저번 포스팅에 이어서 torchvision의 transforms 모듈에 대해서 조금 더 자세히 알아보자. (지난 포스팅 - transforms1)
3. Color
Color 관련 기능은 말 그대로 색과 관련한 변형을 진행한다.
굉장히 많은 함수가 존재하는데, 이 중에서 가장 빈번하게 쓰일 것만 언급하는 것이 맞는 것 같다.
ColorJitter와 GrayScale 정도만 언급하면 될 것 같고, 나머지 함수는 필요에 따라 공부를 추가적으로 하면 될 것 같다.
-
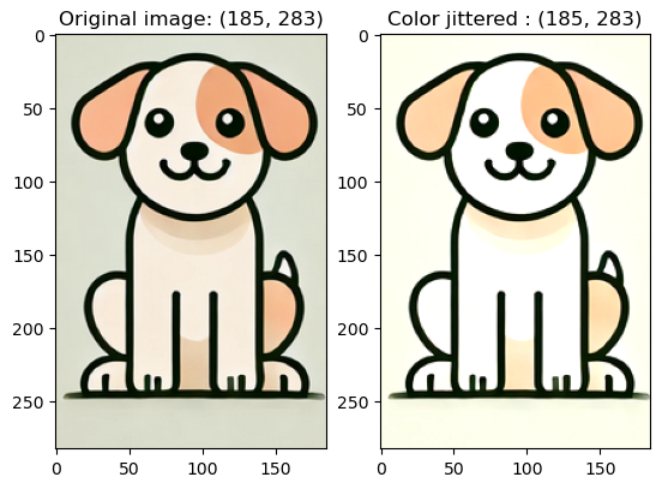
v2.ColorJitter(brightness, contrast, saturation, hue): 이미지의 밝기, 대비, 채도, 색조를 각각 랜덤하게 변환하는 함수입력한 파라미터에 대해서만 랜덤하게 선택해준다.
- brightness (밝기)
예시 코드)
colorjitter_img = v2.ColorJitter(brightness = (0, 1), contrast = (1, 1), saturation = (1, 1), hue = 0)(image)- contrast (대비)
예시 코드)
colorjitter_img = v2.ColorJitter(brightness = (1, 1), contrast = (0, 1), saturation = (1, 1), hue = 0)(image)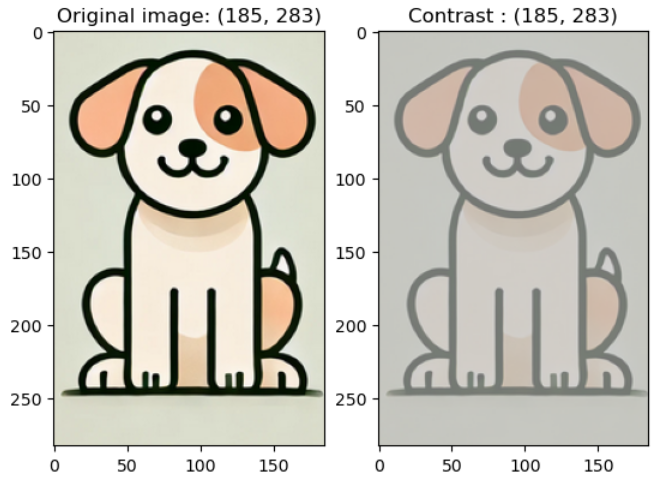
- saturation (채도)
예시 코드)
colorjitter_img = v2.ColorJitter(brightness = (1, 1), contrast = (1, 1), saturation = (0, 1), hue = 0)(image)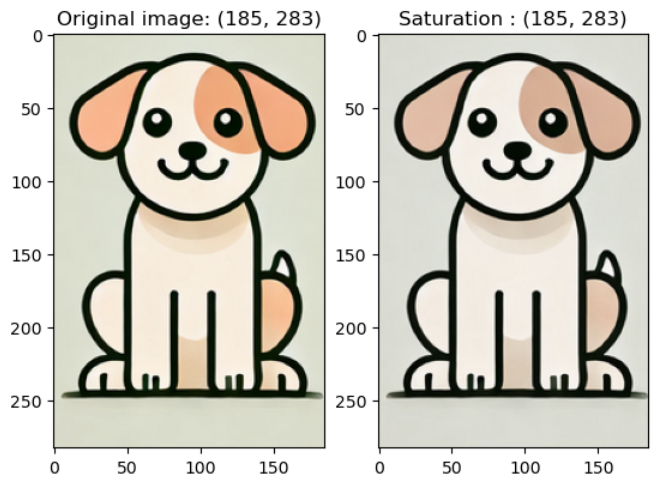
