PyTorch의 주요 모듈 두번째로 신경망 레이어를 정의한 torch.nn 모듈을 살펴보자.
2. torch.nn
PyTorch에서 신경망을 구축하고 훈련하는 데 필요한 다양한 기능을 제공함
- 레이어 (Linear, Conv1d, Conv2d, BatchNorm 등)
- 활성화 함수 (ReLu, Sigmoid, Tanh 등)
- 손실 함수 (CrossEntropyLoss, MSELoss 등)
- 컨테이너 (Sequential 등)
우리가 직접 신경망을 클래스로 정의할 때는 nn.Module을 상속받아야 한다.
Class에서 상속이란, 코드의 재사용성을 확보하기 위해 부모 클래스에서 정의된 __init__ 메소드, 속성 등을 그대로 활용하기 위한 방법을 말한다.
클래스 상속은 보통 Class 클래스명(부모클래스): 로 간단하게 가능하다.
Class CNN(nn.Module): # nn.Module 상속
def __init__(self):
...또한, 신경망을 구성하기 위한 레이어는 클래스의 __init__ 메소드 안에 차곡차곡 정의해둔다.
이 때, 부모 클래스에서 상속된 초기 속성을 활용하기 위해 우선 super()라는 함수로 초기 속성을 상속받는다.
Class CNN(nn.Module): # nn.Module 상속
def __init__(self):
super(CNN, self).__init__() # nn.Module의 초기 속성 상속
self.conv1 = nn.Conv2d(in_channels = 1, out_channels = 16, kernels = 5, stride = 2, padding = 1
...위처럼 __init__ 메소드를 통해 레이어를 쌓는 과정에서 여러 유형의 레이어를 사용하게 되는데 이를 위해 nn모듈을 사용한다.
1) Layers
-
합성곱 레이어
-
nn.Conv1d : 1차원 합성곱 레이어, 보통 시계열 데이터, NLP에 많이 활용됨
Conv1d에 대한 호기심이 생겨 여러 블로그 등을 참조하여 대략적인 정리를 함
Conv1d는 Conv2d가 가로, 세로 모든 방향으로 필터가 이동하면서 합성곱을 계산하는 것과 달리, 가로로만 이동하면서 합성곱을 계산함.아래 사진은 커널의 너비(임베딩 벡터의 차원)가 1인 경우를 예시로 한 Conv1d의 움직임 예시
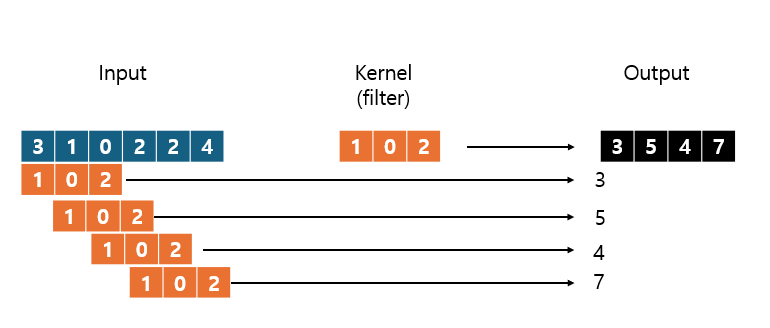
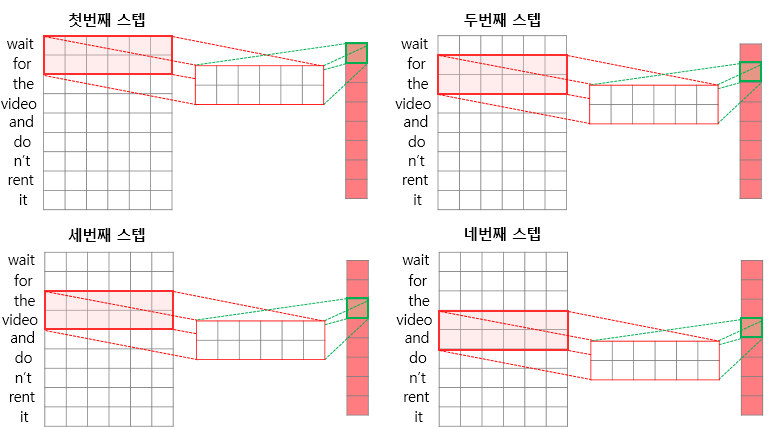
(이미지 참고: https://sanghyu.tistory.com/24)아래는 커널의 너비(임베딩 벡터의 차원)가 6인 경우
Conv1d는 한 커널(필터)의 너비가 임베딩 벡터의 차원과 동일하게 설정됨 (그래서 필터가 한 방향으로만 움직이게 됨)
(출처: https://wikidocs.net/184983)
Conv1d의 input은 [Batch_size, num_channels, sequence_length]로 존재함
batch_size는 배치 크기, num_channels는 임베딩 벡터의 차원 혹은 피처 수, sequence_length는 말 그대로 시퀀스 길이고 시계열이라면 시간 단계 수, NLP라면 단어 수가 된다. (batch_size는 입력 데이터와 동일하게 유지된다)
