1. 결측치(Missing Data)
# 컬럼별 결측치 갯수 = 전체 데이터 건수 - 각 켤럽별 값이 있는 데이터 수
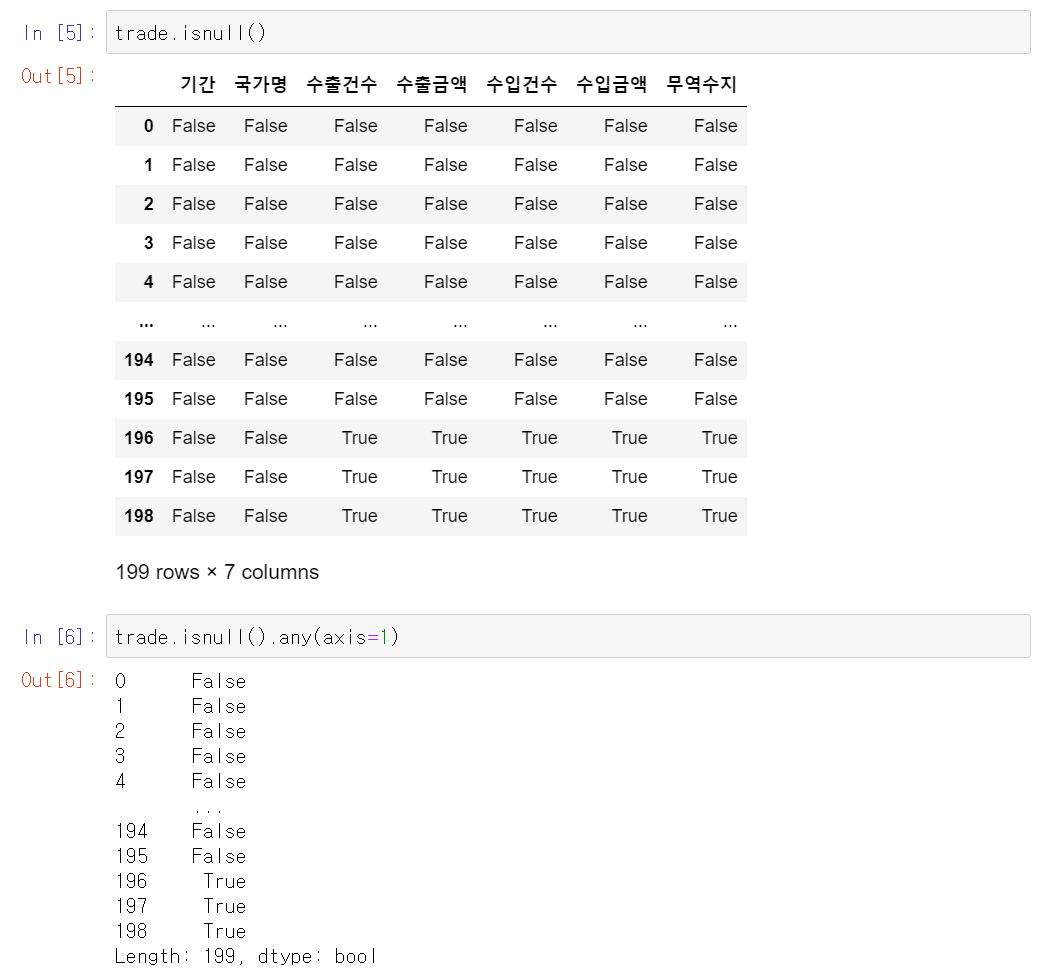
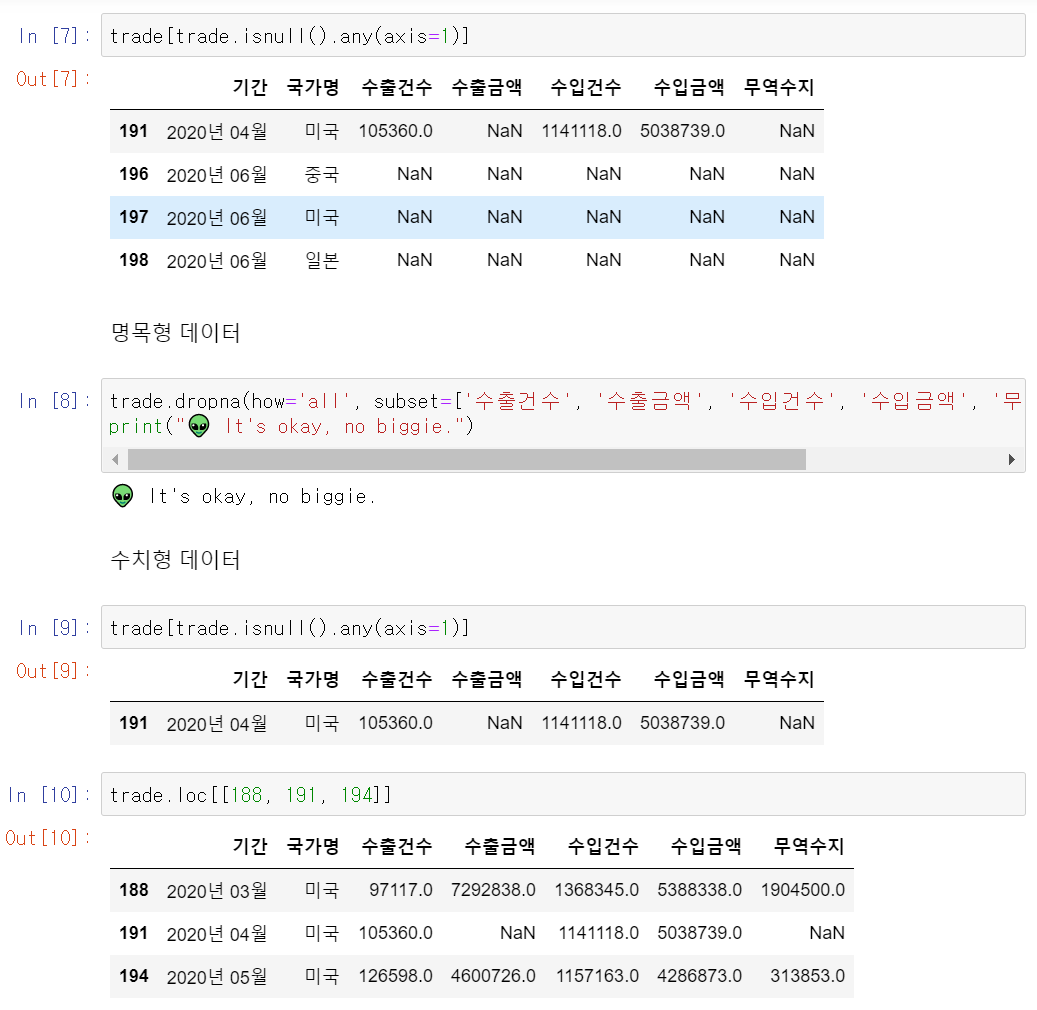
# trade : 데이터가 들어있는 변수명.isnell(): 결측치 여부 True/False 반환.any(axis=1): 행마다 하나라도 있으면 True/없으면 False 반환- Series 값으로 출력
.dropna(): 결측치 삭제 메서드- how 옵션
- all - selected column가 all 결측치인 행 삭제
- any - 하나라도 결측치인 경우
- subset 옵션 : 특정 컬럼 리스트로 선택
- inplae : 해당 DataFrame 내부에 바로 적용 여부
- how 옵션
1) 수치형 데이터
- 특정 값 지정. but, 결측치 多 경우 데이터 분산이 작아지는 문제 발생
- 평균, 중앙값 대체, but 마찬가지 결측치 多 경우 데이터 분산이 작아지는 문제 발생
