
0. 공통
- 일단 저는 한솔데코라는 인테리어 회사의 신사업전략팀에서 LLM 모델 개발을 하고 있는 손승운 대리입니다.
- 앞으로 작성하는 글의 목적은 제가 직접 겪은 문제들을 기록하여 1. 앞으로 같은 문제가 발생했을 시 원활하게 해결하기 위함이 첫번째고, 2. 저와 같은 문제를 겪었을 다른 신입 개발자들에게 도움이 되는 정보를 제공하고자 함이 두번째 목적입니다.
1. 개요
- 금번 글은 제가 자사 데이터를 gemma-2b 모델에 적용했을때, 발생한 메모리가 부족 에러를 해결한 과정을 소개하겠습니다.
2. 자사 컴퓨팅 리소스
- 제가 사용하고 있는 컴퓨터의 gpu는 a6000 2대입니다.
3. gemma-2b란
- gemma-2b란 구글에서 공개한 LLM open model로 Gemma-2B와 Gemma-7B 2가지 모델로 출시했습니다.
- 현재 hugging face에서 간단한 등록을 거치면, 바로 사용할 수 있습니다.
4. 작업 문제점
- a6000 2대로 Gemma-7B는 커녕 Gemma-2B도 메모리가 부족하여 에러가 발생했습니다.
- 이를 해결하기 위해 배치사이즈를 조절할 수 있는 코드로 수정하는 등의 방법을 사용했지만 해결되지 않았습니다.
- lora, RAG 등 다른 방법론(?) 등을 고려해봤지만, 제 실력부족 이슈로 인해 실패했습니다.
5. 해결법
- 그러던 중 optimizer 부분에 지속해서 에러가 발생함을 확인하고 코드를 수정해봤습니다.
- 기존
optimizer = torch.optim.AdamW(model.parameters(), lr=CFG['LR'])인 코드를optimizer = AdamW(model.parameters(), lr=CFG['LR'])로 수정하니 아래 사진과 같이 아슬아슬하게 외줄타듯 학습되었습니다.
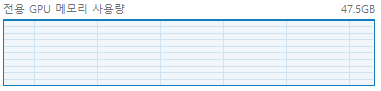 <작업 관리자의 gpu 사용량 - 파란색이 가득채워짐>
<작업 관리자의 gpu 사용량 - 파란색이 가득채워짐> - 아래는 수정전 코드와 수정한 코드입니다.
<수정 전> # 데이터 포맷팅 및 토크나이징 formatted_data = [] for _, row in tqdm(data.iterrows()): for q_col in ['질문_1', '질문_2']: for a_col in ['답변_1', '답변_2', '답변_3', '답변_4', '답변_5']: #질문과 답변 쌍을 </s> token으로 연결 input_text = row[q_col] + tokenizer.eos_token + row[a_col] input_ids = tokenizer.encode(input_text, return_tensors= 'pt') formatted_data.append(input_ids) print('Done.') # 모델로드 model = AutoModelForCausalLM.from_pretrained('google/gemma-2b').to(device) # 모델 학습 하이퍼파라미터(Hyperparameter) 세팅 # 실제 필요에 따라 조정 CFG = { 'LR' : 2e-5, # Learning Rate 'EPOCHS' : 1 # 학습 Epoch } # 모델 학습 설정 optimizer = torch.optim.AdamW(model.parameters(), lr=CFG['LR']) model.train() # 모델 학습 for epoch in range(CFG['EPOCHS']): total_loss = 0 progress_bar = tqdm(enumerate(formatted_data), total=len(formatted_data)) for batch_idx, batch in progress_bar: # 데이터를 gpu 단으로 이동 batch = batch.to(device) outputs = model(batch, labels = batch) loss = outputs.loss loss.backward() optimizer.step() optimizer.zero_grad() total_loss += loss.item()
<수정 후> # 데이터 포맷팅 및 토크나이징 formatted_data = [] for _, row in tqdm(data.iterrows()): for q_col in ['질문_1', '질문_2']: for a_col in ['답변_1', '답변_2', '답변_3', '답변_4', '답변_5']: #질문과 답변 쌍을 </s> token으로 연결 input_text = row[q_col] + tokenizer.eos_token + row[a_col] input_ids = tokenizer.encode(input_text, return_tensors= 'pt') formatted_data.append(input_ids) print('Done.') # 모델로드 model = AutoModelForCausalLM.from_pretrained('google/gemma-2b').to(device) # 모델 학습 하이퍼파라미터(Hyperparameter) 세팅 # 실제 필요에 따라 조정 CFG = { 'LR' : 2e-5, # Learning Rate 'EPOCHS' : 1 # 학습 Epoch } # 모델 학습 설정 optimizer = AdamW(model.parameters(), lr=CFG['LR']) model.train() # 모델 학습 for epoch in range(CFG['EPOCHS']): total_loss = 0 progress_bar = tqdm(enumerate(formatted_data), total=len(formatted_data)) for batch_idx, batch in progress_bar: # 데이터를 gpu 단으로 이동 batch = batch.to(device) outputs = model(batch, labels = batch) loss = outputs.loss loss.backward() optimizer.step() optimizer.zero_grad() total_loss += loss.item()

당신을 한 줄로 소개해보세요