논문번역
Abstract
소프트웨어 성능 향상은 중요하지만 아직은 소프트웨어 개발 단계에서 아주 어려운 단계에 속한다. 오늘날 대다수의 성능 비효율은 성능 전문가로부터 발견이 되고 수정이 된다. 최근 딥러닝을 이용한 방법과 오픈 소스 데이터의 넓어진 접근성은 이러한 성능 문제 개선을 자동화할 수 있는 기회를 제공해줄 수 있다. 이 논문에서는 우리는 트랜스포머 기반의 접근 방법인 DeepPERF를 통해 C# 어플리케이션의 성능을 향상하는 것을 소개하고자 한다. 우린 DeepPERF를 영어와 소스코드 corpus들로 pretrain한 다음 C# 어플리케이션의 성능 개선 패치들로 finetuning을 하였다. 우리가 확인한 결과로는 우리의 모델이 제안한 성능 개선 제의는 모든 데이터셋에 대해 ~53% 정도 개발자 fix로 제안되었으며 여기서 ~34%정도 C# 개발자로부터 만들어진 전문가 검증된 데이터셋에서 채택되었다. 게다가 우리는 DeepPERF로 github의 50개의 C# 오픈소스 repository들을 벤치마크와 유닛테스트를 활용해 평가한 결과 CPU 사용량과 메모리 할당량에서 모두 개선할 수 있음을 증명하였다. 지금까지 우리는 19개의 pull request와 28개의 서로 다른 성능 최적화들을 제안했으며 이들 중 11개의 PR이 프로젝트 owner들에게 채택되었다.
Introduction
성능 버그들은 대개 non-functional 버그들로 불편한 사용자 경험을 유발하거나 처리량을 줄이거나 지연율을 높이거나 자원을 낭비하게 한다. 성능 버그들은 사용자 인풋에따라 시스템 failure를 유발하지는 않기 때문에 그들을 발견하는 것은 매우 어렵다. 그것들은 또한 non-performance 버그들에 비해 고치기도 어려운 경향이 있다. 결과적으로 성능 버그를 고치기 위해서는 더 나은 툴 지원이 필요하다.
최근 몇년동안 성능 버그들의 탐색 방법이 많이 등장하면서 개발자들이 성능 이슈들을 발견할 수 있게 도와주었다. 하지만 대부분의 현존하는 성능 문제 발견법들은 특정 타입의 성능 문제만을 찾는 데 집중되어 있다. 예를 들어, 이전 작업들은 비효율적인 루프를 찾는다던가 성능 이슈가 있는 데이터베이스 또는 낮은 사용률의 자료구조, 그리고 멀티쓰레드 코드에서 false sharing 이슈(멀티쓰레드는 동기화이슈가 항상 존재하는데, 동기화는 멀티쓰레드 효율을 크게 떨어뜨리므로 최대한 동기화를 덜 하는 게 좋다. 이처럼 false sharing이 있으면 쓸데 없는 동기화를 추가시켜 성능을 크게 저하시킨다.)를 찾는 것 등이 있다. 특정 성능 이슈만을 해결하는 전략들은 반복되는 연산 또는 잘못된 소프트웨어 configuration, 그리고 루프의 비효율 등등을 찾는데만 초점이 되어있다. 대다수의 이런 접근법들은 전문가가 직접 작성한 알고리즘에 의존하며 pre-defined rule들로 구성되어 있으며 abstract syntax tree (컴파일 단계 중 parse 단계 이후에 tree형태로 나오는 코드의 추상화된 표현방식), control flow graph, 그리고 profile에서 보이는 특정 패턴을 기반으로 동작한다. Rule-based 분석기를 설계하는 일은 매우 복잡하며 정확도와 복기 사이의 밸런스가 중요하다. 한번 개발되고 나면 그걸 유지하는 데에 성능 전문가들의 지속적인 노력과 자원이 소모된다.
