- scikit-learn(사이킷런) : 파이썬에서 머신러닝 분석을 할 때 유용하게 사용할 수 있는 라이브러리
- 장점 : 머신러닝의 다양한 알고리즘과 편리한 프레임워크를 제공
- pandas : 2차원 배열 데이터를 다룰때 많이 사용하는 패키지
1. 머신러닝 용어
- 지도학습(Supervised Learning) : 정답이 있는 문제에 대해 학습하는 것
- 분류(Classification) : 입력받은 데이터를 특정 카테고리 중 하나로 분류해내는 문제
- 회귀(Regression) : 입력받은 데이터에 따라 특정 필드의 수치를 맞히는 문제
- 비지도학습(Unsupervised Learning) : 정답이 없는 문제를 학습하는 것
- target 또는 label : 머신러닝 모델이 출력해야 하는 정답(Y)
- feature : 머신러닝 모델에서 입력되는 데이터(X)
- training dataset : 모델 학습에 사용되는 데이터 셋
- test dataset : 모델의 성능 평가에 사용되는 데이터 셋
2. 분류 모델의 종류
-
Random Forest
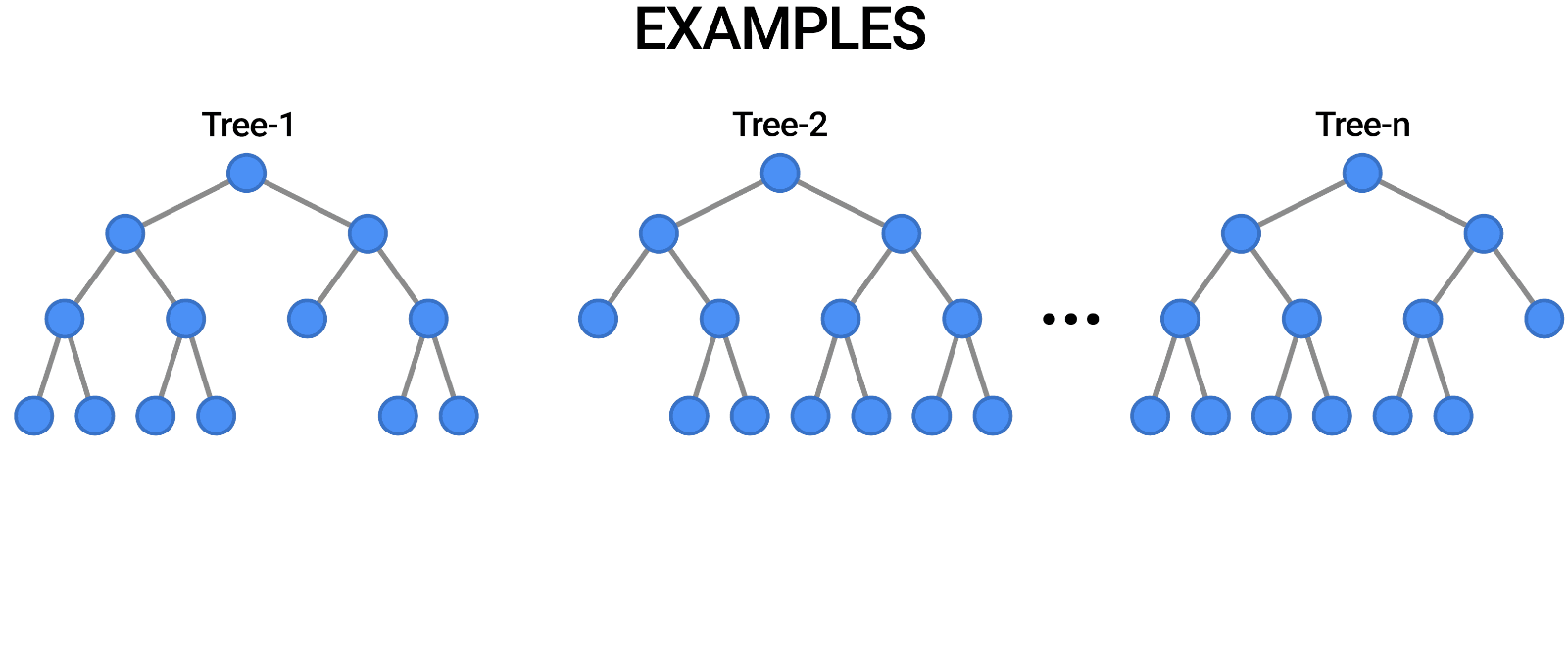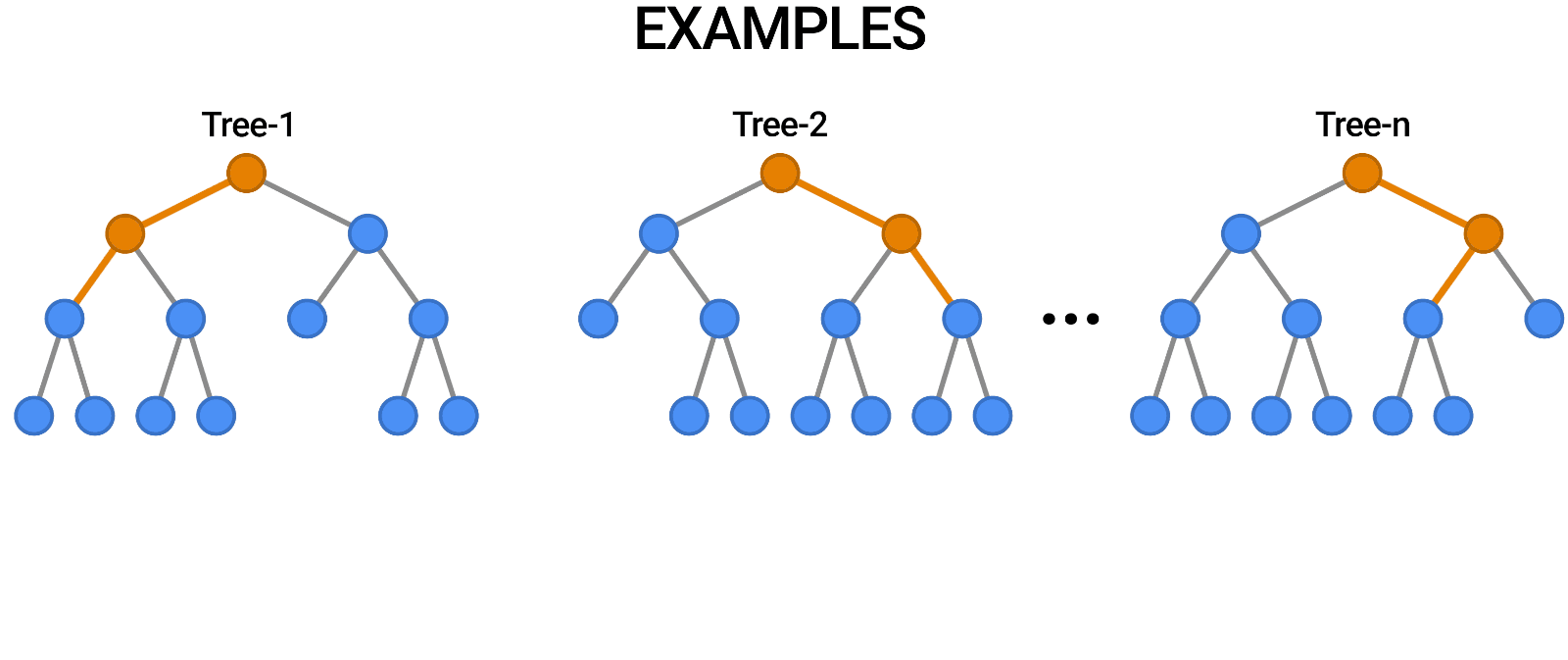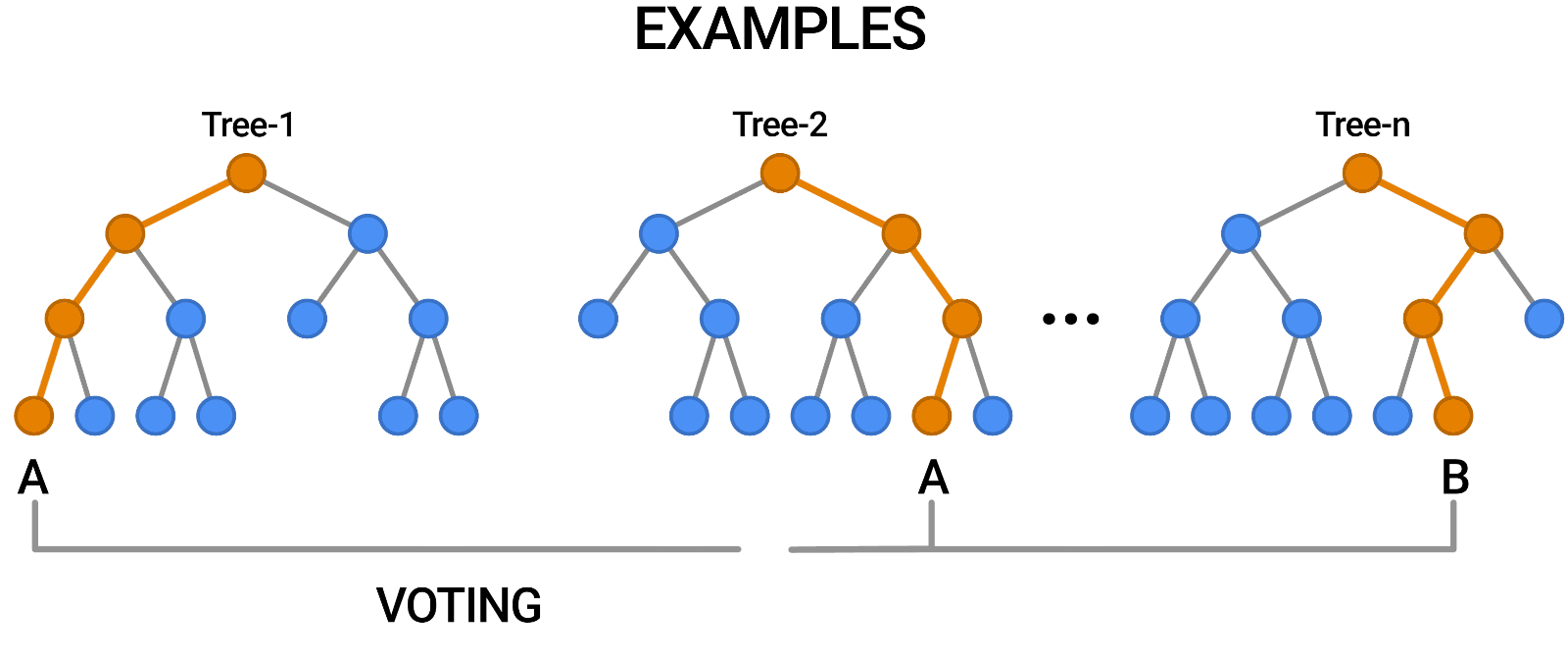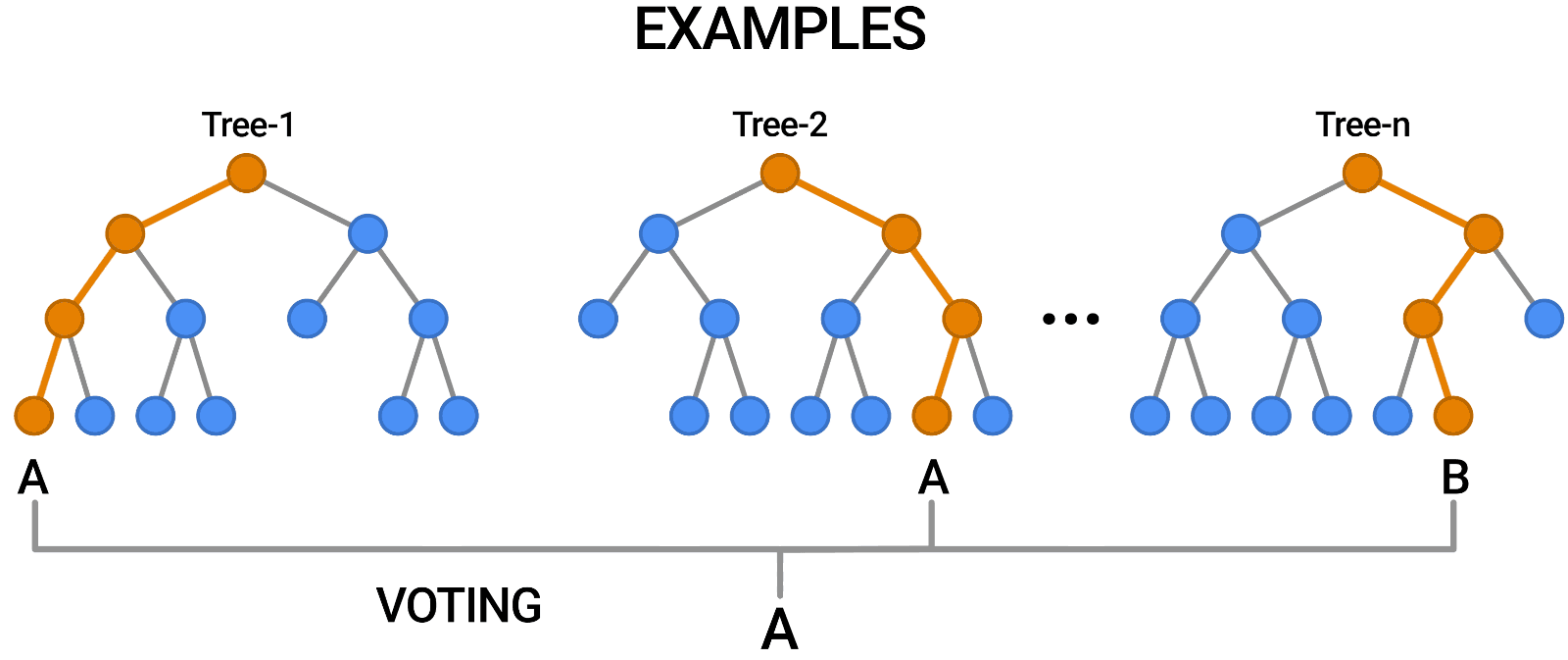
