Quantization은 Data precision을 낮춤으로써 parameter의 크기와 operation의 load를 낮추어 resource 부하를 줄이지만 대신 accuracy 측면에서는 quantized error로 인한 degradation 사이의 trade-off를 가지는 기술이다. 이 논문에서는 Quantization을 하되 최대한 accuracy degradation을 최소화할 수 있도록 Quantizer 자체에 learnable parameter를 추가해 Application에 최적화된 Quantizer로 학습되도록 하는 Redistribution-driven Learnable Qua
ntizer(RLQ)와 skip connection을 위한 learnable scaling을 두어 다양한 layer depth의 network architecture에 대해 동시에 train을 수행하게 하여 각 layer depth network에 대해 최적화된 parameter가 학습되도록 하는 Depth-dynamic Quantized Architecture(DQA)를 제안한다. 또한 이 두 기술을 적용하여 Super-resolution(SR) 응용에 특화된 QuantSR 모델을 제안한다.
Redistribution-driven Learnable Quantizer
Symmetric Quantizer를 수식으로 표현하면 다음과 같다.

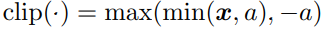
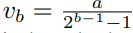
이때 b는 Quantizer Q의 bit-wdith이며, a는 x의 최대 절대값이다. v는 higher precision에서 lower bit reflection을 위한 scale값인 map function이다.
Discrete quantizer는 zero gradient를 가지므로, backward propagation을 위해 Straight-through estimator(STE)를 다음과 같이 근사시켜 사용한다.
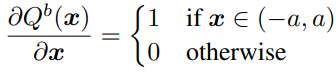
하지만 위 수식들에 따르면 homogeneous quantization mapping에 의해 x 값 분포와 상관없이 mapping이 되게 된다. 또한 Estimator의 gradient는 Quantizer의 효과를 완벽하게 반영하지 못해 backward propagation과 forward propagation의 균열을 일으킨다. 이 문제를 해결하기 위해 RLQ는 다음과 같이 정의된다.
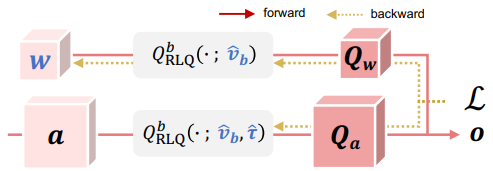
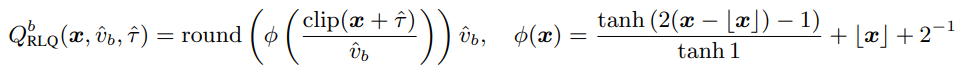
여기서 v_b와 tau는 각각 learnable scaler, learnable mean-shifting paramter로 원래의 v_b 값과 0으로 초기화된 채로 학습된다. 위 식을 통해 Quantizer는 scaler와 mean-shift가 train data에 맞게 변하면서 x값의 분포에 따라 최적화된다. backward propagation에 쓰이는 RLQ의 derivative들은 다음과 같다.
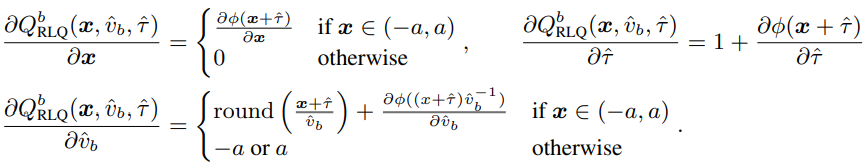

