

Monster 객체

몬스터는 체력(healthPoint)과 레벨(level), 서식지(habitat) 속성을 가지고 있으며, 레벨을 1단계 올릴 수 있는 메소드(levelUp)을 가지고 있다. 이 특성들은 모든 몬스터들이 가지는 특성이므로 몬스터라는 클래스의 속성으로 부여해 줄 수 있다.
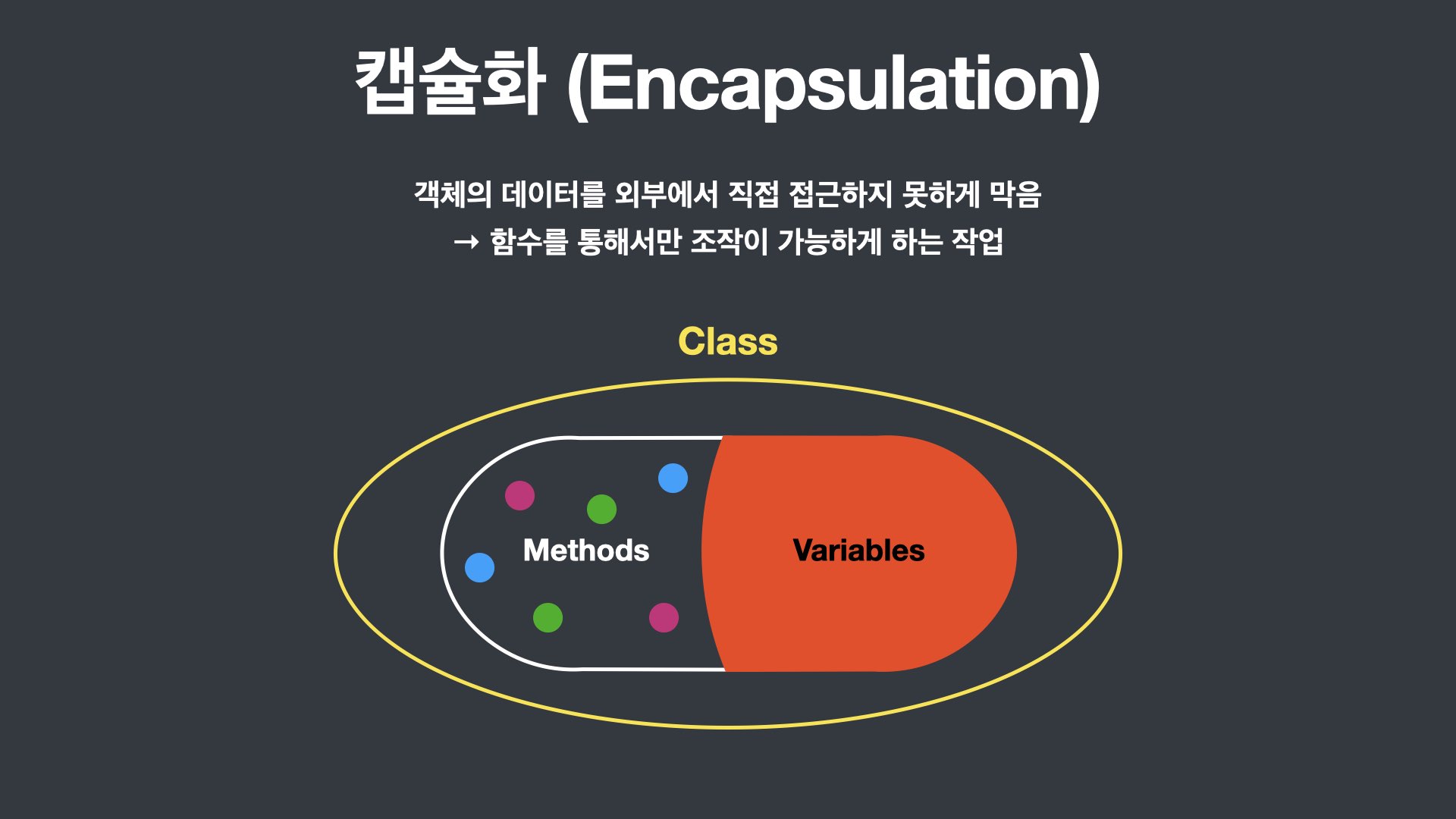
캡슐화 (Encapsulation)
캡슐 알약을 보면 캡슐 안에 필요한 약 성분들을 담아 내용물이 보이지 않게 하는데 이는 객체 내부에서 필요로 하는 정보를 은닉하는 캡슐화를 잘 표현해주고 있다.
