평균은 n으로 나누고 분산, 표준편차는 n-1로 나누는 이유는?
1. 배열
1) 파이썬의 리스트
- 동적배열(Dynamic Array)
- 임의의 데이터 타입을 담을 수 있는 가변적 연속열(Sequence)형
- list와 array의 장점을 모두 취한 형태
- 자료구조상 linked list의 기능을 가지나, 실제로는 array로 구현
2) Array vs List
array :
- 고유 식별자(index)와 그에 대흥하는 데이터 묶음
- 연속된 메모리 영역에 순서대로 저장
- 연속된 저장으로 인덱스 번호를 이용한 빠른 접근이 가능
=> 임의 접근(Random access) - element 유형을 지정하여 생성, 다른 타입 element 추가가 허용되지 않음
- read : O(1), write/updatd/delete : O(n)
list:
- 연속된 위치가 아닌 떨어진 영역에 저장
- pointer가 다음 메모리의 위치를 가리킴
- 1번 부터 n까지 다 거쳐서 들려야하는 순차접근 or Sequential access
- 동적자료구조 : 데이터 크기 변형 가능, 추가/삭제가 편함
- element 사이에 다른 타입의 자료형 허용
- read : O(n), write/update/deletd : O(n)
3) Numpy
우분투에서 설치 확인방법 및 설치 명령아
> conda list | grep numpy
> pip install numpy
# pip = package installer for python
> import numpy as np
👀 알아두기 👀
> if__name__ == "__main__"이 파일을 실행시켰을 때, if문이 True가 되어야 if문 다음의 문장들이 수행됨
다른 파일에서 이 파일(모듈)을 불러서 사용할 때는 if문이 False가 되어 if문 다음의 문장이 수행되지 않음
① ndarry 만들기 : agrange(), array([])
> C = np.array([0,1,2,3,'4'])
출력값 : ['0' '1' '2' '3' '4']
😊 array의 성질(모든 element의 type 동일) 때문에 전체가 str로 바뀜② 크기
- ndarray.size : ndarray의 원소의 개수
- ndarray.shape : ndarray의 행, 열 길이 = 행렬의 모양
- ndarray.ndim : 행렬의 축(axis)의 개수 = n차원
- .reshape() : 행렬의 모양을 바꿈, 바꾸기 전후의 size는 동일해야함.
> A = np.arrage(10).reshape(2, 5) : 길이가 10인 1차원 행렬을 2x5 2차원 행렬로 바꿈
③ type() & dtype()
-
type() : 행렬의 자료형 return
-
dtype() : Numpy ndarrary의 element의 데이터 타입을 return.
> D = np.array([0,1,2,3,[4,5],6]) print(D) : 0 1 2 3 list([4, 5]) 6] print(D.dtype) : object 파이썬의 최상위 클래스. print(type(D)) : <class 'numpy.ndarray'> ∴ Numpy는 dtype을 object로 지정해서라도 행렬 내 dtype을 일치시킬 수 있게 됩니다.
④ 특수행렬