- 다른 데이터를 이용해 예측값으로 대체 ex) 머신러닝 모델로 2020년 4월 미국의 예측값을 만들고, 이 값으로 결측치를 보완
- 시계열 데이터의 경우, 전후 데이터 평균으로 결측치 대체
2) 범주형 데이터
- 특정 값을 지정. ex) ‘기타’, ‘결측’과 같은 새로운 범주를 만듦
- 최빈값 등으로 대체. but, 결측치 多 경우 최빈값이 지나치게 多 문제 발생
- 다른 데이터를 이용해 예측값으로 대체
- 시계열 데이터의 경우, 앞뒤 데이터를 통해 결측치를 대체
ex) 특정인의 2019년 직업이 결측치이고, 2018년과 2020년 직업이 일치한다면 그 값으로 보완. 만약 다르다면 둘 중 하나로 보완.

2. 중복된 데이터
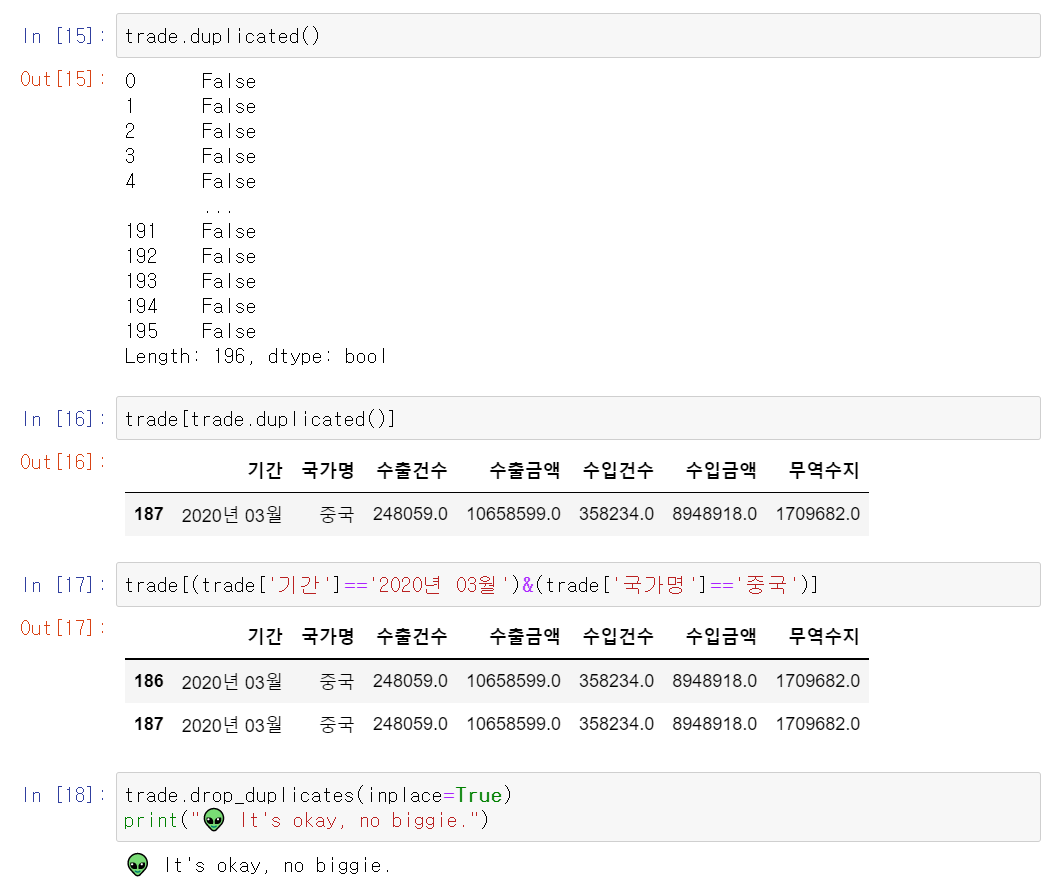
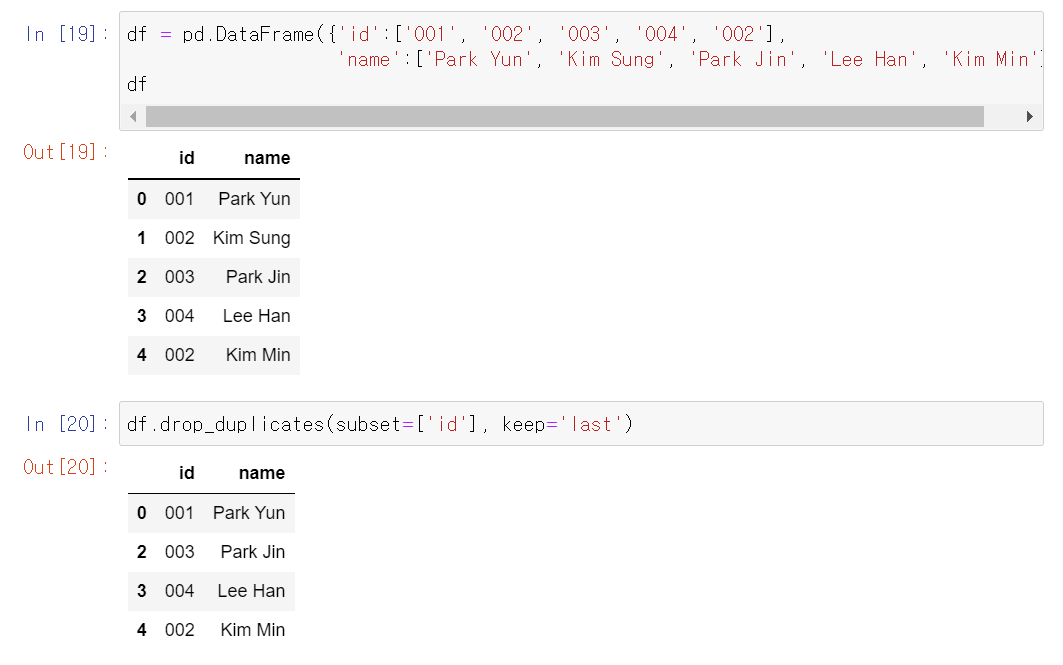
.duplicated(): 중복된 데이터 여부(True/False) 반환.drop_duplicates: 중복된 데이터 삭제(pandas)- subset 옵션 : 삭제할 data의 기준이 되는 column 선택
- keep 옵션 : 유지시킬 중복값을 선택
+ first : 첫 번째 발생 값 유지
+ last : 마지막 항목 값 유지
+ false : 중복값 모두 삭제
참고자료 : DataFrame.drop_duplicates
3. 이상치(Outlier)
- 대부분 값의 범위에서 벗어나 극단적으로 크거나 작은 값
1) 이상치 판단
- Min-Max Scaling : 대부분의 값은 0에 가깝고 이상치만 1에 가까운 값을 가짐
- anomaly detection : 이상치를 찾는 것 자체가 큰 분야
- 간단하고 자주 사용되는 방법 : z score(평균을 빼주고 표준편차로 나눔)
2) 처리 방법
- 이상치 삭제. or 원래 데이터에서 이상치를 삭제 => 이상치끼리 따로 분석
- 다른 값으로 대체.
- 데이터 少 경우 삭제보다 다른 값 대체하는 것이 나을 수 있음.
- ex) 최댓값, 최솟값을 설정해 데이터의 범위를 제한.
- 다른 데이터를 활용하여 예측 모델을 만들어 예측값을 활용.
- binning을 통해 수치형 데이터를 범주형으로 변환.
