder unsup 폴더 삭제영화 리부 데이터셋을 활용해서 긍정과 부정을 구분해보자긍정/부정 리부에서 자주 사용되는 단어를 확인해보자Large mo
13.Machine Learning - Predict Stock Price - Apple 🍎
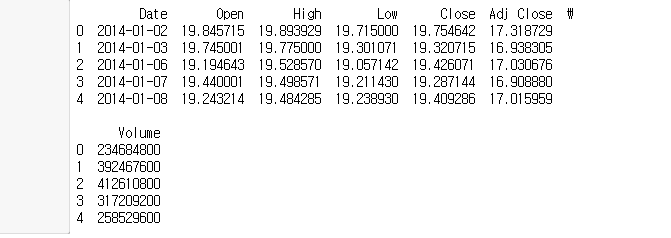
https://www.kaggle.com/datasets?search=stock&sort=published
14.Machine Learning - How to get stock historic data

1. import library 2. Get Current Stock Price Data Method 1: Method2: You can get all the historical price data by providing the start date, end date
15.Machine Learning - 영어 영화 리뷰 분석 PipeLine사용( Bow + SVM 합쳐)
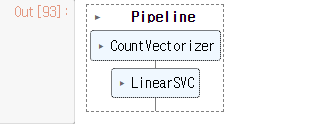
Import librartCall datasets from saved folderReview train dataTo decide which key will be y_trainfrom sklearn.pipeline import make_pipelinepipe_model
16.Machine Learning - Install konlpy - 한글 형태소 분류기

한글데이터 사용하기 위한 환경설정 환경 변수 설정 파이썬에서 자바 기능 사용하기 위해 자바 관련 환경 변수 설정 window키 > 시스템 환경 변수 편집 
18.Machine Learning -추천 시스템 패키지 - Surprise
지금까지 콘텐츠 가반 필터링, 아이템 가번 협업 필터링, 그리고 잠재 요인 기반 협업 필터링을 파이션 코드로 구현해 봤습니다. 앞에서 다룬 예제 코드는 최적화나 수향 속도 측면에서 좀 더 보완이 필요합나다 추천 시스템은 상업적으로 가치가 크기 때문에 별도의 패기지로 제