⑤ Broadcast 연산
- 다른 모양의 배열을 처리하는 방법
- 작업의 두 배열에 대한 후행 축의 크기가 동일 or 둘 중 하나가 하나








⑥ 슬라이스와 인덱스


❓ A= [:2, 1:] : 열 0~1/ 행???? 해석이 어떻게 되는 거지??🤨
⑦ .random 패키지
- np.random.random() : 0에서 1사이의 실수형 난수 하나를 생성
- np.random.randint() : 0~9 사이 1개 정수형 난수 하나를 생성
- np.random.choice() : ()에 주어진 값 중 하나를 랜덤하게 골라줍
- np.random.permutation() : 원소의 순서를 임의로 출력
- np.random.normal() : 정규분포 분포를 따르는 변수를 임의로 표본추출
- np.random.uniform() : 균등분포 분포를 따르는 변수를 임의로 표본추출
⑧ 전치행렬
- 행렬의 행과 열을 맞바꾸기, 행렬의 축을 서로 바꾸기
- arr.T : 전차행렬
- np.transpose : 행렬 축 변환
⑨ 기본 통계 데이터 계산
- sum(), mean(), std(), median() : 중간값
2. 데이터의 행렬 변환(이미지)
- 흑백 : 2차원 ndarray / 컬러 : 3차원 ndarray
- 라이브러리 : matplotlib, PIL
- 조작 메소드
- open : Image.open() : 이미지 파일 open
- size : Image.size : 이미지의 가로X세로 사이즈(픽셀???)
- filename : Image.filename
- crop : Image.crop((x0, y0, xt, yt)) : 이미지 자르기, 가로,세로 시작점, 가로세로 종료점 지정
- resize : Image.resize((w,h))
- save : Image.save() : 저장
- .format : 이미지 파일 타입
- .mode : 색상 정보
※ 참고자료 : NumPy 및 데이터 표현에 대한 시각적 소개
3. 구조화된 데이터
- 데이터 내부에 자체적인 서브 구조를 가지는 데이터(table형태)
- hash : key와 value로 구성된 자료구조
1) Dictionary
- 파이썬에서는 dictionary😆로 불림 dict() or {key:value}로 표현
- .items() : 딕셔너리의 key와 value를 모두 return
- 키를 가지고 값을 조회할 수 있음
ex)Country_PhoneNumber = {'korea': 82, 'America': 1} Country_PhoneNumber['korea']=> 82 return
- 딕셔너리의 딕셔너리
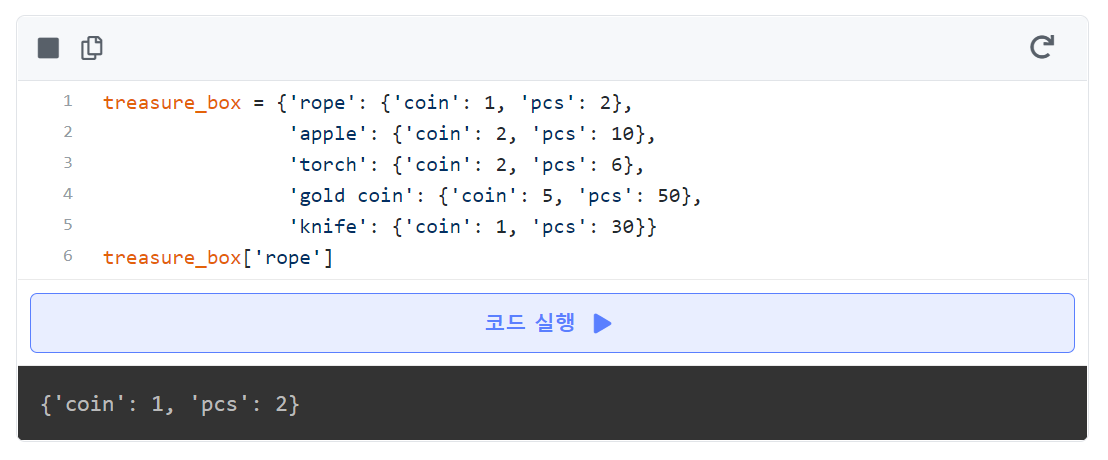
ex) 이중 딕셔너리 호출


2) Pandas
- Series와 DataFrame 자료구조를 제공
- 특징 :
- NumPy기반에서 개발되어 NumPy를 사용하는 어플리케이션에서 쉽게 사용 가능
- 축의 이름에 따라 데이터를 정렬할 수 있는 자료 구조
- 다양한 방식으로 인덱스(index)하여 데이터를 다룰 수 있는 기능
- 통합된 시계열 기능 & 통합 자료 구조
- 통합 자료 구조 : 시계열 데이터와 비시계열 데이터를 함께 다룸
- 누락된 데이터 처리 기능
- 데이터베이스처럼 데이터를 합치고 관계연산을 수행하는 기능
> pip install pandas
(1) Series
- 1차원 배열과 비슷한 자료구조
- 리스트, 튜플 or NumPy 자료형으로도 만들 수 있음

- .values : array 형태로 호출
- .index : RangeIndex 반환 = 정수형 인덱스


- 인덱스 설정 방법
① ser2 = pd.Series(['a', 'b', 'c', 3], index=['i','j','k','h'])
② ser2.index = ['Jhon', 'Steve', 'Jack', 'Bob']
>> ser2.index 실행하면 RangeIndex -> Index 타입 객체가 표시됨- 딕셔너리를 사용하면 Series에서는 딕셔너리의 키가 인덱스로 설정됨
- Series : index, value(2개의 Column) vs 딕셔너리 : key, value(2개의 Column)