- Decision Tree 모델을 여러 개 합쳐놓음으로써 Decision Tree의 단점을 극복한 모델 - 앙상블(Ensemble) 기법
- 앙상블(Ensemble) 기법
- 단일 모델을 여러 개 사용하는 방법을 취함으로써 모델 한 개만 사용할 때의 단점을 집단지성으로 극복하는 개념
- 의견을 통합하거나 여러가지 결과를 합치는 방식

- Decision Tree 모델을 여러 개 합쳐놓음으로써 Decision Tree의 단점을 극복한 모델 - 앙상블(Ensemble) 기법
-
Support Vector Machine (SVM)
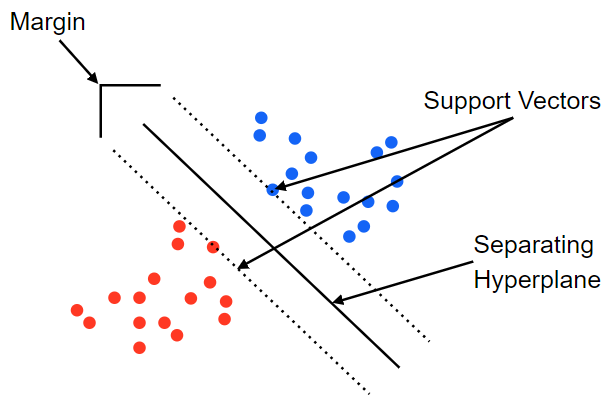
- Support Vector와 Hyperplane(초평면)을 이용해서 분류를 수행하게 되는 대표적인 선형 분류 알고리즘
- Decision Boundary(결정 경계): 두 개의 클래스를 구분해 주는 선 = Hyperplane
- Support Vector: Decision Boundary에 가까이 있는 데이터
- Margin: Decision Boundary와 Support Vector 사이의 거리 (Margin 최대화 → robustness 최대화)