nn.Conv1d(in_channels, out_channels, kernel_size, stride, padding, dilation) # dilation은 커널 내에서 몇 time_step을 건너띄고 볼 것인가를 결정 -
nn.Conv2d : 2차원 합성곱 레이어
이미지 등에서 가장 흔하게 쓰는 합성곱 레이어 형식nn.Conv2d(in_channels, out_channels, kernels, stride, padding, ...) -
nn.Conv3d : 3차원 합성곱 레이어
의료영상(MRI, CT) 등 3차원 의료영상, 비디오, 3d 객체 인식, 지형 분석 등 시공간 적인 데이터에 활용함 -
nn.ConvTranspose1d, 2d, 3d : n차원 데이터를 up-sampling 하기 위한 역합성곱 레이어.
일반적으로, Decoder의 아키텍처를 구성하는데 사용됨.
(e.g. 낮은 해상도를 높은 해상도로 복원)
※ 역합성곱은 일반 합성곱을 "역방향"으로 수행하는 것이지, "역연산"을 수행하는 것은 아님
-
-
선형 레이어
- nn.Linear : 입력과 출력을 선형변환하는 Fully-Connected Layers
nn.Linear(in_features = 1024, out_features = 32)
- nn.Linear : 입력과 출력을 선형변환하는 Fully-Connected Layers
-
풀링 레이어
가장 특징적인 값을 추출하여 차원 축소 및 계산 효율을 높이는 역할을 하는 레이어
과적합을 방지하는 데에도 도움을 줌
-
- nn.MaxPool1d
- nn.MaxPool2d : 각 지역의 가장 큰 값만 선택해 맵을 축소
- nn.AvgPool1d
- nn.AvgPool2d : 각 지역의 평균값을 선택해 맵을 축소
- nn.AdaptiveAvgPool1d : Global Average Pooling. 전체 피처맵의 평균을 계산하여 output_size 로 축소
nn.AdaptiveMaxPool1d(output_size) - nn.AdaptiveAvgPool2d : Global Average Pooling. 지정된 output 크기를 맞추기 위해 input을 적절한 크기로 나누고 각 영역의 평균값을 계산하여 output을 계산
# 샘플 이미지 데이터 생성 (배치 크기 1, 채널 수 1, 크기 4x4) x = torch.tensor([[[[1.0, 2.0, 3.0, 4.0], [5.0, 6.0, 7.0, 8.0], [9.0, 10.0, 11.0, 12.0], [13.0, 14.0, 15.0, 16.0]]]]) # Adaptive 평균 풀링 레이어 정의 adaptive_avg_pool = nn.AdaptiveAvgPool2d(output_size=(2, 2)) # Adaptive 평균 풀링 적용 output = adaptive_avg_pool(x) print("Adaptive Average Pooling Output:\n", output) # 출력: tensor([[[[ 3.5, 5.5], # [11.5, 13.5]]]])
2. 활성화 함수
비선형 활성화함수로 다양한 유형의 함수를 제공함
활성화 함수는 torch.nn.functional에서도 제공하고 있는데, torch.nn에서 제공하는 것과 nn.functional에서 제공하는 것의 차이는 다음과 같음.