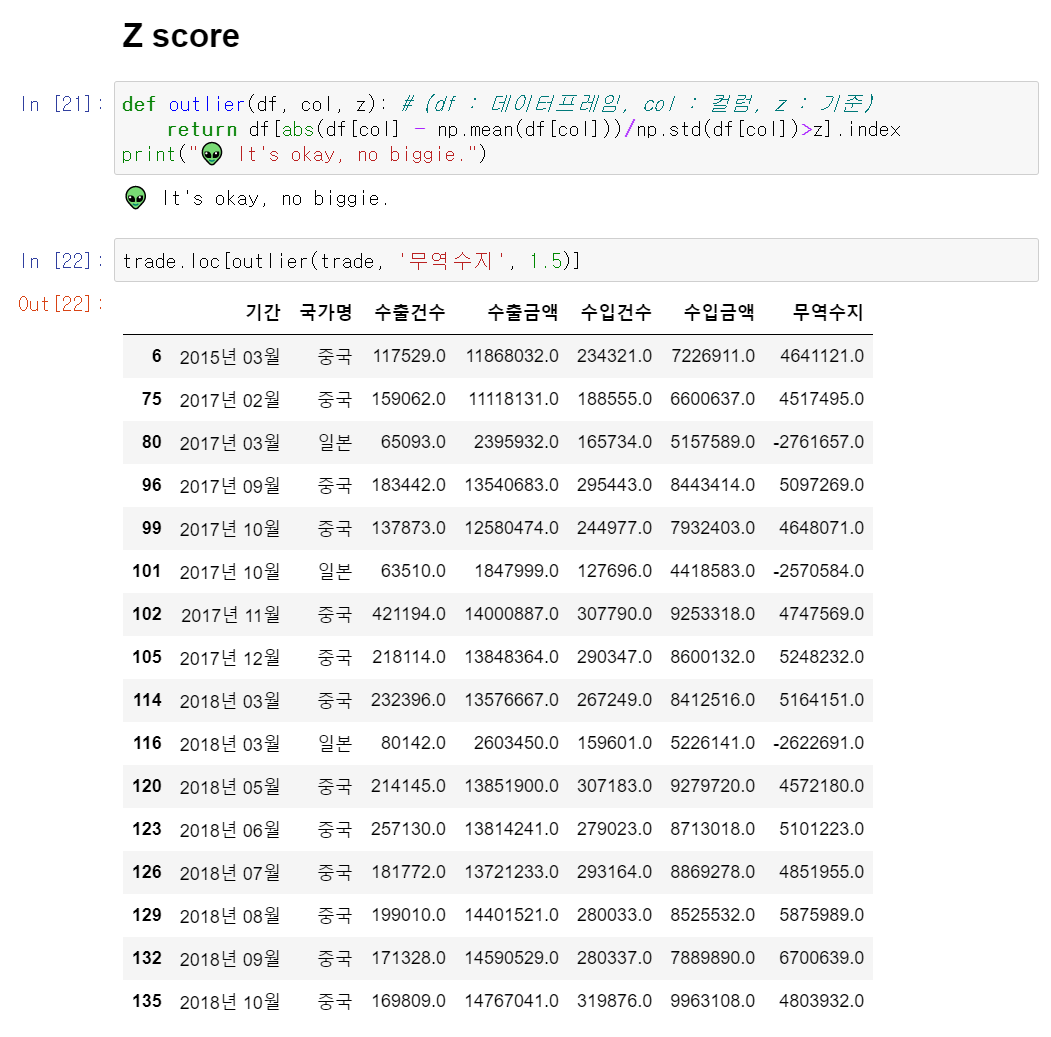
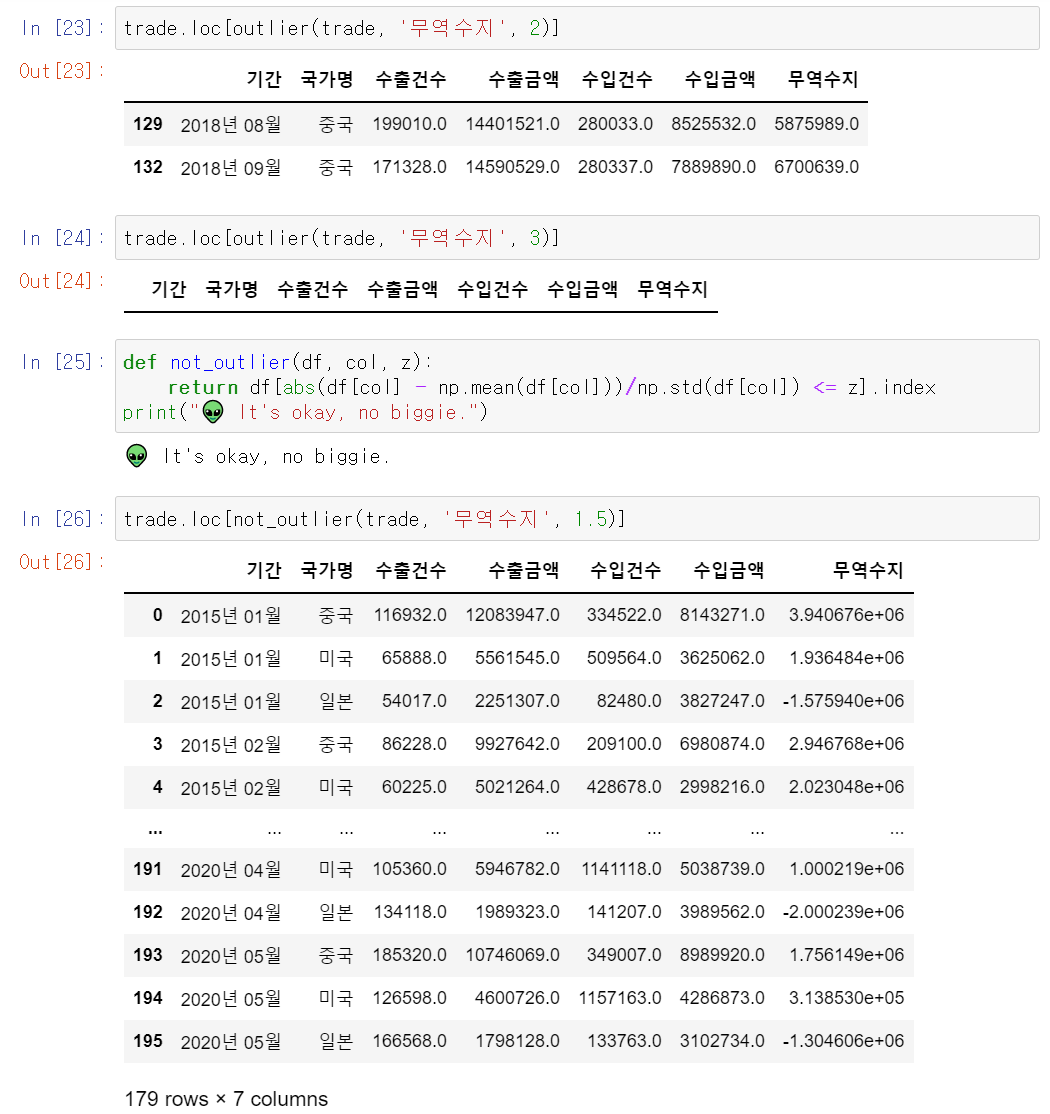
3) z-score method
abs(df[col] - np.mean(df[col])) : |x - mean(X)|
abs(df[col] - np.mean(df[col]))/np.std(df[col]) : (|x - mean(X)|)/std
df[abs(df[col] - np.mean(df[col]))/np.std(df[col])>z].index: 값이 z보다 큰 데이터의 인덱스를 추출