- hue (색조) : 실험해보니 0.5하면 B, 0.4하면 R, 0.3하면 G 색조가 강조됨
예시 코드)
colorjitter_img = v2.ColorJitter(brightness = (1, 1), contrast = (1, 1), saturation = (1, 1), hue = 0.5)(image)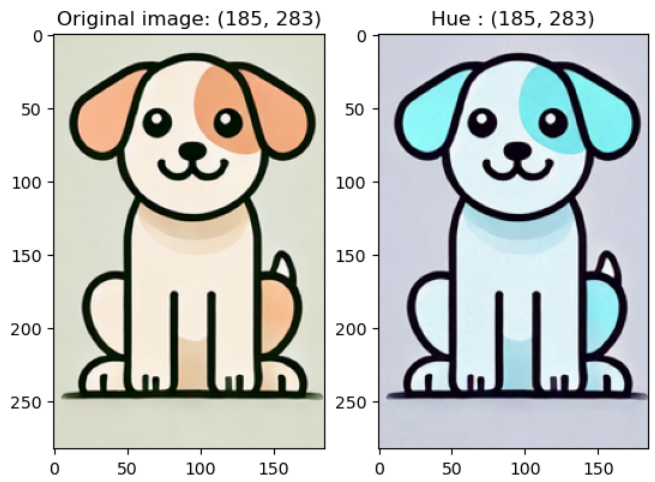
예시 코드)
colorjitter_img = v2.ColorJitter(brightness = (1, 1), contrast = (1, 1), saturation = (1, 1), hue = 0.4)(image)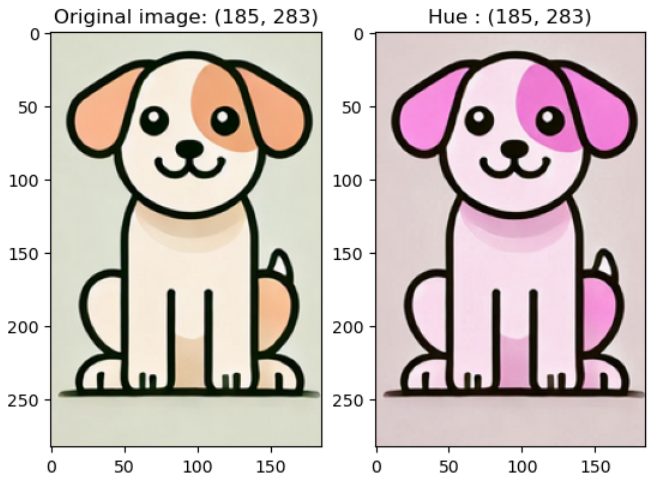
예시 코드)
colorjitter_img = v2.ColorJitter(brightness = (1, 1), contrast = (1, 1), saturation = (1, 1), hue = 0.3)(image)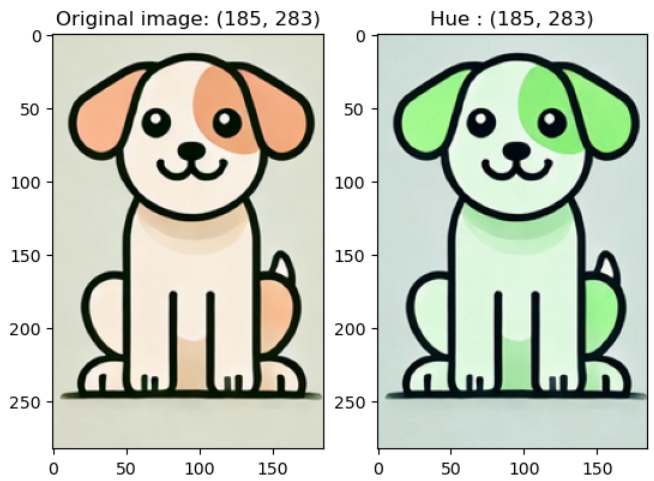
v2.GrayScale(num_output_channels): 컬러 이미지를 단일 채널로 변환하여 색상 정보 없는 이미지 데이터를 학습 제공
num_output_channels는 출력 이미지의 채널 수를 지정하는 것 (1 or 3만 가능)
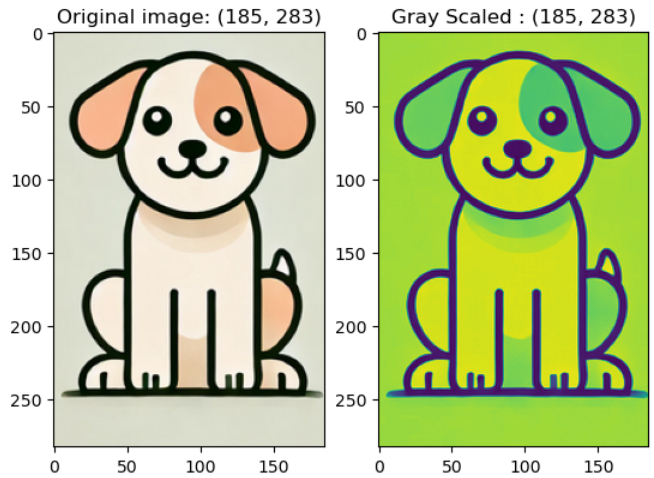
1로 지정하면 단일 채널 그레이스케일 이미지가 생성되는데, 회색이 되는게 아니라 RGB 색상 중 하나가 강조됨.