절차 지향에서는 요구 변경 시 많은 코드의 수정이 필요하다. 그러나 객체 지향에서는 클래스로 만들어 모듈화해서 요구 변경에 대한 클래스 안에 메소드만 추가하여 사용자가 추가된 기능을 사용할 수 있게 만들어 이로 인해 코드의 수정이 최소화된다는 장점이 있다.

캡슐화는 객체의 데이터를 외부에서 직접 접근하지 못하게 막고, 함수를 통해서만 조작이 가능하게 하는 작업이다. 몬스터의 레벨(level)과 같은 경우는 이용자가 임의로 조작하게 하면 문제가 생길 가능성이 있다. 그래서 레벨업(levelUp)이라는 함수를 통해서만 레벨이 조작되어야 한다.
코드를 보면 외부에서 level변수에 직접 접근하지 못하도록 막는 캡슐화를 나타내고 있는데 이전의 몬스터 객체처럼 monster.level로 몬스터의 level데이터에 접근할 수 없게 되었다. level은 오직 monster.levelUp이라는 메소드(method)로만 조작할 수 있게 되는 것이다.
접근 제한자

이처럼 캡슐화는 접근제한자를 주어서 외부에서 데이터에 접근하는 것을 방지하고 받고자 하는 것들을 클래스로 만들어 반환하여 오로지 함수를 통해서만 접근할 수 있게 만드는 것을 말한다. 여기서 접근 제한자에는 접근 허용 정도에 따라 순서대로 public, protected, default, private가 있는데 public은 모든 접근을 허용하고, protected는 default + 상속관계인 다른 패키지의 클래스, default는 같은 패키지만, private는 같은 클래스에서만 접근을 허용한다.

캡슐화의 두가지 관점에는 데이터 캡슐화와 은닉화가 있는데 데이터 캡슐화는 객체의 상태와 행동을 하나의 단위로 묶는 자율적 실체를 말하고 은닉화는 외부에서 객체의 상태를 변경할 수 없도록 숨기는 것을 말한다.
정보 은닉
캡슐화를 하는 중요한 목적은 바로 정보 은닉인데 이는 필요가 없는 정보는 외부에서 접근하지 못하도록 제한하는 것으로 private 키워드를 사용한다. 이렇게 보호된 변수는 getter나 setter 등의 메서드를 통해서만 간접적으로 접근이 가능하도록 하는 것이 캡슐화의 중요한 목적이다.
그렇다면 정보 은닉이 왜 필요할까? 은닉을 하지 않으면 객체의 상태 정보에 누구나 접근이 가능해지고 이것은 잘못된 데이터가 들어갈 수 있다는 의미이다. 이를 방지하기 위해 정보 은닉은 꼭 필요하게 되는 것이다. 그럼 이런 생각을 할 수도 있다. 메서드를 사용하더라도 내가 잘못된 데이터를 넣을 수 있지 않을까? 물론 그럴 수 있다. 하지만 메서드를 사용했기 때문에 잘못된 데이터를 걸러낼 수 있으므로 메서드를 사용하지 않을 때와는 다르게 된다.