- z 기준값이 클수록 이상치가 적어짐
- z-score method의 한계점 有
- Robust하지 못함 : ∵ 이상치에 의해 평균과 표준편차에 매우 영향을 받음
- 데이터가 적을 수록 이상치를 찾지 못함(12개 이하인 데이터셋에서는 불가)
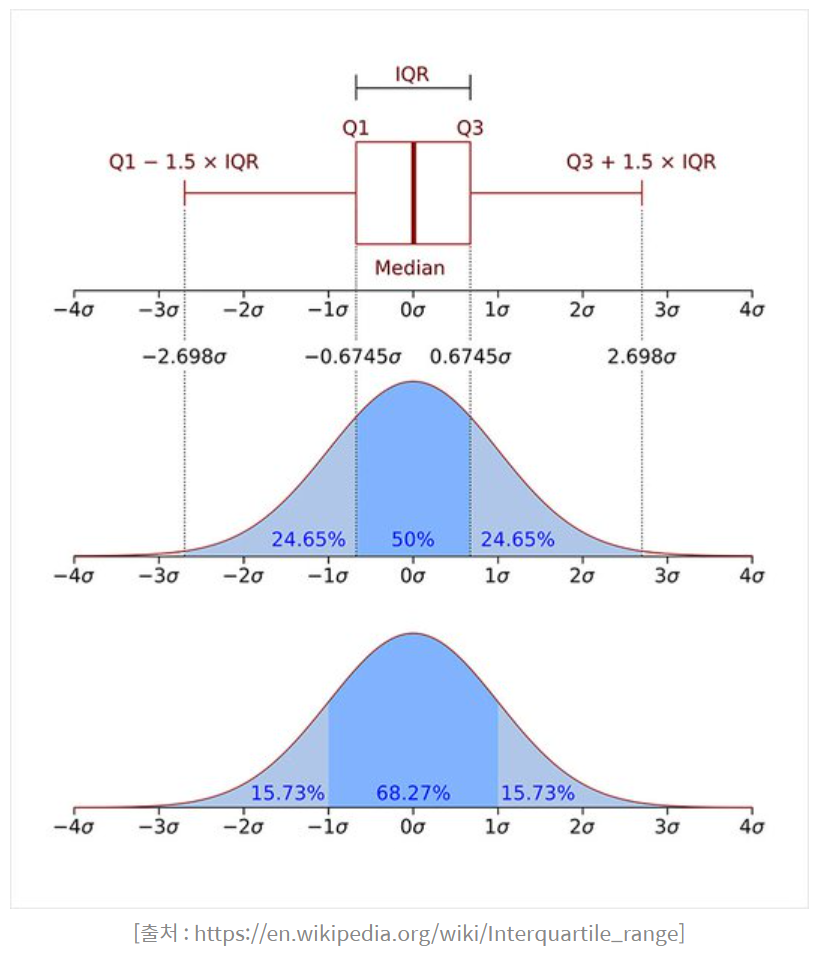
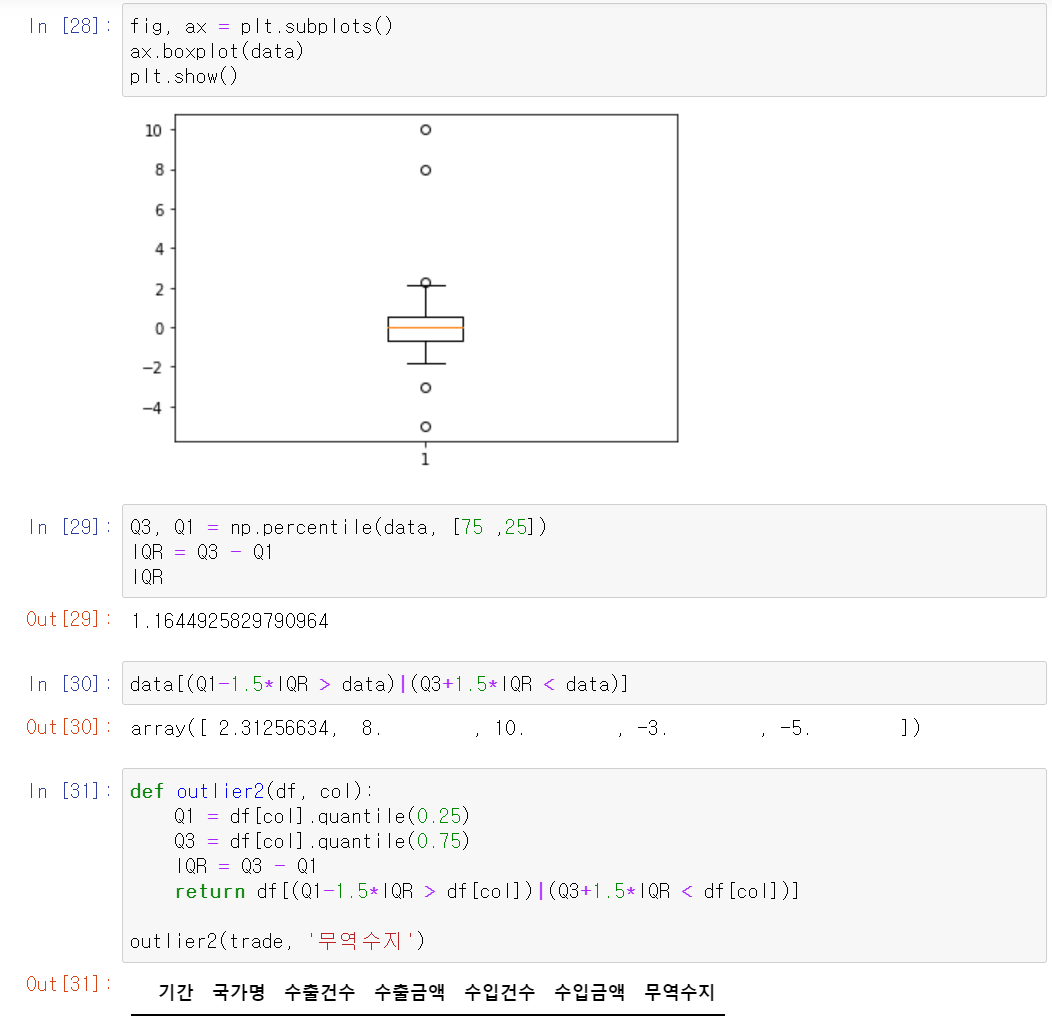
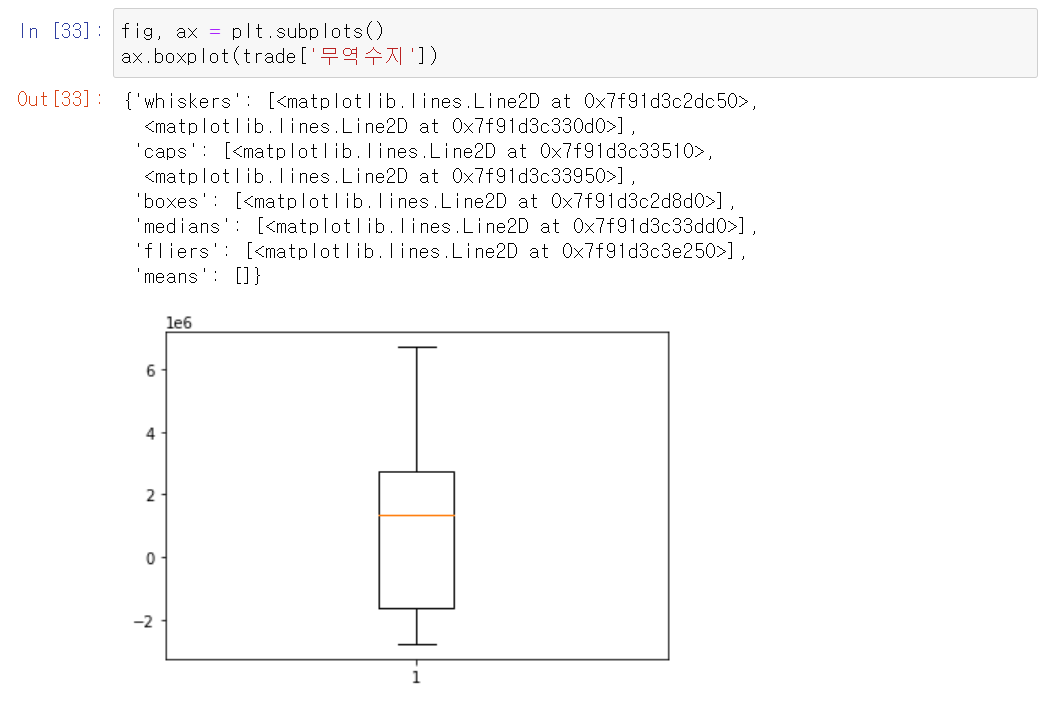
4) IQR method
-
