
cGAN
- Conditional Generative Adversarial Nets
- 조건없는 생성모델(unconditioned generative model)의 단점을 보완한 모델
- ex) GAN
- 단점 : 생성하는(Generater) 데이터를 제어하기 힘듦 (⛔ 무슨 의미이지??)
- 내가 원하는 종류의 이미지를 생성할 수 있도록 고안된 방법
| GAN | cGAN | |
|---|---|---|
| 구조 | (Generator) 및 (Discriminator) 두 신경망이 minimax game을 통해 서로 경쟁하며 발전 | GAN의 입력값 을 조건부확률 로 바꿔 사용함 (💡 MNIST 데이터셋을 학습할 경우 는 0~9의 label 정보 ⇨ 일종의 가이드 역할❗) |
| 목적 함수 | | |
| 학습 과정 |  |  |
| - 노이즈 (파란색) 입력 → 특정 representation(검정색)으로 변환 → 가짜 데이터 (분홍색) 생성 | - 노이즈 & 추가정보 입력 → representation(검정색) 변환 → 가짜 데이터 (분홍색)를 생성 💡 : 레이블 정보, one-hot 벡터로 입력 | |
| - 실데이터 (파랑색)와 검정색을 각각 입력 → 실제와 가짜를 구별(보라색) | - 실데이터 (파랑색)와 검정색을 각각 입력 → 실제와 가짜를 구별(보라색) 💡 와 는 동일한 한쌍으로 이뤄짐 ("7"이라 쓰인 이미지의 경우 레이블도 7) |
⛔ 분홍색이 아닌 검정색을 로 가져가는게 신기하군
- Generater ()
- 목표 : 를 입력받아 생성한 데이터 를 가 진짜 데이터라고 예측할 만큼 진짜 같은 가짜 데이터를 만들도록 학습
- Discriminator ()
- 목표 : 진짜 데이터()를 진짜로, 가짜 데이터()를 가짜로 정확히 예측(판단)하도록 학습
2. Pix2Pix
- 이미지를 입력으로 하여 원하는 다른 형태의 이미지로 변환시킬 수 있는 GAN 모델
- 한 이미지의 픽셀에서 다른 이미지의 픽셀로(pixel to pixel) 변환한다는 뜻
- Conditional Adversarial Networks로 Image-to-Image Translation을 수행
- Image-to-Image Translation : 이미지 간 변화
Generator
-
어떠한 이미지를 입력받아 변환된 이미지를 출력
-
입력이미지와 변환된 이미지의 크기는 동일해야 함
-
Generator를 구성하는 방법
-
Encoder-decoder 구조
- Encoder : 이미지()를 입력 → 단계적으로 이미지를 down-sampling & representation을 학습
- Decoder : 이미지를 다시 up-sampling하여 입력 이미지와 동일한 크기로 변환된 이미지()를 생성
- bottleneck : Encoder의 최종 출력, 입력 이미지()의 가장 중요 Feature
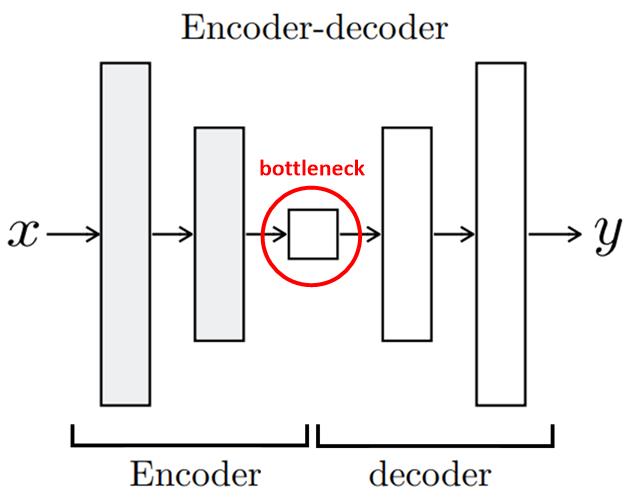
-
U-Net 구조
+ segmentation 작업을 위해 제안된 구조
+ Encoder-decoder 구조와 차이점 : 각 레이어마다 Encoder와 Decoder가 연결(skip connection)됨
+ Decoder가 변환된 이미지를 더 잘 생성하도록 Encoder로부터 더 많은 추가 정보를 이용하는 방법
+ U-Net 구조가 Encoder-decoder 구조보다 더 선명한 결과을 얻음