추상화 (Abstraction)
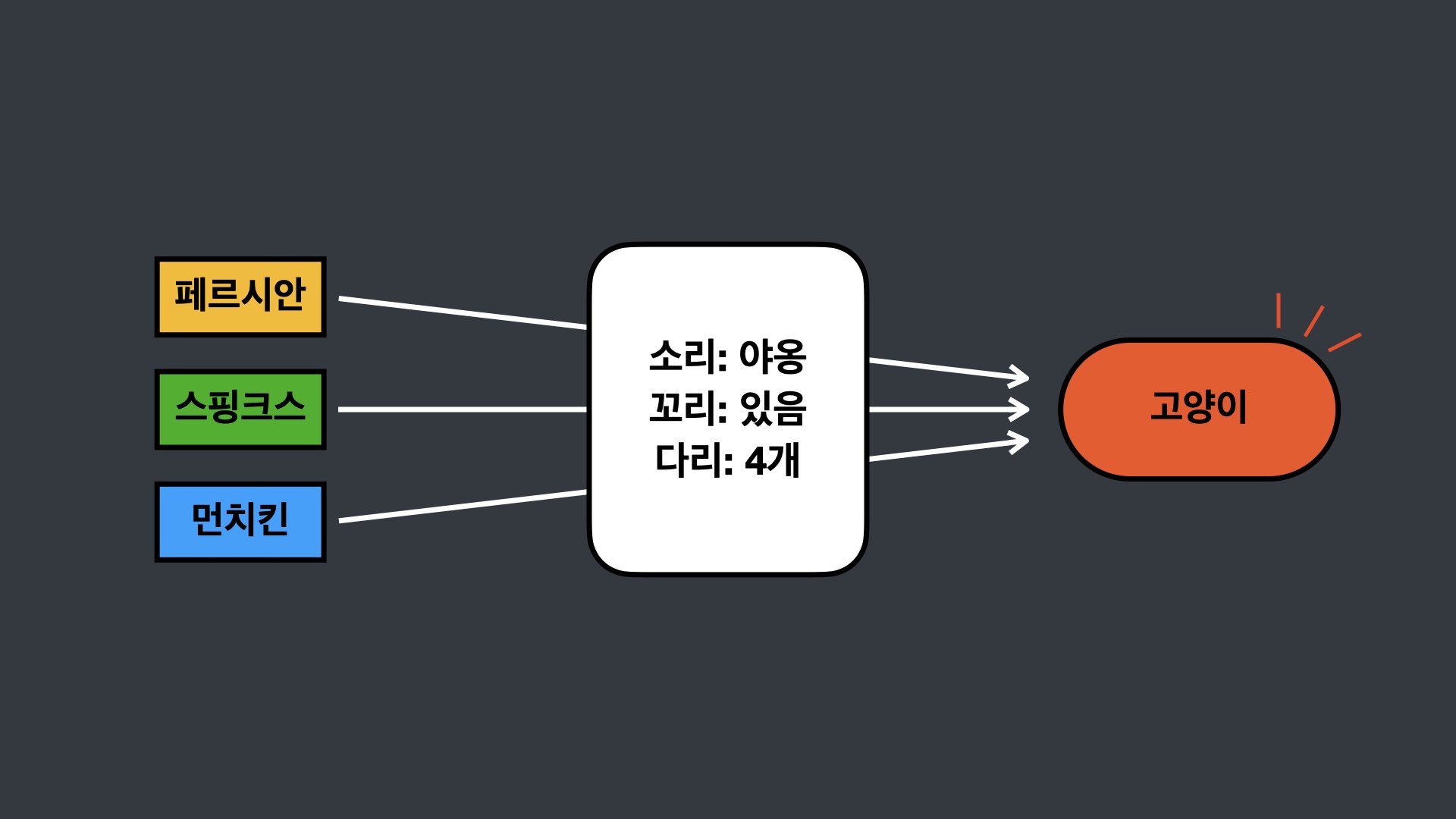
추상화의 사전적 의미는 특정한 개별 사물과 관련되지 않은 공통된 속성이나 관계 등을 뽑아내는 것이다. 앞에 보이는 페르시안, 스핑크스, 먼치킨은 고양이의 종류이다. 이들은 공통적으로 야옹하는 소리를 내고 꼬리가 있고 다리가 네개이다. 우리는 이를 고양이라는 클래스로 추상화할 수 있다. 이를 컴퓨터의 관점에서 생각해보면 추상화란 데이터나 프로세스 등을 의미가 비슷한 개념이나 표현으로 정의해나가는 과정이면서 동시에 각 개별 개체의 구현에 대한 상세함은 감추는 것이라고 할 수 있다.
즉, 추상화는 객체들이 가진 공통의 특성들을 파악하고 불필요한 특성들을 제거하는 과정을 말한다. 객체들이 가진 동작들을 기준으로 이용자들이 동작만 쉽게 구동할 수 있도록 한다. 몬스터 예제에서 레벨업(levelUp) 메소드를 실행만 하면 level이라는 속성을 컨트롤 할 수 있었던 것처럼 말이다. 이러한 추상화 과정을 통해 이용자들은 프로그래머가 만든 객체를 더 쉽게 사용할 수 있게 된다.

추상화를 할 때 주의할 점은 속성 위주가 아닌 동작 위주로 정의하는 작업을 하는 것인데 객체의 동작에 연관이 되지 않는 속성들은 결국은 불필요하다. 따라서 불필요한 속성들을 걸러내기 위해 동작을 먼저 정의하고 동작에 필요한 속성들을 정리하는 것이 좋다.