1. torch.nn 모듈의 활성화 함수는 클래스 형태로 정의되어 있고, 클래스 객체를 초기화하여 사용함 -> 네트워크 구조를 정의할 때 레이어 정의를 더욱 명확하고 직관적으로 함. 즉, 신경망 레이어를 정의할 때 활성화함수 레이어를 추가할 경우에 torch.nn에서 꺼내어 사용
import torch.nn as nn
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(20, 10)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 모델 초기화
model = NeuralNetwork()
2
2. 반면, torch.nn.functional은 함수를 직접 호출하여 사용 자체는 유연하게 가능하지만 객체로 정의되지 않아서 레이어 정의 상으로는 명확하지 않을 수 있음
이에 따라, torch.nn.functional의 활성화 함수는 주로 def forward를 정의하면서 활성화함수를 직접 호출할 때 사용 가능함
이는 활성화 함수뿐 아니라 다른 합성곱 레이어, 풀링 레이어도 마찬가지임
import torch.nn.functional as F
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.fc1 = nn.Linear(10, 20)
self.fc2 = nn.Linear(20, 10)
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
return x
model = NeuralNetwork()
- nn.Relu
- nn.Tanh
- nn.Sigmoid
- nn.LeakyReLU
...
3. 손실함수
앞선 경우와 유사하게 torch.nn에서 호출하는 손실함수는 클래스 형태로 정의되어 손실함수 객체를 생성함
import torch
import torch.nn as nn
criterion = nn.CrossEntropyLoss() # 손실함수 객체 생성
output = torch.randn(10, 5)
target = torch.randint(0, 5, (10,))
loss = criterion(output, target) # 손실함수 객체를 호출하여 손실값 계산
반면, torch.nn.functional에서 호출한 손실함수는 직접 손실 값을 바로 계산하기 위함
import torch
import torch.nn.functional as F
output = torch.randn(10, 5)
target = torch.randint(0, 5, (10,))
loss = F.cross_entropy(output, target) # 직접 손실함수를 호출하여 계산
- nn.CrossEntropyLos
- nn.MSELoss
- nn.L1Loss : MAE
...
4. 컨테이너
여러 레이어를 한데 모아 효과적으로 관리하고 신경망을 구축하는 데 사용함
-
nn.Sequential
- 여러 레이어를 순차적으로 적용하는 단순한 형태의 컨테이너- 레이어를 순서대로 쌓아올리는 신경망을 정의할 때 유용함
- forward 메서드를 따로 정의할 필요 없이, 주어진 순서대로 레이어를 적용하게 됨
import torch.nn as nn model = nn.Sequential( nn.Conv2d(1, 20, 5), nn.ReLU(), nn.Conv2d(20, 64, 5), nn.ReLU() ) # 또는 model = nn.Sequential() model.add_module('conv1', nn.Conv2d(1, 20, 5)) model.add_module('relu1', nn.ReLU()) model.add_module('conv2', nn.Conv2d(20, 64, 5)) model.add_module('relu2', nn.ReLU()) # 또는 layers = [ nn.Conv2d(1, 20, 5), nn.ReLU(), nn.Conv2d(20, 64, 5), nn.ReLU() ] model = nn.Sequential(*layers) -
nn.ModuleList
- 파이썬의 리스트와 유사하지만 리스트에 포함된 모듈을 관리하고, 모델의 파라미터로 자동 등록해줌- 순차적인 구조가 아닌 경우나, 반복되는 패턴을 정의할 때 유용
- forward 메소드를 직접 정의해야 함
import torch.nn as nn class MyModule(nn.Module): def __init__(self): super(MyModule, self).__init__() self.layers = nn.ModuleList([ nn.Conv2d(1, 20, 5), nn.Conv2d(20, 64, 5) ]) self.relu = nn.ReLU() def forward(self, x): for layer in self.layers: x = self.relu(layer(x)) return x model = MyModule()
-
nn.ModuleDict
- 파이썬의 딕셔너리와 유사하지만, 딕셔너리에 포함된 모듈을 관리하고, 모델의 파라미터로 자동 등록해 줌- 레이어에 이름을 부여하여 이름을 통한 접근이 가능
- 복잡한 네트워크 구조나 다양한 모듈을 체계적으로 관리할 때 유용함
import torch.nn as nn class MyModule(nn.Module): def __init__(self): super(MyModule, self).__init__() self.layers = nn.ModuleDict({ 'conv1': nn.Conv2d(1, 20, 5), 'conv2': nn.Conv2d(20, 64, 5), 'relu': nn.ReLU() }) def forward(self, x): x = self.layers['conv1'](x) x = self.layers['relu'](x) x = self.layers['conv2'](x) x = self.layers['relu'](x) return x model = MyModule()torch.nn을 공부하다보니 레이어를 왜 그렇게 구성하는지 공부를 많이 할 수 있었다.
