1. 자연어 처리
1) 정의
- 자연어 : 사람들이 일상적으로 사용하는 언어
- 자연어 처리 : 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 묘사할 수 있도록 연구하거나 구현하는 분야
- ex) 정보 검색, QA 시스템, 문서 분류, 클러스터링, 챗봇 등
2) 한국어 특징
(1) 구성 요소
| 설명 | 예시 | |
|---|---|---|
| 음운 | 말의 뜻을 구별해주는 소리의 최소 단위 | ㄱ,ㄴ,ㄷ, ... , ㅏ,ㅑ,ㅓ,... |
| 음절 | 독립하여 발음할 수 있는 최소 소리 단위 | 가,나,다,...,헿 & 모음은 따로 독립가능 |
| 형태소 | 뜻을 가진 가장 작은 말의 단위 (단, 자립할 수 있는 어휘형태소만 해당) | 명사, 형용사, ... |
| 단어 | 자립적으로 쓸 수 있는 말, 조사는 예외 | 사과, 기린, 토끼 |
| 어절 | 문장을 구성하고 있는 각각의 마디로, 대개 띄어쓰기 단위와 일치 | |
| 구 | 둘 이상의 단어가 모여 절이나 문장의 일부분을 이루는 문법의 단위 | 명사구, 동사구, 형용사구, ... |
| 절 | 주어-서술어 관계를 가지고 있으나 독립적으로 사용 불가 | 명사절, 형용사절, 부사절 |
| 문장 | 주어와 서술어를 가지고 있는 완결된 최소의 언어 형식 |
(2) 문장 성분
- 문장의 문법적인 역할 : 주어, 서술어, 보어, 목적어, 부사어, 관형어, 독립어
- 주성분 : 문장을 구성하는 뼈대가 되는 요소
- 주어, 서술어, 보어, 목적어
- 부속성분 : 주성분을 수식하는 요소
- 부사어, 관형어
- 독립성분
- 독립어
- 감탄사, 느낌, 놀람, 부르는 말, 대답하는 말
3) 주요 task
(1) 카테고리 분류
- 이진 분류 ⇨ ex) 스팸 이메일 분류기
- 다중 분류 ⇨ ex) 감성 분류(긍정/부정/중립)
[읽기자료]
(2) 키워드 추출
- 문서의 단락을 요약하여 표현하거나, 문장에서 중요한 키워드를 추출하는 방법
- TextRank : word graph나 sentence graph를 구축한 뒤, graph ranking 알고리즘인 PageRank를 이용하여 각각 키워드와 핵심 문장을 선택하는 방법
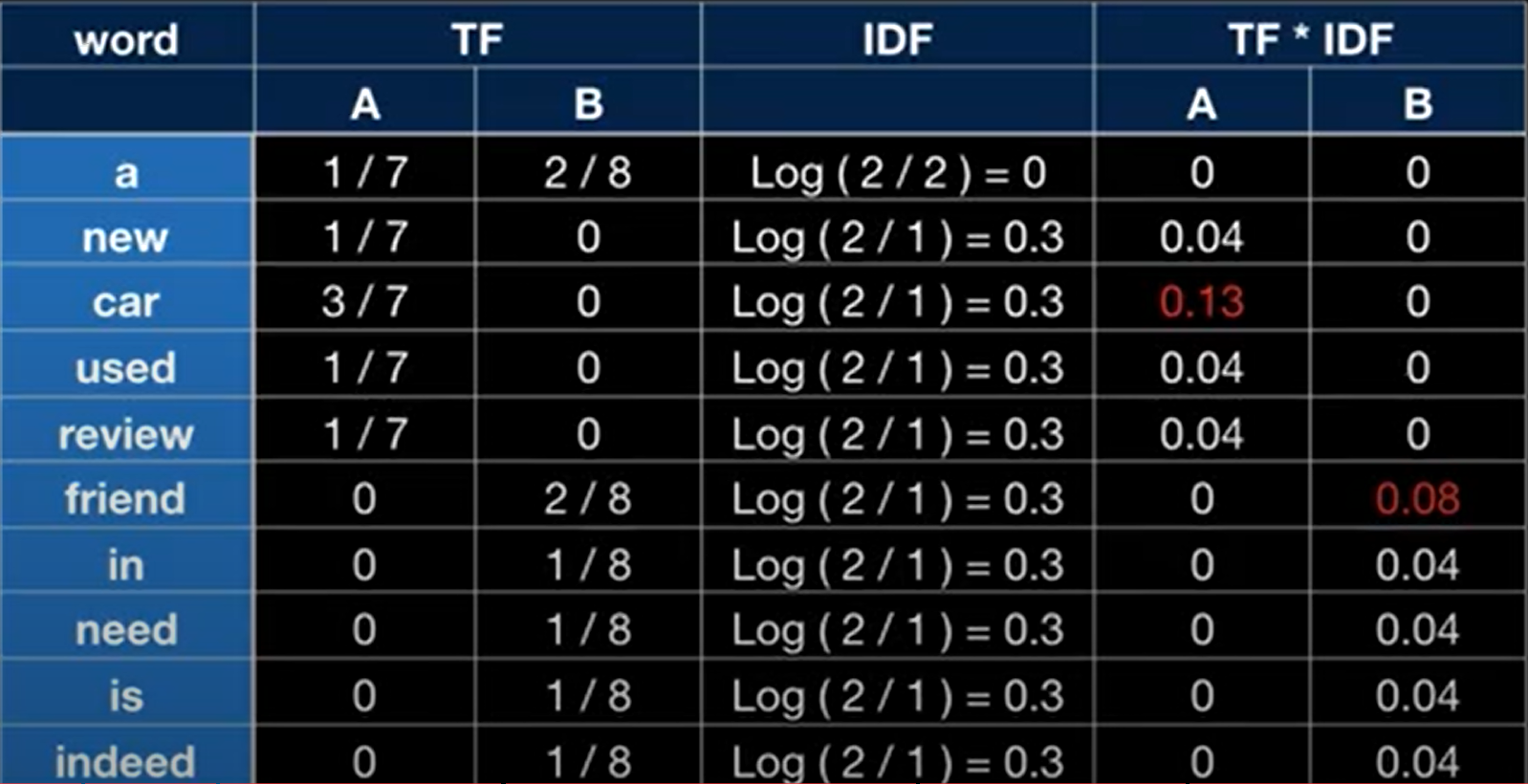
- TF-IDF : TF(Term-Frequency) + IDF(Inverse Document Frequency)
- TF : 특정 단어가 한 문서내에 얼마나 자주 등장하는지를 나타내는 값
- IDF : 특정 단어가 얼마나 적은(Inverse이므로) 문서에서 등장하는지를 나타내는 값입
2. 데이터 전처리
1) 토큰화(Tokenizing)
- 문장을 일정한 단위로 나누는 작업
- 토크나이저(Tokenizer) : 토큰화 작업을 해주는 것
- 토큰의 기준
- 한국어 : 형태소
- 영어권 : 단어(word)
- 음절, subword 등
- 형태소 분석기 : 문장을 형태소 단위로 분절해 주는 것
- 대표적인 한글 분석 패키지 : KoNLPy
- KoNLPy : 5개 형태소 분석기(Mecab, Kkma, Komoran, Hannanum, Okt)를 포함
2) 불용어(stopword) 제거
- 불용어 : 특별한 의미를 가지지 않는 단어(조사, 자주 등장하는 단어 등)
- ex : 나(NP), 있(VA), 이(NP), 지금(NNG) 등
- 품사판별
- 5언 : 체언(명사, 대명사, 수사), 용언(형용사, 동사), 수식언(관형사, 부사), 관계언(조사), 독립언(감탄사)
- 9품사 : 명사, 대명사, 수사, 형용사, 동사, 관형사, 부사, 조사, 감탄사
- 용언 : 형태소인 어간과 어미로 구성
- 품사판별
3) Subword Tokenizer
- 빈도가 잦은 단어는 유지하고, 저 빈도의 단어는 의미 있는 단위로 분절함
- 특징 : 사전에 언어학적인 지식 없이 말뭉치에서 나타난 단어들의 경향(확률)을 보고 단어를 분절 ⇨ 형태소 분석기와 차이점
- 대표적인 패키지 : BPE(Byte Pair Encoding), WordPiece, Unigram, SentencePiece 등
3. word2vec
- Word embedding
- 비정형화된 텍스트를 컴퓨터가 이해할 수 있도록 숫자로 바꿔줌
- 사람의 언어를 컴퓨터의 언어로 번역하는 것
- 원핫 인코딩
- 표현하고자 하는 단어의 인덱스 값만 1로 하고, 나머지 인덱스는 전부 0으로 표현되는 벡터로 나타내는 방법
- 희소 표현(sparse representation) : 벡터 또는 행렬의 값이 대부분 0으로 표현되는 것
- 단점
+ 차원의 저주에 빠지기 쉬움
+ 각 단어간의 유사성을 표현할 수 없음
+ 단어 집합의 크기만큼 0이 차지하는 공간이 커지는 한계有