예를 들어, 몬스터들이 공격을 받아 healthPoint가 0이 되면 필드에서 죽은 것(death)으로 처리하고 싶다. 이용자들은 몬스터들을 공격하고 죽는 모습을 보기만 하면 되고 어떠한 과정을 거쳐서 몬스터가 죽었는지에 대해서는 알 필요가 없다. 이 상황에서는 앞의 몬스터 객체에 2가지 속성이 추가되어야 하는데 몬스터가 죽었는지 살았는지를 확인하는 속성과 healthPoint 라는 속성이다.
이제 몬스터는 체력(healthPoint)를 가지고 있고 데미지를 받아 체력이 깎이다가 체력이 0이 되면 죽는다. 이렇게 어떠한 동작과 속성을 정의하고 불필요한 정의들을 삭제하여 이용자가 편리하게 객체를 이용할 수 있도록 구성한 것이 추상화이다.
재사용성

OOP의 가장 큰 특성 중 하나가 바로 코드의 재사용성과 상속의 개념인데 같은 객체를 여러 개 만들어야 하는 경우, 한 번 작성된 코드를 활용하여 동일한 객체를 만들 수 있다는 것이다. 예를 들어 몬스터를 여러 마리 만들어야 하는데 각 몬스터들은 모두 같은 속성을 가지고 있을 때 몬스터 객체를 이용하여 모든 몬스터들이 같은 속성과 메소드를 가질 수 있도록 만들 수 있다.
상속 (Inheritance)
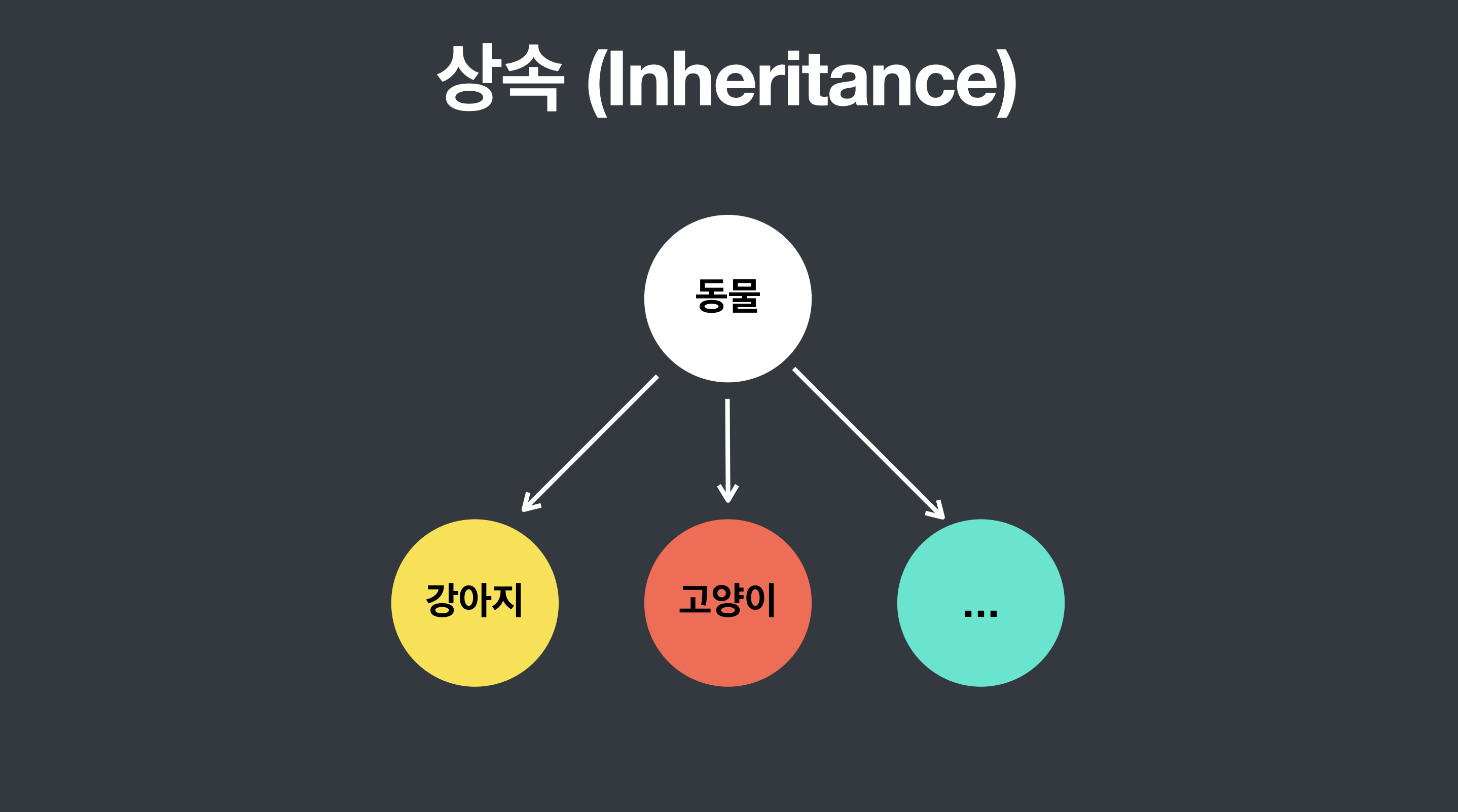
상속은 객체지향의 꽃이라고 할 수 있는데 이는 기존 상위클래스에 근거하여 새롭게 클래스와 행위를 정의할 수 있게 도와주는 개념이다. 즉 기존 클래스에 기능을 가져와 재사용할 수 있으면서도 동시에 새롭게 만든 클래스에 새로운 기능을 추가할 수 있게 만들어준다. 예를 들어 동물이라는 클래스의 속성을 강아지 클래스 또는 고양이 클래스가 물려받을 수 있다.