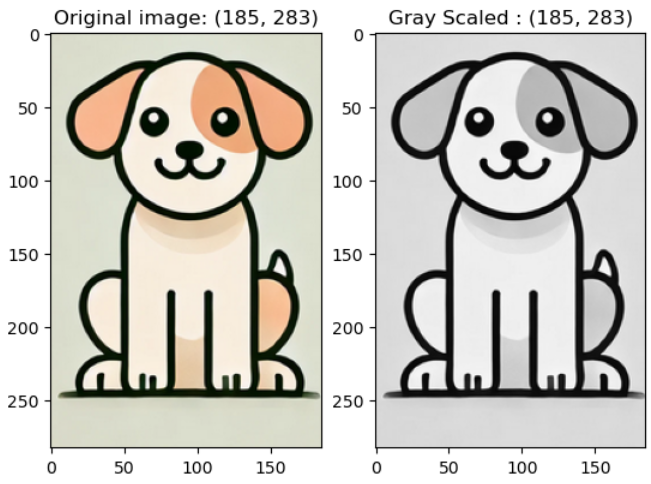
3으로 지정하면 회색으로 변환됨
예시 코드) grayscale_img = v2.Grayscale(1)(image)
예시 코드) grayscale_img = v2.Grayscale(3)(image)
4. Other Transform
PyTorch 공식문서에서 기타로 분류해둔 변환 기능들이 있다.
바로 뒤집기, 회전, 패딩, Affine 등이다.
v2.RandomHorizontalFlip(p): p 확률에 따라 좌우 뒤집기를 실시
확률에 따라, 뒤집기를 할 수도 안 할 수도 있음
예시 코드) horizontalflip_img = v2.RandomHorizontalFlip(0.5)(image)
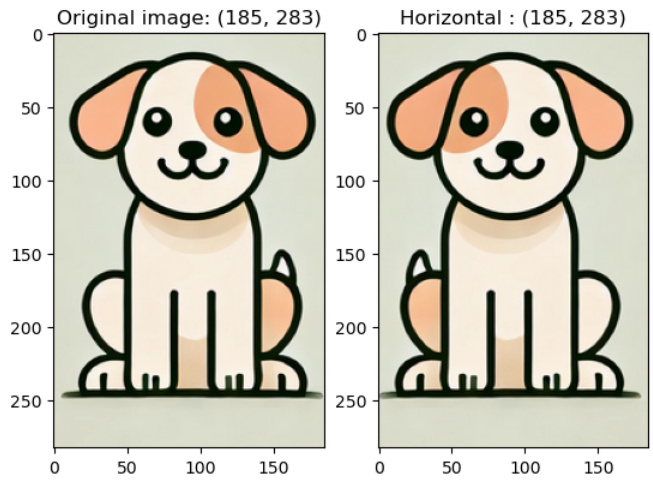
v2.RandomVerticalFlip(p): p 확률에 따라 상하 뒤집기를 실시
예시 코드) verticalflip_img = v2.RandomVerticalFlip(0.5)(image)
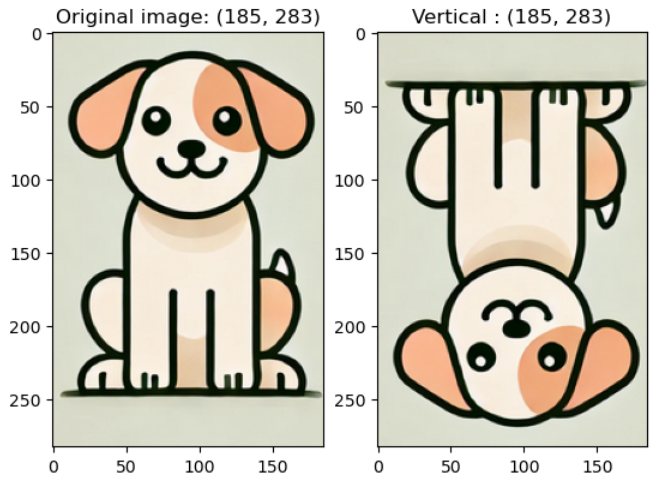
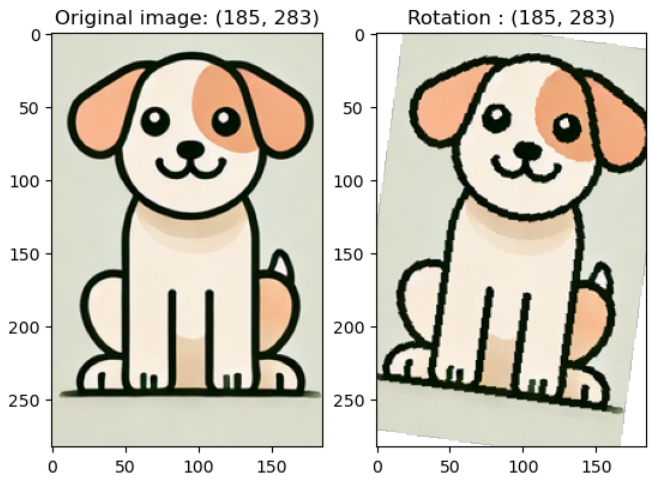
v2.RandomRotation(degrees): -degree ~ degree 사이 각도 중 랜덤한 수치만큼 이미지를 회전