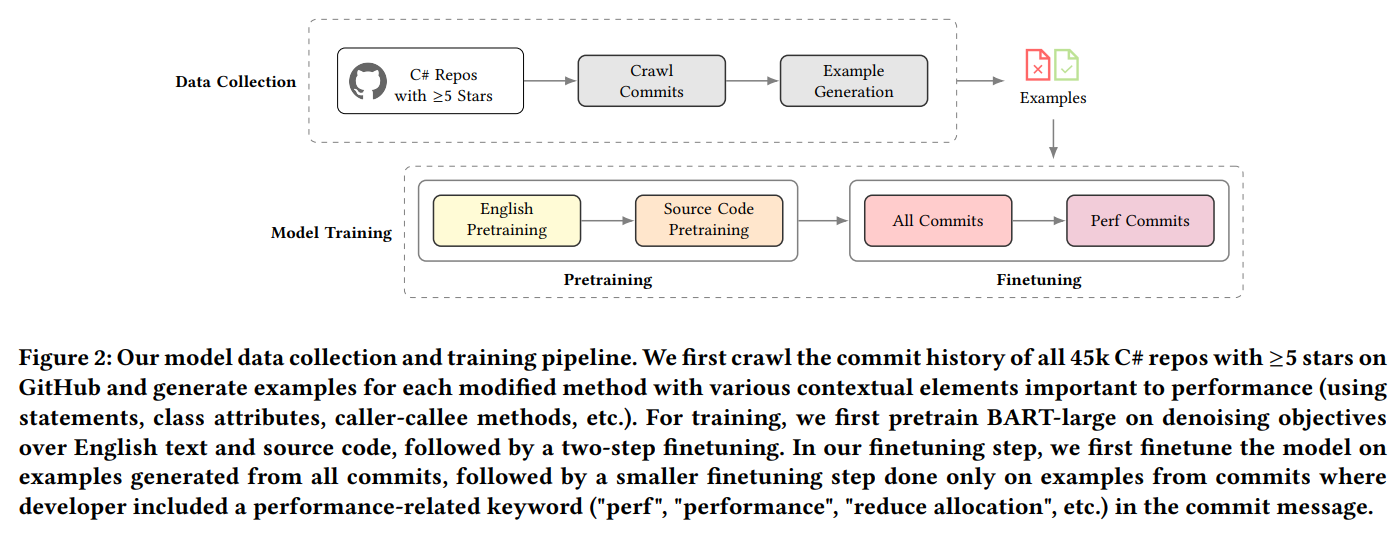
최근 Large Transformer models의 등장과 널리 퍼진 오픈소스 소프트웨어들의 쉬워진 접근은 발굴된 데이터를 활용해 성능 개선 패턴을 직접 파악하기 쉽도록 기회를 제공하고 있다. 트랜스포머 기반 접근법은 SOTA 성능을 달성할 수 있는 것으로 보이며 다양한 NLP 문제뿐만 아니라 code completion이나 documentation generation, unit test generation, bug detection 등등 소프트웨어 공항의 일들을 처리하는 데에 탁월한 능력을 보이고 있다.
우리는 DeepDev-Perf라 불리는 접근법을 제시하여 Large Transformer model이 어플리케이션 소스코드 레벨에서 성능 개선을 제안하도록 설계하였다. 우리는 먼저 우리의 모델을 Masked Language modeling (MLM) task로 English text와 gitHub으로부터 얻은 오픈 소스 repo의 source code로 pretrain을 한 뒤, .NET 개발자들로부터 수행된 수십만의 성능 개선 commit들로 finetuning을 수행하였다. 우리의 평가에 의하면 우리 접근법은 현존하는 성능 개선 분석기만으로는 불가능한 매우 다양한 범위에서 C# 어플리케이션에 대한 성능 최적화를 제안하였다. 대부분의 제안들은 API나 자료 구조 그리고 알고리즘 수준의 high-level의 개선을 동반하였으며 종종 C# 컴파일러 단독으로는 불가능한 다양한 방법들을 동반하기도 했다. 나아가, 벤치마크 테스트들과 실제 repo들에 적용을 해봄으로써 우리의 제안들이 실제로 성능 개선 효과가 있음을 증명하였다. 그 중 11개의 PR은 실제 프로젝트 개발자에게 accept되어 적용이 되었으며 이를 통해 우리의 제안이 실제로 정확했으며 유용함을 보여주었다. 요약하자면 우리의 작업은 다음의 기여를 가진다.
- 우리는 획기적인 transformer 기반의 모델 DeepPERF를 통해 C# 어플리케이션의 성능 개선 기회를 제공하였으며 자동으로 성능 개선 패치들을 제안한다.
- 우리는 C# 개발자들이 실제 수행한 성능 개선 패치들의 데이터셋을 활용하여 DeepPERF를 평가하였으며 다양한 성능 개선 효과를 가지는 것을 증명하였다.
- 우리는 github의 다양한 C# 오픈소스 프로젝트들에서 DeepPERF를 통해 성능 개선들을 제안했으며 그들 중 대부분이 많은 개발자들에게 유용하고 정확함을 인정받았다.
Conclusions
소프트웨어 개발 단계에서 성능 버그들을 찾고 고치는 것은 중요하지만 어려운 작업에 속한다. 우리의 작업은 이 문제를 해결하기 위한 3가지 기여를 가진다.
1. 우리는 획기적인 트랜스포머 기반의 모델을 제시하여 자동으로 성능 개선 패치를 생성하도록 하였다.
2. 우리는 실증기반의 평가방법을 통해 우리의 모델이 github의 오픈소스 repo에서 C# 개발자들이 만든 성능 개선 commit들로부터 얻은 데이터셋을 활용하도록 설계하였다. 이 방법을 통해 우리는 모델이 다양한 종류의 성능 최적화를 제공한다는 것을 보여주었고 이는 성능 전문가들에게 증명받았다.
3. 마지막으로 우리는 실용적으로 end-to-end 파이프라인에서 성능 개선을 자동으로 제공하는 것을 선보였다. 이 파이프라인은 우리 모델과 함께 유닛 테스트와 벤치마크가 동작하게 하여 생성된 패치를 검증하도록 활용되었다. 우리는 우리 모델이 유효한 성능 개선을 제안했음을 보였으며 이는 실제 어플리케이션에서 분명한 성능 개선을 보여주었다. 우리는 이 파이프라인을 활용해 다양한 성능 개선 제안들을 생성하였고 몇몇의 PR들은 실제 project owner들에게 인정받아 코드에 merge되었다.