Depth-dynamic Quantized Architecture
Model의 i번째 block을 다음과 같이 정의한다고 하자.
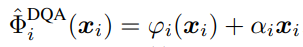
이때 x_i는 i번째 block의 input이며, φ는 convolution과 activation layer로 이루어진 module이며 α는 skip connection의 learnable scaler이다. 이 정의에 따라 전체 network는 다음과 같이 표현될 수 있다.
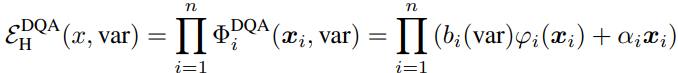
여기서 전체 training iteration의 1/5은 warm-up 과정으로 original loss func로 skip connection scaler를 학습시킨다. 이후 총 전체 block 개수의 k%(100%, 50%, 25%)만큼 다음을 적용한다. 각 block에서 α값이 적은 값으로 train되었을 수록 그 block은 skipped되지 않는 편이므로 하위 k% 개수의 block에 대해 b_i를 1로 나머지는 다 0으로 세팅한다. 즉, b_i가 0인 block은 skip되어 그 전 block과 merge될 수 있다.
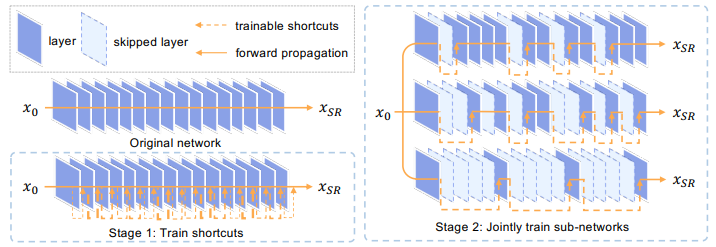
QuantSR
RLQ와 DQA를 동시에 적용한 QuantSR의 loss function은 warm-up stage에서는 다음과 같은 conventional pixel-wise loss function을 사용한다.
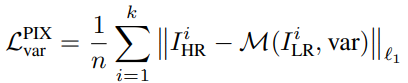
이때 I_HR은 i번째 input에 대한 High-resolution image, M(I^i_LR,var)은 QuantSR model의 결과값이다. 이후 stage에 대해서는 var은 {100,50,25%} 중 하나의 값을 가지며 다음과 같은 loss function으로 대체된다.
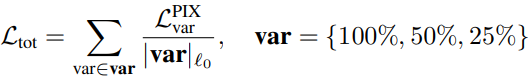
이때 |var|_l0는 l0 normalization을 의미한다.
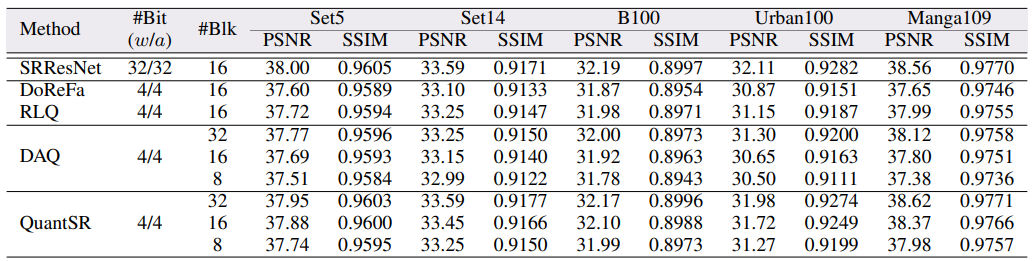
CNN-based SR model backbone으로 SRResNet과 Quantization baseline으로 vanilla quantization을 적용한 DoReFa와 Accuracy를 비교한 결과는 다음과 같다.
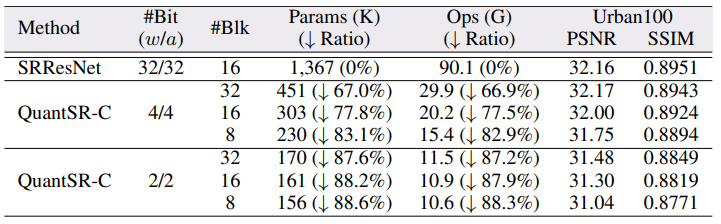
Compression ratio를 비교한 결과는 다음과 같다.

시사점
이 논문에서 제시한 방법들은 Quantization Aware Training(QAT)에서 쓰이는 Straight-through Estimator(STE)의 한계를 learnable parameter를 포함한 quantizer를 제시하여 train data의 distribution에 따라 Quantizer 자체를 학습하는 시도로 같은 parameter compression ratio로 더 accuracy drop이 적도록 하는 방향을 제시하였다. 또한 DQA를 통해 다양한 network 구조에 대해 동시 최적화하는 기법을 고안하여 다양한 network option에 대한 최적 model들을 취사선택할 수 있는 방법을 제시하였다. 하지만, RLQ에 쓰인 Quantizer의 수식이 어떻게 착안되었는지 (특히 Pi function), QuantSR에서 RLQ와 DQA가 어떻게 서로 시너지 효과를 낼 수 있었는지에 대한 설명이 빈약해 이해가 잘 되지 않았다.