예시 코드) rotate_img = v2.RandomRotation(45)(image)
-
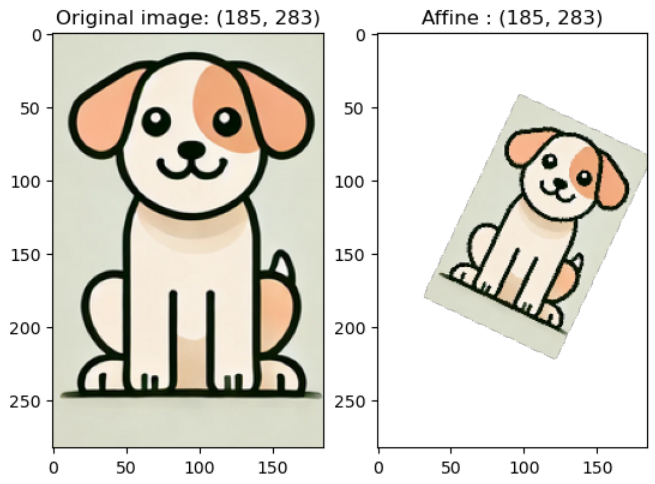
v2.RandomAffine(degrees, translate, scale): 이미지를 기하학적으로 변환하는 아핀 변환 실시각도, 평행이동, 크기 조정 등을 지정할 수 있음
예시 코드) affine_img = v2.RandomAffine(degrees = 45, translate = (0.1, 0.2), scale = (0.5, 0.6))(image)
-
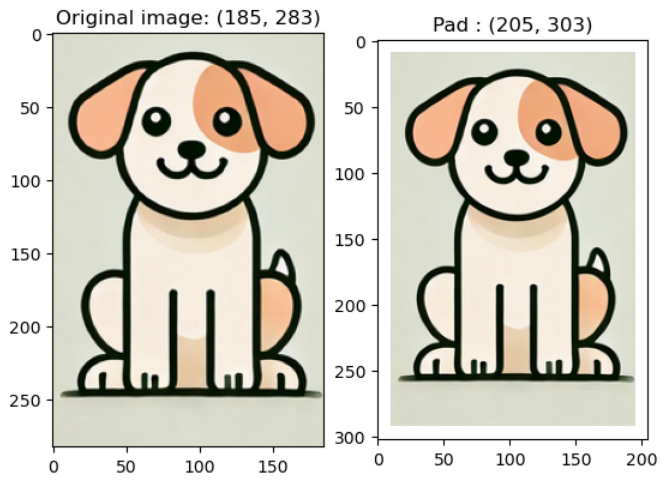
v2.Pad(padding): 이미지의 네 경계에 대해서 0 패딩padding에 입력한 수치만큼 채워넣음
예시 코드) padding_img = v2.Pad(10)(image)
5. Composition
여러 transform 함수를 모두 사용하여 변환을 진행하고 싶을 때, 순차적으로 이를 실시할 수 있도록 묶어주는 함수가 있다.
v2.Compose([list]): 리스트 안에 입력한 변환 함수를 순서대로 실행
예시 코드)
transforms = transforms.Compose([
v2.CenterCrop(10),
v2.ConvertImageDtype(torch.float)
])
6. Normalize
이미지 데이터의 전처리 과정에서 주요 사용하는 Normalizae 함수가 있다.