IQR(Interquartile range) : 사분위범위수 Q3 - Q1
- Q1(제1사분위수) = 25%지점
- Q2(제2사분위수) = 50%지점
- Q3(제3사분위수) = 75%지점
-
.quantile(): 백분위수, 0~1 사이값 입력 (in pandas) -
.percentile(): 백분위수, 0~100 사이값 입력 (in numpy) -
.concatenate(): columns를 따라 배열 시퀀스를 결합(in numpy)

4. 정규화(Normalization)
-
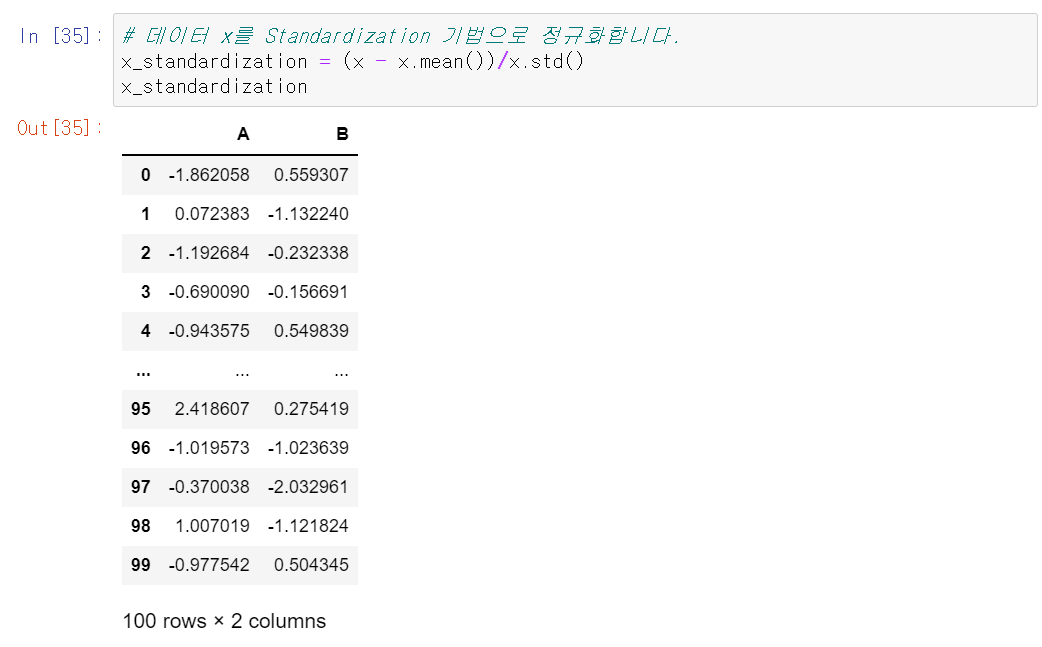