-
loss function
출력된 이미지와 실제 이미지의 차이로 L2(MSE), L1(MAE) 같은 손실을 계산한 후 이를 역전파하여 네트워크를 학습하여도 이미지 변환은 가능하지만 이미지의 품질이 좋지 못하다는 단점이 있음

- L1 : Generator(L1(MAE)이나 L2(MSE) 손실)만으로 생성된 결과 ⇨ 흐릿한 이미지 출력
- cGAN : 비교적 세밀한 정보를 표현
- L1+cGAN : 논문에서는 가장 좋은 결과라 표현함
Discriminator
- 하나의 이미지가 Discriminator의 입력으로 들어오면, convolution 레이어를 거쳐 확률값을 나타내는 최종 결과를 여러개 생성함
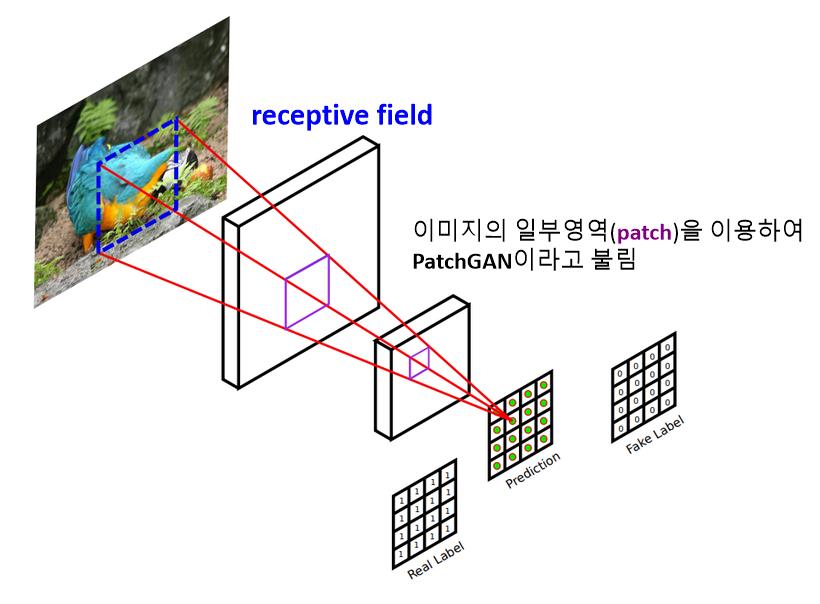
⛔ 위와 같은 Discriminator을 쓰는 GAN들을 patchGAN이라 부를 걸까?

- 70X70 patch : Discriminator입력 이미지에서 70x70 크기를 갖는 일부 영역에 대해서 하나의 확률값을 출력 ⇨ 4개의 이미지 중 가장 사실적인 이미지를 생성함
- 16x16 patch, 1x1 patch로 갈수록 더 작은 영역을 보고 각각의 확률값을 계산하므로 Discriminator의 출력값의 개수가 더 많음
- 286X286 patch : DCGAN의 Discriminator와 같이 전체 이미지에 대해 하나의 확률값을 출력하여 진짜/가짜를 판별하도록 학습한 결과
DCGAN
DCGAN의 Discriminator는 생성된 가짜이미지 혹은 진짜이미지를 하나씩 입력받아 convolution 레이어를 이용해 점점 크기를 줄여나가면서, 최종적으로 하나의 이미지에 대해 하나의 확률값을 출력

