
torch에서 주로 쓰이는 모듈은 대략적으로 살펴보았다.
()
이제 torchvision에서 주로 쓰이는 모듈을 알아보고자 한다.
주요 모듈
- torchvision.datasets
다양한 이미지 데이터셋을 손쉽게 로드할 수 있는 모듈
- MNIST
- CIFAR10 / 100
- ImageNet
- FashionMNIST
- COCO: 객체탐지/세그멘테이션/캡셔닝 태스크용 데이터셋
-
torchvision.transforms
이미지 데이터 전처리, 증강을 위한 변환 기능 제공 -
torchvision.models
pre-trained 모델을 제공함
- ResNet, AlexNet, VGG, 등등 ...
- torchvision.utils
이미지 관련한 유용한 함수 제공
-
make_grid
여러 이미지를 하나의 그리드 이미지로 만듦
이미지 배치를 시각화할 때 주로 사용 -
save_image
텐서 이미지를 저장
주로 학습 중간/이후에 이미지 결과를 저장할 때 사용
기타 모듈
-
torchvision.io
이미지 및 비디오 파일의 읽기와 쓰기를 위한 기능 제공
이미지를 텐서로 변환, 텐서를 파일로 저장할 수 있음 -
torchvision.ops
컴퓨터 비전 작업에 유용한 연산 제공 (중복된 경계 상자 제거 등)
당장에는 잘 안 쓸 듯
torchvision.transforms
torchvision의 transforms 모듈은 PyTorch의 이미지 데이터 전처리 및 데이터 증강을 위한 다양한 변환 함수를 제공하는 모듈이다.
이 모듈은 이미지 데이터를 텐서로 변환하거나,
이미지의 크기를 조정하거나, 색상 변환, 자르기 등의 작업을 쉽게 수행할 수 있도록 한다.
이러한 변환 함수들은 일반적으로 transforms.Compose라는 함수를 사용하여 순차적으로(sequentially) 적용이 가능하다.
torchvision은 2023년 기존의 transforms보다 더 유연하고 강력한 데이터 전처리 및 증강 기능을 제공하는 torchvision.transforms.v2를 사용하기를 권장하고 있다.
torchvision.transforms.v2의 장점
-
기존의 이미지 관련한 기능에 더해, bounding boxes, masks, video 등에 대한 변환도 가능한 기능을 제공 (객체탐지, 세그멘테이션, 비디오 분류 등에 활용 가능)
-
CutMix, MixUp과 같은 변환 기능을 제공
-
빠른 속도
-
기존의 v1 함수들을 완전히 호환되도록 만들어 import문만 v2로 바꾸면 사용 가능
사용 예시
from torchvision.transforms import v2
transforms = v2.Compose([
v2.ToImage(), # Convert to tensor, only needed if you had a PIL image
v2.ToDtype(torch.uint8, scale=True), # optional, most input are already uint8 at this point
# ...
v2.RandomResizedCrop(size=(224, 224), antialias=True), # Or Resize(antialias=True)
# ...
v2.ToDtype(torch.float32, scale=True), # Normalize expects float input
v2.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])이처럼 Compose 함수를 활용해 순차적으로 처리하고자 하는 이미지 관련 변환을 지정할 수 있다.
저장된 transforms는 torch.utils.data.DataLoader의 parameter로서 사용하면 자동적인 이미지 변환을 순차적으로 진행한다.
transforms.v2의 주요 함수
v2에서는 크게 다음과 같은 9개 기능으로 나눌 수 있다.
- Resizing (사이즈 조절)
- Cropping (자르기)
- Color (색 변환)
- Other transform (기타 변환)
- Composition
- Normalize (텐서 정규화)
- Conversion (형식 변환)
- Auto-Augmentation (자동 이미지 증강)
- CutMix - MixUp
1. Resizing
Resize는 이미지의 픽셀 크기를 변경하는 것이다.
다만, 가로 * 세로 비율을 유지하느냐, 유지하지 않느냐의 차이가 있다.