표준화(Standardization) :데이터의 평균은 0, 분산은 1로 변환
X-mu/sigma
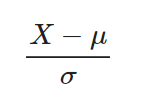
-
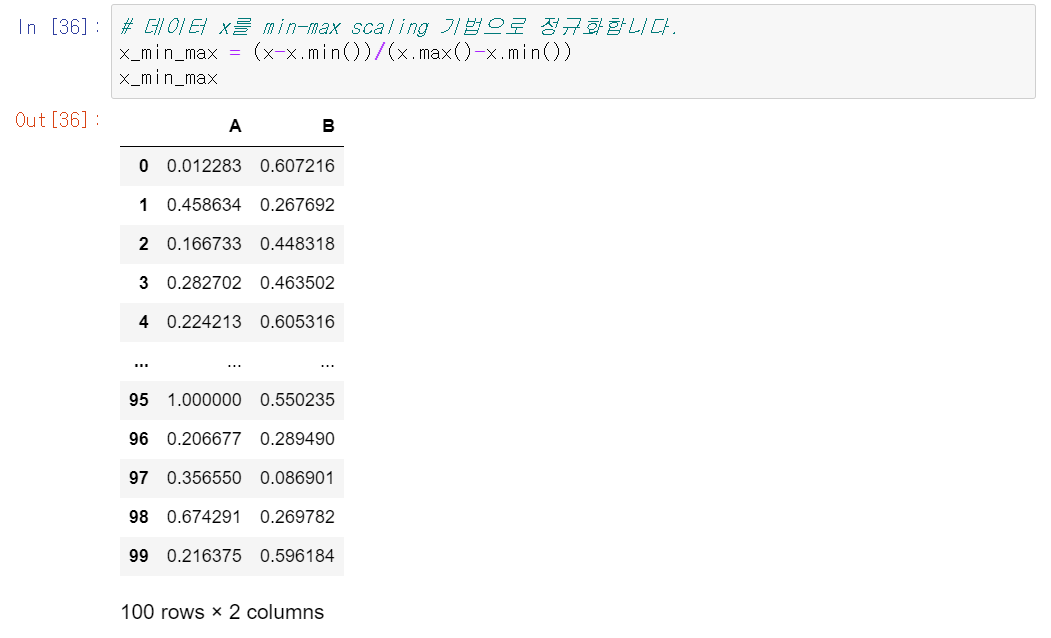
Min-Max Scaling :데이터의 최솟값은 0, 최댓값은 1로 변환
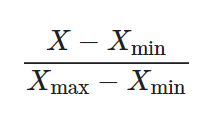
참고자료 : 데이터 스케일링(Data Scaling)

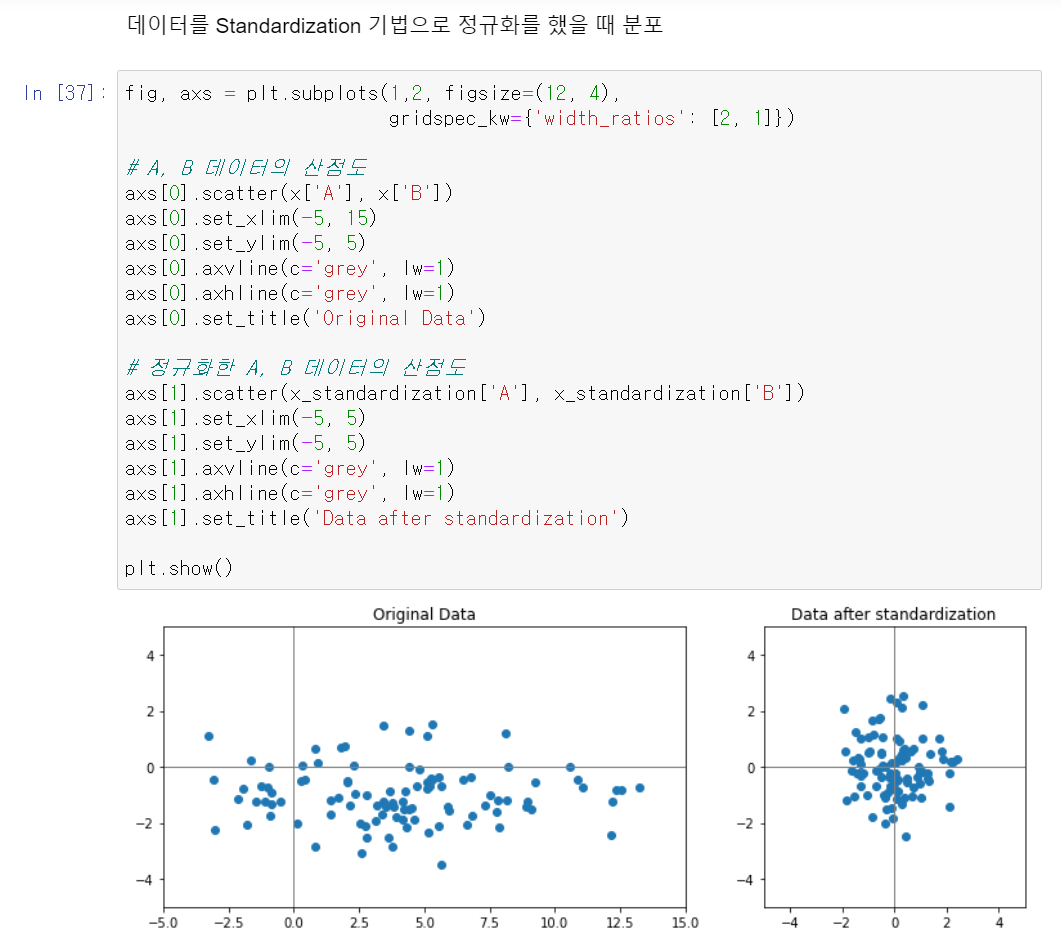