배운 점 요약
-
Conv1d를 사용하는 이유, Input 데이터의 구조
- 시계열 데이터, NLP 등에서 사용
- input 데이터의 임베딩 차원과 kernel의 크기는 항상 동일하여 한 방향으로 움직임
- [Batch_size, feature_size(임베딩 차원), sequence_length]
-
TransposeConv1d 역합성곱 레이어의 역할과 대략적인 작동 원리
- Decoder에서 저차원 데이터를 고차원으로 해상도를 높이는 역할
- 작동원리는 합성곱의 역방향 진행 (역연산이 아님)으로 차원을 크게 하여 생성
-
torch.nn과 torch.nn.functional의 차이
- torch.nn의 레이어, 손실함수, 활성화 함수 등은 객체로 지정하여 신경망 레이어를 명확하게 하거나, 코드 가독성을 높이는 데 기여함
- torch.nn.functional은 함수를 직접 불러와 유연하게 사용하도록 함
-
nn.Sequential 등 container 함수를 사용하는 이유와 forward 메소드를 지정하거나 지정하지 않는 이유
- 여러 레이어를 한데 모아 효과적으로 관리하기 위함
- 특히, Sequential 레이어는 특수한 전처리나 복잡한레이어 구성이 요구되지 않는 경우 forward 메소드를 정의할 필요 없음
- forward 메소드는 데이터가 네트워크를 통해 어떻게 전달되는지 정의하기 위해 필요함 -> __init__ 메소드에서 정의한 레이어를 이용해 순차적으로 데이터에 연산을 적용하는 과정임
- forward 메소드를 지정하지 않는 경우: nn.Sequential과 같은 컨테이너를 사용할 경우 forward 메소드를 자동적으로 구성하여 따로 정의할 필요가 없음
- 다만, Sequential 함수를 썼음에도 굳이 forward를 쓰는 경우도 존재함.
- 예를 들어, 레이어 흐름이 복잡하여 특정 네트워크에서 다른 조건부 연산을 수행한다든가, 특정 입력 형태에 대해서 특수한 전처리가 필요한 경우가 있음
import torch import torch.nn as nn import torch.nn.functional as F class MyModel(nn.Module): def __init__(self): super(MyModel, self).__init__() self.layers = nn.Sequential( nn.Conv2d(1, 20, 5), nn.ReLU(), nn.Conv2d(20, 64, 5), nn.ReLU() ) self.fc1 = nn.Linear(64 * 4 * 4, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): # 특수한 전처리 x = x * 2 # 예를 들어, 입력을 두 배로 스케일링 x = self.layers(x) x = x.view(x.size(0), -1) # Flatten the tensor x = self.fc1(x) x = F.relu(x) x = self.fc2(x) # 특수한 후처리 x = F.softmax(x, dim=1) return x # 모델 초기화 model = MyModel()