비율 유지 X : Resize
비율 유지 O : ScaleJitter, RandomResize
-
v2.Resize(size): 이미지 픽셀 크기를 조정
이미지 자체는 유지하되 눌리거나 늘어난 모습이 됨
-> 정방형의 경우는 해상도가 차이나는 것처럼 보임예시 코드)
resized_img = v2.Resize((128, 128))(image)

-
"출처 논문: Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation"v2.ScaleJitter(target_size = (int, int), scale_range = (float, float)): 이미지의 크기를 동일한 크기로 맞춰서 input size를 단일화 시키기 위해서 이미지의 크기를 조정하거나 잘라내는 방법(이미지 증강용)

-
하지만 논문에서 얘기한 것과 다르게 ScaleJitter 함수를 쓰면, 랜덤한 픽셀 크기를 갖는 것 같다;
예시 코드)
jitterd_img = v2.ScaleJitter(target_size = (64, 64), scale_range = (2.0, 2.0))(image)
긴 쪽을 기준으로 target_size에 비율을 유지하면서 맞추되, scale_range를 랜덤하게 적용하는 느낌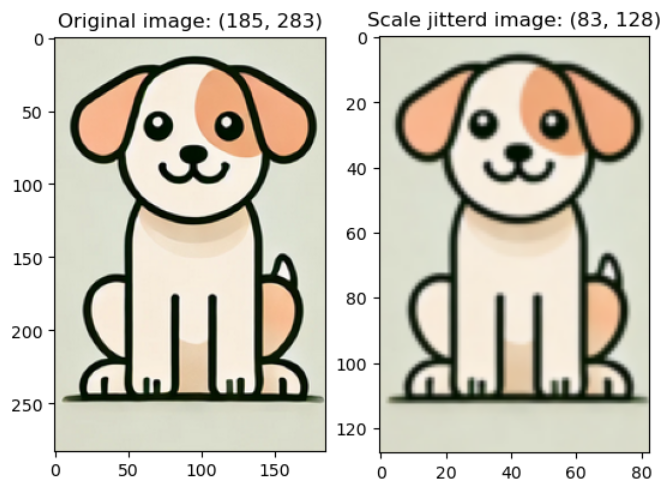
내가 잘못 이해한 건가
-
-
v2.RandomShortestSize(min_size): 이미지의 짧은 쪽의 길이를 주어진 범위(min_size, max_size) 내에서 무작위로 선택된 값으로 조정.
이미지의 비율을 유지하면서 크기를 조정하는데 사용 (이미지 증강용)
예시 코드)random_shortest_img = v2.RandomShortestSize(min_size = 10, max_size = 50)(image)
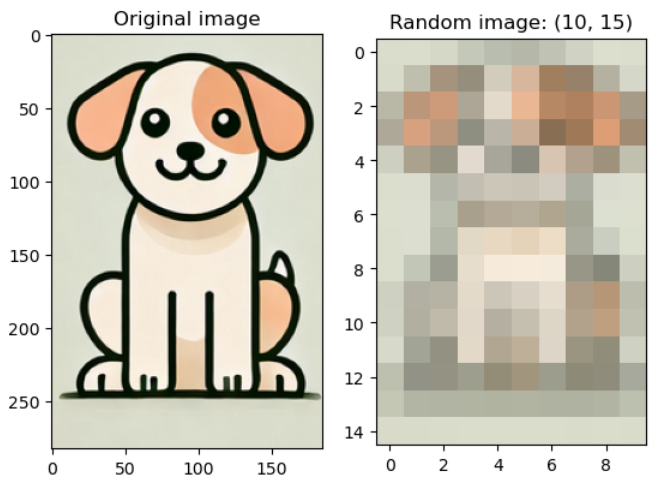
-
여기서도 좀 이상한게, random 하지가 않다.