- 분산 표현(distributed representation)
- 다차원 공간에 벡터화하는 방법
- 밀집된 벡터로 표현 가능
- 저차원에 여러 단어를 분산하여 표현하기 때문에 단어간 유사도를 계산할 수 있음
- ex) word2vec

- word2vec
- 단어를 벡터로 변환하는 방법 중 하나로 어떤 분포 가설을 가정하고 그에 맞춰 표현한 분산 표현을 따르는 방법
- 학습 방법
+ CBOW : window 단어들을 기준으로 하나의 중심 단어를 예측하는 방법
+ skip-gram : 하나의 중심 단어를 기준으로 window 단어들을 예측

- word2vec 옵션
| 옵션 | 설명 |
|---|---|
| vector_size | - 단어 벡터를 몇 차원으로 지정할 것인가 - 주로 많이 사용하는 차원은 300 |
| window | - window 크기를 사용자가 지정 - window : word2vec의 주변 단어를 의미 |
| epochs | - 학습 횟수 |
| sg | - 학습 방법 선택 - 1 : skip-gram / 0 : CBOW |
| min_count | - 토큰이 되기위한 최소 빈도수를 지정(default= 5) |
4. FastText
- 단어를 벡터로 만드는 또 다른 방법, Facebook의 FastText(ex.
gensim) - Word2Vec의 확장판
- 하나의 단어를 N-gram 단위로 분절할 수 있음(N : 3~6)
- 특징 : 노이즈가 심한 말뭉치에 강건함


👍👍