상속이 필요한 이유는 코드의 중복을 막을 수 있어 코드가 더 간단해지므로 유지보수가 수월해지기 때문이다. OOP에서는 상속을 통해 코드의 중복 문제를 일부 해결할 수 있는데 동물 클래스에 여러 속성들을 정의해 놓고 동물에 해당하는 종, 예를 들면 강아지 클래스가 필요한 경우 동물 클래스와 상속 관계를 맺는다. 상속 관계를 맺으면 자식 객체를 생성할 때 부모 클래스의 속성들을 자동으로 물려 받기 때문에 자식 클래스에서 또 정의할 필요가 없기 때문이다.
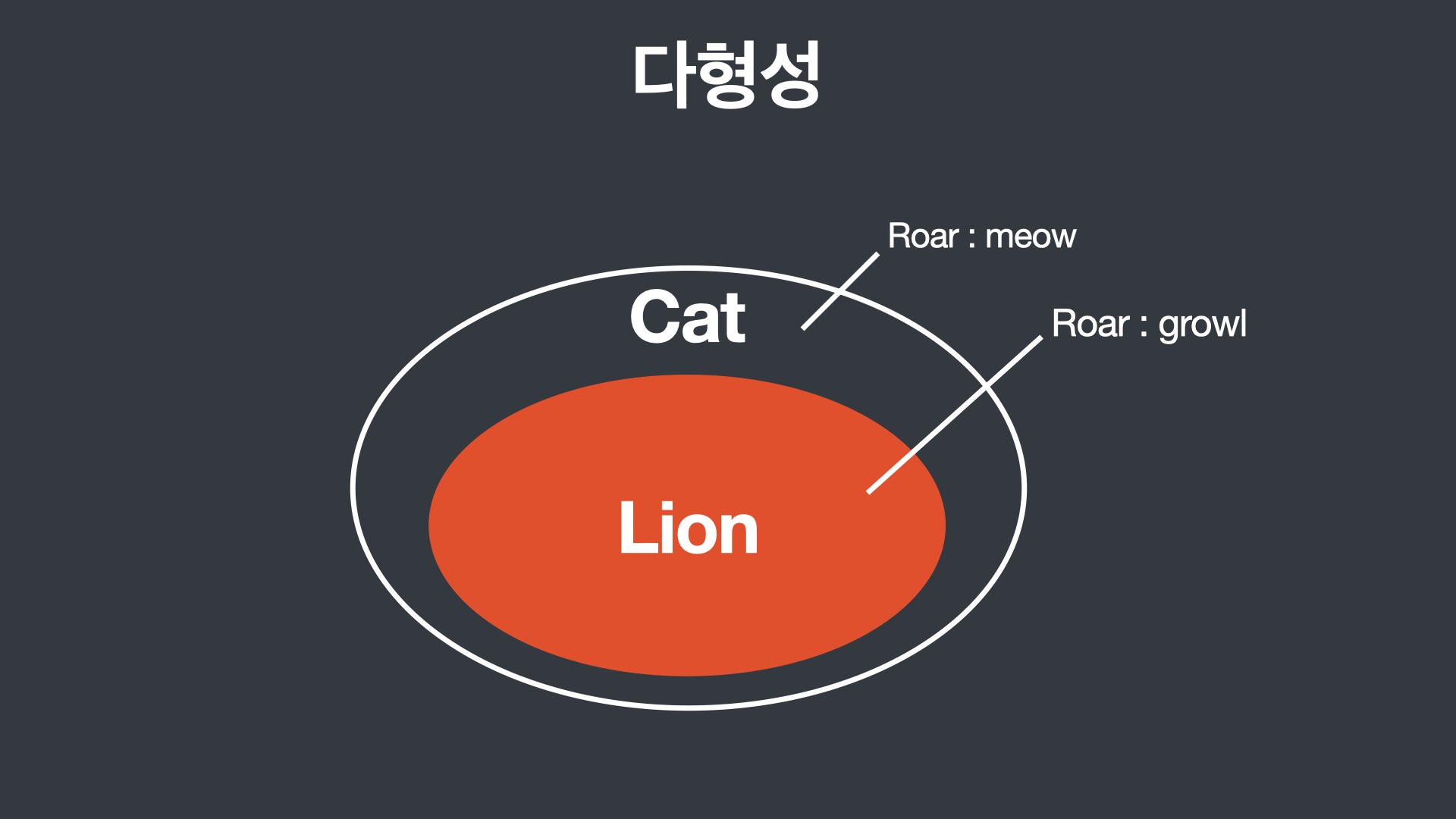
다형성 (Polymorphism)
다형성은 상속을 통해 기능을 확장하거나 변경하는 것을 가능하게 해준다. 즉 형태가 같은데 다른 기능을 하는 것을 의미한다. 이를 통해 코드의 재사용, 코드 길이 감소가 되어 유지보수가 용이하도록 도와준다.
예를 들면, 고양이 클래스에는 울음이라는 속성이 정의되어 있다고 하면, 사자는 고양이 과이기 때문에 사자 클래스가 고양이 클래스를 상속 받는다고 하면, 사자 클래스에도 "울음"이라는 속성이 자동으로 추가된다. 그런데 고양이와 사자의 울음소리는 다르다. 같은 "울음" 속성임에도 실제 울음소리는 다르다. 바로 이런 것을 다형성이라고 말할 수 있다.
OOP에서 다형성의 개념을 녹여내는 방법은 두 가지인데, 바로 오버라이딩(Overriding)과 오버로딩(Overloading)이다.
오버라이딩

오버라이딩은 부모 클래스에서 상속받은 자식 클래스에서 부모클래스에서 만들어진 메서드를 자식 클래스에서 자신의 입맛대로 다시 재정의해서 사용하는 것을 말한다.