-
그리고 max_size 파라미터가 적혀있어서 써봤지만 어디에 관여하는지를 모르겠다;
-
v2.RandomResize(min_size = (h, w), max_size = (h, w)): 주어진 크기 범위 내에서 무작위로 선택된 값으로 이미지 크기를 조정. 이미지 비율이 변경될 수 있음 (이미지 증강용)
예시 코드)random_resize_img = v2.RandomResize(min_size = 30, max_size = 256)(image)
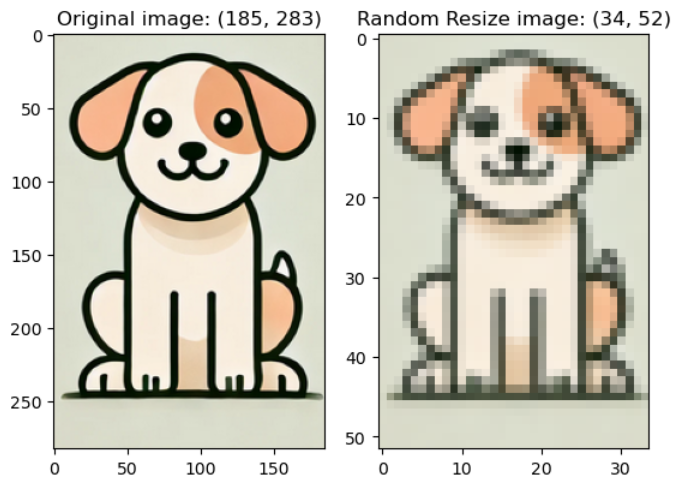
- min_size와 max_size 범위에서 랜덤한 픽셀크기를 선택한다.
2. Cropping
v2.RandomCrop(size): input data를 랜덤한 위치로 자름. size 크기에 맞게 자름
예시 코드) randomcrop_img = v2.RandomCrop((50, 50))(image)
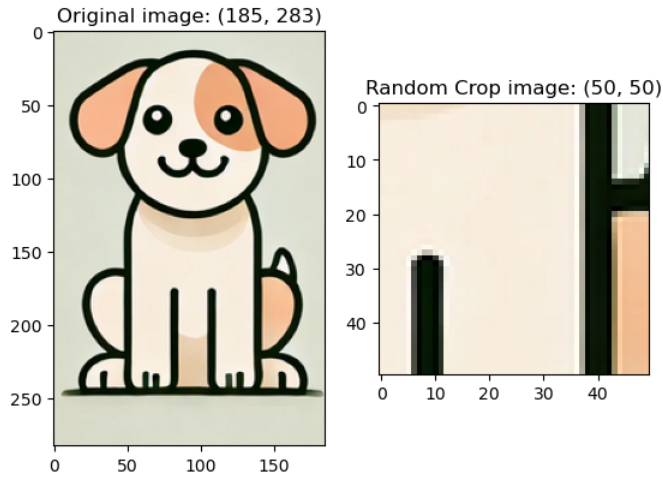
매 시행마다 랜덤한 위치를 선택하여 이미지를 자른다.
v2.RandomResizedCrop(size, scale, ratio): 전체 이미지 영역 중 scale 범위 중에 랜덤한 수치만큼의 면적 비율을 갖게끔 이미지를 잘라내고, (이때 ratio로 잘라낼 영역의 너비와 높이 비율을 설정) 그 후에 size 크기로 resize함
예시 코드) randomresizedcrop_img = v2.RandomResizedCrop((100, 100), scale = (0.2, 0.2))(image)
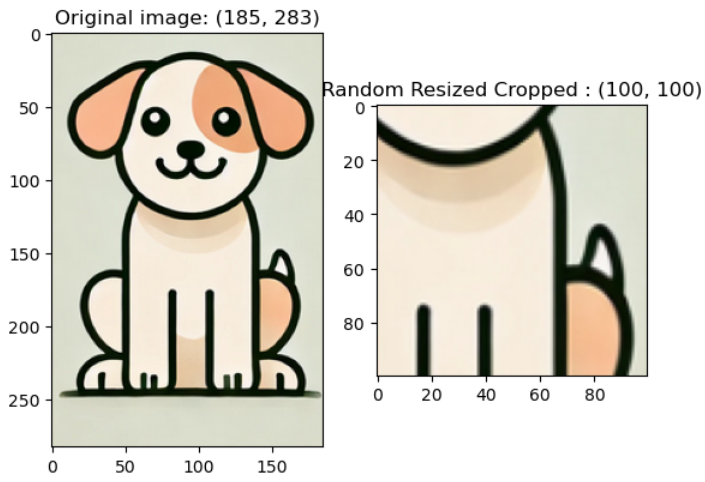
v2.CenterCrop(size): 이미지의 중심점을 포함하도록 size 크기로 crop함
예시 코드) centercrop_img = v2.CenterCrop((160, 100))(image)
나머지 부분은 포스팅을 나눠서 작성해야겠다.
