torch.nn 공부하기 전에 torch.Tensor 공부한 내용을 약 한 시간 넘게 정리하고 분명 포스팅을 했는데 사라졌다..
속상하다..
일단, torch.nn (1)에서 다루지 못했던 추가적인 내용을 다루려고 한다.
- Normalization Layers
- Dropout Layers
- Trnasformer Layers
1. Normalization Layers
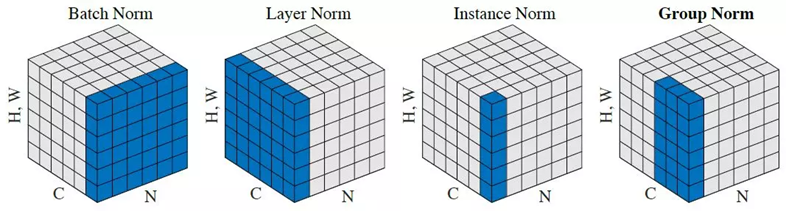
Normalization 레이어는 말 그대로 데이터에 대한 정규화를 수행하기 위한 레이어다.
BatchNorm
대표적인 정규화 레이어로는 배치 정규화 레이어인 BatchNorm1d~3d가 있다.
nn.BatchNorm1d(num_features)
nn.BatchNorm2d(num_features)
이런 식으로 num_features가 input으로 들어가게 되는데, num_feature는 이전 레이어의 output 차원 수가 되겠다.
Linear 레이어의 경우에는 out_features 값이겠고,
합성곱 레이어는 out_channels에 해당하는 값을 사용해야 한다.
참고로, 배치 정규화는 mini-batch 각 데이터에서 데이터의 평균을 뺀 값을 표준편차로 나눈 N(0, 1) 표준정규분포화 후에,
그 값에 gamma를 곱하여 scaling 하고 beta를 더하여 shift를 고려할 수 있도록 한다.
이 gamma, beta 파라미터는 global한 데이터 (전체 데이터셋) 고유의 특성을 가질 수 있도록 학습하는 파라미터다.
gamma와 beta의 gradient를 역전파 과정에서 학습이 가능하다.
BatchNorm2d의 경우에는 정규화를 할 때, 각 채널에 대해서 mini-batch의 평균과 분산을 사용한 정규화를 진행한다.
Layer Normalization
다른 정규화 방법으로는 Layer Normalization이 있다.
이는 주로 RNN 계열의 모델에서 많이 사용한다.
- 개별 샘플의 모든 feature에 대해서 정규화를 수행함
- CNN에서는 BatchNorm보다 잘 작동하지 않는데, 작은 mini-batch size를 가진 RNN에서는 어느 정도 성능을 보인다.
- input 데이터의 scale에 robust하며, 가중치 행렬의 scale과 shift에 대해 robust하다
- nn.LayerNorm([채널 수, 높이, 너비])
Group Normalization
채널을 여러 그룹으로 나누어 각 그룹별로 정규화를 수행한다.
- 배치 크기에 덜 민감하고, 극도로 작은 배치 사이즈에서도 잘 동작한다.
- 그래서, 극도로 작은 batch_size를 써야하는 상황에서 batchnorm 대신 사용하면 좋은 결과를 얻을 수도 있다.
- nn.GroupNorm(num_groups, num_channels)
Instance Normalization
각 개별 샘플의 채널별로 정규화를 수행한다. 주로, 스타일 변환과 같은 이미지 처리 작업에 사용된다.
- nn.InstanceNorm2d(num_features) # 채널 수
2. Dropout Layers
드롭아웃 레이어는 신경망의 학습 과정에서 무작위로 일부 뉴런을 비활성화(Drop)하여 신경망이 특정 뉴런에 과도하게 의존하지 않도록 한다.
즉, 과적합을 방지하기 위한 방법 중 하나이다.
최근, batchnorm을 적용하는 경우 Dropout 효과를 가지고 있어서 Dropout을 쓰지 않는다는 포스팅을 봤다.
batchnorm 레이어에서 Dropout 효과가 어떻게 나타난다는 건지 이해가 가지 않아서 GPT한테 물어봤는데 GPT의 답변에 따르면, batchnorm이 dropout과 같은 효과를 기대하기는 어려운 것으로 보인다.
오히려 batchnorm과 Dropout 을 조합하여 사용하면 더 나은 성능을 기대할 수 있다고 한다.
드롭아웃의 기본 원리는 1. 학습 시에 각 뉴런을 확률 p로(전체 뉴런 * p 만큼) 비활성화 하고 2. 평가 시에는 모든 뉴런을 활성화 하고, 학습 시의 드롭아웃 확률 p를 반영하여 뉴런의 출력을 스케일링 하는 것이다.
- nn.Dropout : FC 레이어에서 사용되는 드롭아웃 레이어
- nn.Dropout : 합성곱 레이어에서 사용되는 드롭아웃 레이어
3. Transformer Layers
nn.Transformer 레이어는 NLP, 시퀀스 데이터에서 강력한 성능을 발휘하는 트랜스포머 모델의 구현체다.
트랜스포머 모델은 Attention 메커니즘을 기반으로 시퀀스 데이터를 처리한다.
트랜스포머 모델은 크게 Encoder와 Decoder로 구성된다.
- Encoder
- 입력 시퀀스를 받음
- 여러 개의 인코더 레이어로 구성되며, 각 레이어는 Multi-Head Self-Attention과 Feed-Forward Network로 구성된다.
- Decoder
- 인코더의 출력(Output)을 입력으로 받는다.
- 목표 시퀀스를 받아, 예측 시퀀스를 생성한다.
- 여러 개의 디코더 레이어로 구성되며, 각 레이어는 Multi-Head Self-Attention, Encoder-Decoder Attention, Feed-Forward Network로 구성된다.
아직 익숙치 않은 내용이라 어렵다.
추후 Transformer를 좀 더 자세히 이해해보기로 한다.