위의 코드에서 employee 라는 클래스에서는 이름과 나이를 속성으로 가지고 있고 이를 상속받는 매니저 클래스에서는 employee 클래스에 있던 이름과 새로운 속성인 jobOfManagement를 이용해 재정의하여 사용합니다. 따라서 위의 경우 사원의 이름 홍길동, 나이 30이고 아래는 관리자 홍길동은 영업 담당입니다 라는 결과가 나오게 됩니다.
오버로딩

오버로딩은 같은 이름의 메서드를 사용하지만 메서드마다 다른 용도로 사용되며 그 결과물도 다르게 구현할 수 있게 만드는 개념이다. 오버로딩이 가능하려면 메서드끼리 이름은 같지만 매개변수의 갯수나 데이터 타입이 달라야 한다.
위의 코드에서 이름이 test인 메서드가 총 세 개 있지만 각각 매개변수의 유형과 개수가 다른 것을 볼 수 있는데 차례대로 매개변수가 없는 test, 매개변수가 string형인 test, 그리고 매개변수가 string형과 int형을 가지고 있는 test이다. 호출 시 매개변수를 입력하면 호출 매개변수에 따라 매칭되어 함수를 실행시켜준다. 따라서 결과는 사용자 없음, 사용자 이름은 홍길동, 사용자 이름은 홍길동 사용료는 5000이 되는 것이다.
그럼 다형성을 사용하면 좋은 점은 무엇인가 하면 같은 이름의 속성을 유지함으로서, 속성을 사용하기 위한 인터페이스를 유지하고, 메서드 이름을 낭비하지 않는다는 것이다. 예를 들어, 앞에서 보여줬던 고양이와 사자의 울음소리를 호출하기 위해서 각 객체에서 roar() 메서드를 호출하면 된다. roarCat(), roarLion()으로 각각을 정의할 필요가 없다는 것이다. API가 많아질수록 복잡성은 증가하기 때문에 다형성은 유용하다고 할 수 있다.