모델 훈련 전에 이미지 데이터셋을 정규화하여 각 채널의 데이터 분포를 표준화함으로써 모델이 학습할 때, 데이터의 스케일 차이로 인한 영향을 줄일 수 있다.
이로써 신경망이 더욱 빠르고 안정적으로 수렴하도록 돕는 역할을 한다.
v2.Normalize(mean, std): 입력한 mean, std로 표준화를 수행
# 이미지를 텐서로 변환
transform_to_tensor = v2.ToImage()
image_tensor = transform_to_tensor(image)
image_tensor = v2.ToDtype(dtype = torch.float32)(image_tensor) # float type이어야 계산이 돼서 변환
#각 채널의 평균과 표준 편차 계산
mean = torch.mean(image_tensor, dim=[1, 2])
std = torch.std(image_tensor, dim=[1, 2])
# Normalize 변환 정의 (mean과 std를 사용하여 정규화)
normalize = v2.Normalize(mean=mean, std=std)
# 정규화 적용
normalized_tensor = normalize(image_tensor)
몇 가지 알아야 할 점
-
표준화하기 전에는 0~255값을 가지므로 이를 표준화하여 스케일 영향을 줄임
-
이 작업을 위해서는 image를 tensor로 변환 (
v2.ToImage())
-> float32로 변환 (v2.ToDtype(dtype = torch.float32)
-> 채널별 평균, 표준편차 계산 (torch.mean(tensor, dim = [1, 2]) ※ 이 dim은 채널별 높이, 너비의 평균을 구하기 위해 차원을 [0, 1, 2]중 [1, 2]에 대해서만 평균을 구하라고 설정한 것 0은 채널 1은 높이 2는 너비에 해당
-> mean, std로 표준화 (v2.Normalize(mean, std))
7. Conversion
위에서 살펴본 것처럼 이미지를 텐서화할 때가 있고, 적절한 dtype 형식으로 바꿔줘야 하는 기능이 필요한데 이 역시 transforms 모듈에서 지원한다.
-
v2.ToImage(): 이미지 데이터를 텐서로 변환함. 참고로v2.ToTensor()는 더이상 사용하지 않음 -
v2.PILToTensor(): PIL (파이썬 기본 이미지 관련 라이브러리)로 불러온 이미지를 텐서로 변환 -
v2.ToDtype(dtype = torch.형식): 명시한 dtype으로 변환해줌
8. Auto-Augmentation
PyTorch에서 제공하는 훌륭한 기능 중 하나로, 이미지 데이터를 자동으로 증강하여 모델 성능 향상에 기여하는 데에 사용된다.
말 그대로, 단 한 줄로 증강이 적용되어 이미지에 대한 일련의 무작위 변환을 적용해주어 편리하다.
또한, IMAGENET, CIFAR10 등 각 데이터셋에 맞는 최적의 증강 방법이 미리 정의되어 있는데, 이 정책(policy)에 따라 데이터 증강을 수행한다.
(대강 policy를 읽었을 때 심각한 수준으로 crop하는 등 무리한 변환은 하지 않는 것 같다.)
물론 단점도 있겠지만 PyTorch 공식문서에 따르면, ImageNet policy를 쓴 여러 데이터 셋에서 유의미한 성능 향상이 있었다고 한다.
이 방법을 사용할 수 있으면 조금 더 효율적으로 성능을 높일 수 있을 것 같으므로 알아두면 좋겠다.
v2.AutoAugment(policy): policy에 설정된 변환을 자동적으로 수행해 이미지를 증강한다.
예시 코드) transform = v2.AutoAugment(policy = v2.AutoAugmentPolicy.IMAGENET)

이 안에서도 확률적인 적용이 있는지, 몇 번의 시행에서는 Original 이미지와 동일한 이미지가 나왔다.
9. CutMix, MixUp
CutMix는 두 이미지 데이터를 합성하는 방법
MixUp은 두 이미지 데이터를 투명도를 주어 섞는 방법
두 방법 모두 Label를 0, 1이 아닌 여러 클래스에 대해서 확률적으로 섞어서 부여한다.
그리고 이를 자동적으로 수행할 수 있도록 torchvision에서는 지원하고 있다.
이를 사용하기 위해서는 약간의 복잡한 과정을 이해해야 해서 다음에 다루도록 한다.