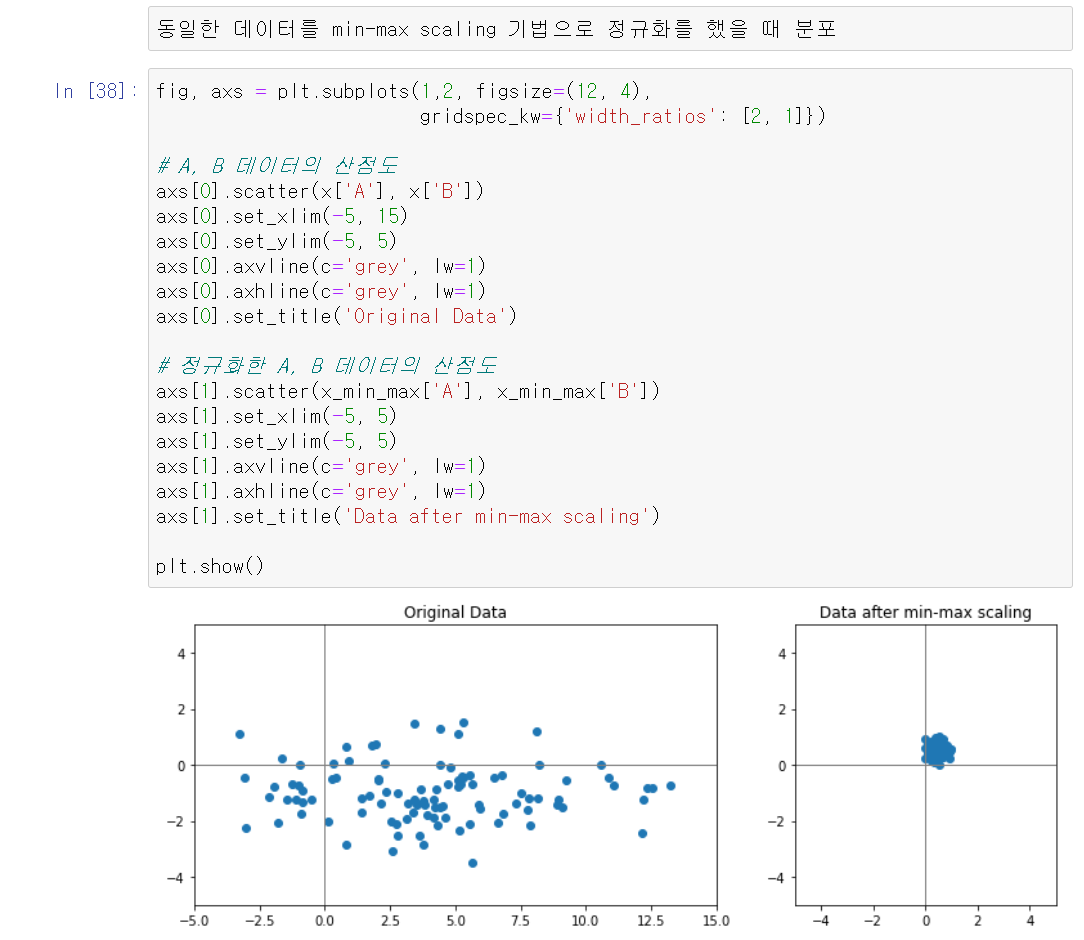
5. 원-핫 인코딩(One-Hot Encoding)
- 카테고리별 이진 특성을 만들어 해당하는 특성만 1, 나머지는 0으로 만드는 방법
- .get_dummies() : 원-핫 인코딩
6. 구간화(Binning)
- 데이터를 구간별로 나누는 기법(Data binning or bucketing)
- pd.cut(column명, bins = 구간 범위 or 구간 개수) : 동일길이로 나누기
- pd.qcut() : 동이ㅣㄹ 개수로 나누기