-
Stochastic Gradient Descent Classifier (SGDClassifier)
- 배치 크기가 1인 경사하강법 알고리즘
- 배치(batch) :단일 반복에서 기울기를 계산하는 데 사용하는 예(data)의 총 개
- 단점 : 노이즈가 심함 → Mini batch SGD로 극복
-
Logistic Regression
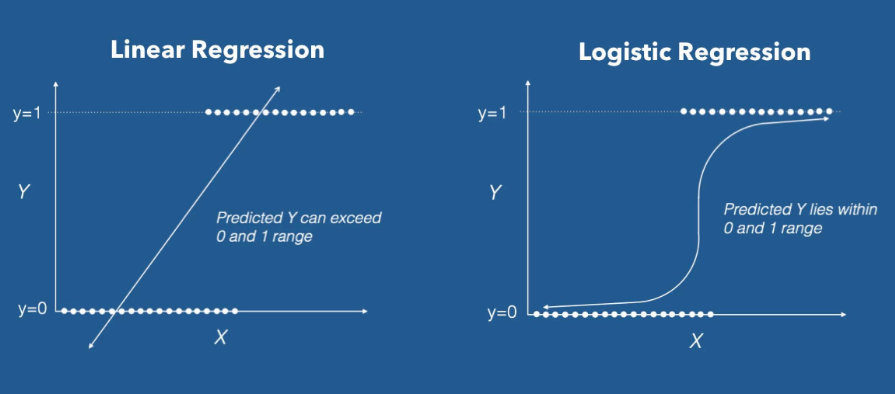
- 선형방정식을 사용한 분류 알고리즘
- sigmoid 함수 : (이진 분류) 선형 방정식의 출력을 0과 1 사이값으로 압축
- softmas 함수 : (다중 분류) 클래스가 N개일 때, 각 클래스가 정답일 확률을 표현하도록 정규화를 해주는 함수
- 로지스틱 회귀 읽기 자료
- 선형방정식을 사용한 분류 알고리즘

2. 성능 평가 척도
-
정확도(Accuracy) : 전체 개수 중 맞은 것의 개수의 수치
-
불균형한 데이터(unbalanced 데이터)
-
오차행렬(confusion matrix) : 정답과 오답을 구분하여 표현하는 방법
- 실제 클래스(Actual Class)
- 예측된 클래스(Predicted Class)
- TP(True Positive) : 실제 환자에게 양성판정 (참 양성)