- Series : index, value(2개의 Column) vs 딕셔너리 : key, value(2개의 Column)
- 값이 할당된 인덱스에서는 딕셔너리와 유사하여 슬라이싱 기능을 지원

- .name : Series 객체의 이름을 설정
- .index.name : 인덱스 이름 설정 = column 이름
(2) DataFrame



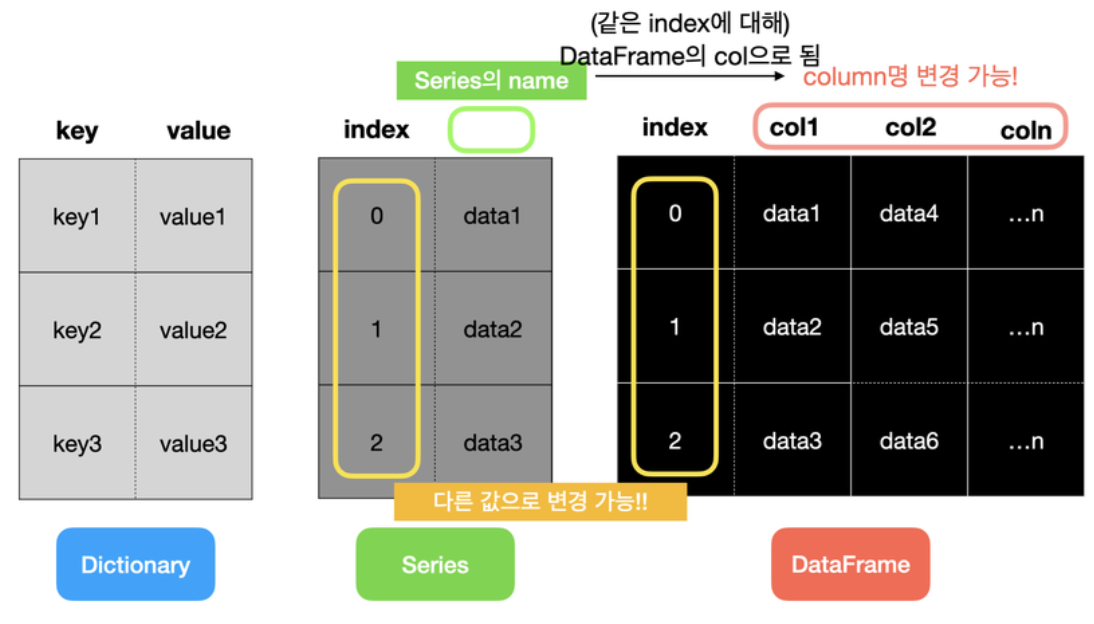
⭐️Dictionary vs Series vs Dataframe⭐️
(3) EDA(Exploratory Data Analysis)
- 통계데이터를 활용해서 데이터의 대푯값과 분산을 구하는 것
> mkdir p ~/aiffel/data_represent/data > ln -s ~/data/covid19_italy_region.csv ~/aiffel/data_represent/data
-
csv 파일 읽기

-
pandas 통계 관련 메소드
- .head(), .tail() : 첫 5개행, 마지막 5개행 보여줌
- .columns : 데이터셋에 존재하는 컬럼명 return
- .info() : column별 Null값과 자료형을 return
- .drop() : 특정 컬럼 삭제
- .isnull().sum() : 결측값(Missing value) 확인 및 갯수 총합
- .value_counts() : 범주형 data column별로 값이 몇개 있는지 확인
- .count(): NA를 제외한 수를 반환
- .describe(): 요약통계를 계산
- .min(), .max(): 최소, 최댓값
- .sum(): 합을 계산합니다.
- .mean(): 평균을 계산합니다.
- .median(): 중앙값을 계산합니다.
- .var(): 분산을 계산합니다.
- .std(): 표준편차를 계산합니다.
- .corr() : 2개의 인자의 상관계수(-1 <= r <= 1)
- .argmin(), .argmax(): 최소, 최댓값을 가지고 있는 값을 반환 합니다.
- .idxmin(), .idxmax(): 최소, 최댓값을 가지고 있는 인덱스를 반환합니다.
- .cumsum(): 누적 합을 계산합니다.
- .pct_change(): 퍼센트 변화율을 계산합니다.
참고자료 : pandas 주요기능