19.Machine Learning - 시각화
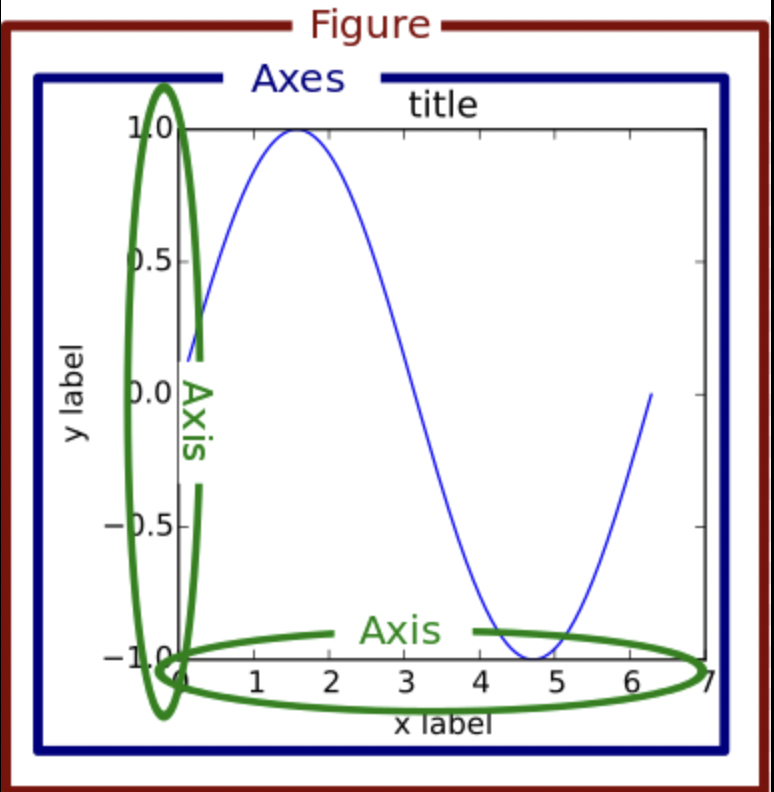
맛플롯립은 파이썬 시각화를 위한 기반 모듈인 pylot을 제공하며 이를 통해 시각화를 구현할 수 있습니다pyplot의 두 가지 중요 요소 - Figure and AxesFigure객체는 그림을 그리기 위한 캔버스의 역할을 한다고 간주해도 좋습니다. 그림판의 크기를 조절
20.Text mining - Naver movie review 분석 🎞
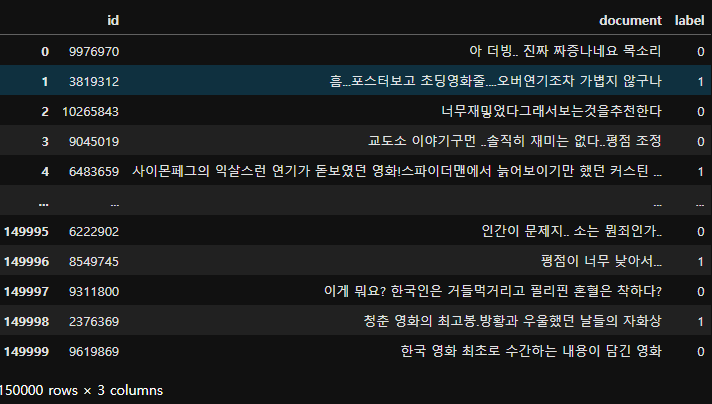
네이버 영화 리뷰 데이터셋긍정과 부정 구분하기긍정/부정 판단하는데 많이 영향을 끼치는 단어 시각화bow말고 다른 토큰화방법 사용해보기((150000, 3), (50000, 3))X_train = bow_kkma.transform(X_train)X_test = bow_
21.Machine Learning - Must remember 10 things
문제정의인공지능으로 어떤 기능을 제작하려하는지 최대한 자시하게데이터 수집where: AI HUB, Kaggle, Google Datasets, Roboflow직잡 수집할땐 최대한 많이(정확한 예측)최대한 다양하게 (깊은 분석)데이터 전처리결측치 여부이상치 여부탐색적 데
22.Machine Learning - Credit Card Approval Prediction
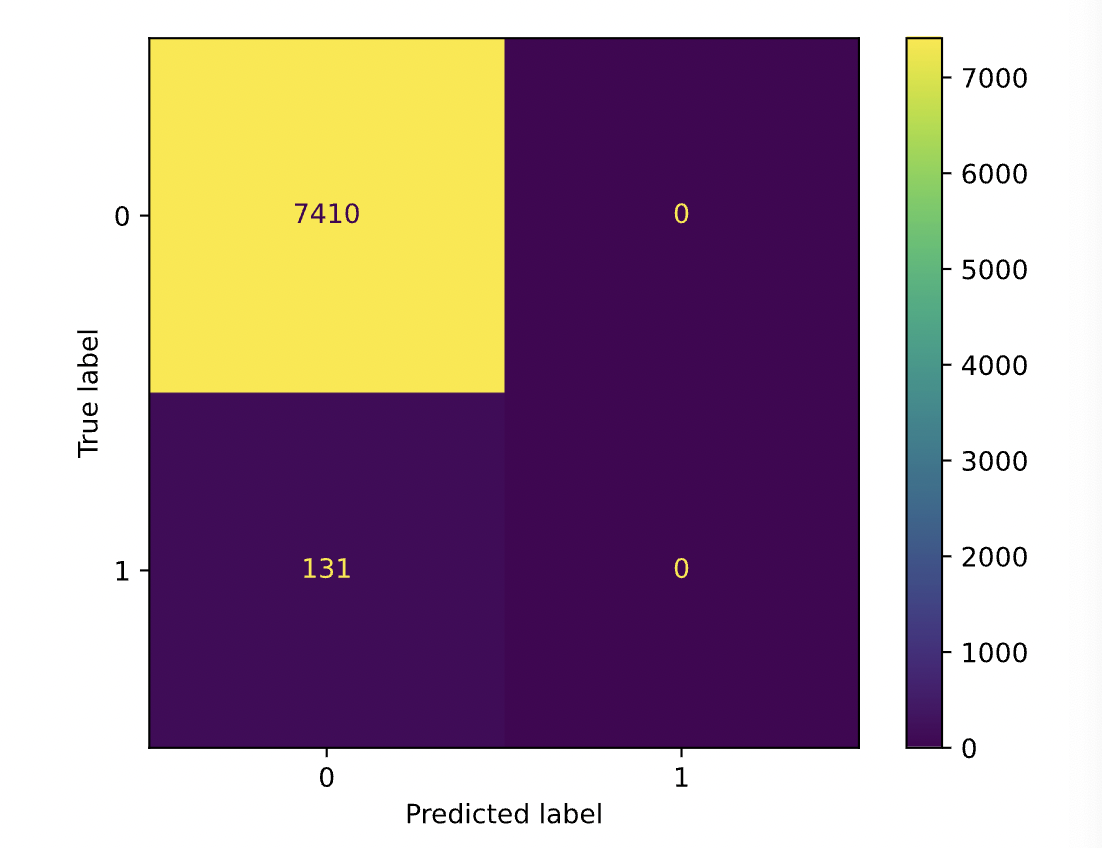
credit 데이터를 사용해서 좋/나쁜 손님 예측해보기 predict if an applicant is 'good' or 'bad' clientkaggle에 train, test data downloadCODE_GENDER'M' 'F'개FLAG_OWN_CAR'Y' 'N
23.Machine Learning - Basic and most important libraries