- FN(False Negative) : 실제 환자에게 음성판정 (거짓 음성)
- FP(False Positive) : 건강한 사람에게 양성판정 (거짓 양성)
- TN(True Negative) : 건강한 사람에게 음성판정 (참 음성)

| 평가 점수 | 수식 | 설명 |
|---|---|---|
| 정밀도 Precision | positive라고 예측한 비율 중 진짜 Positive의 비율 즉, Positive라고 얼마나 잘 예측하였는지 | |
| 재현율 Recall = 민감도 Sensitivity | 실제 Positive 데이터 중 Positive라고 예측한 비율 | |
| F1 Score | Precision과 Recall을 평균값을 통해 하나의 값으로 나타내는 방법 0~1사이에서 0에 도달할 수 록 최악의 점수, 1에서 가장 좋은 값에 도달함 |
3. 분류모델 step
- 필요한 모듈 import 하기
- 데이터 준비
- 데이터 이해하기
- Feature Data 지정하기
- Label Data 지정하기
- Target Names 출력해 보기
- 데이터 Describe 해 보기
- train, test 데이터 분리
- X_train, X_test, y_train, y_test 분리하는 방법
train_test_splittrain_test_split(iris_data, iris_label, test_size=0.2, random_state=7)- random_state(or random_seed) : random 하게 불러올 때 random state를 지정함으로써 리플레이가 가능하게 하는 것
- X_train, X_test, y_train, y_test 분리하는 방법
- 다양한 모델로 학습시켜보기
.fit(train data, test data)- Decision Tree 사용해 보기
- Random Forest 사용해 보기
- SVM 사용해 보기
- SGD Classifier 사용해 보기
- Logistic Regression 사용해 보기
- 모델 평가
.prediect(test data): 모델 예측accuracy_score(): 정확도 측정
🤔macro average와 weighted average는 각각 언제 쓰는 것일까?
참고자료
1. 머신러닝에서 사용되는 평가지표
2. sklearn.metrics.f1_score
3. 분류 선능평가
ROC 곡선을 그려서 모델건 성능 차이 그래프를 보고 싶으면 다중 클래스를 이진화 하여야 가능함
ROC 곡선은 일반적으로 분류기의 출력을 연구하기 위해 이진 분류에서 사용됩니다.
참조 : Receiver Operating Characteristic (ROC)
