목표 :
신경망을 어떻게 학습시키는지 알아보자
NN의 설정, 학습, 평가 알아보자
- transfer learning
- finetuning
- 이미 학습된 가중치 모델을 새로운 네트워크를 학습시킴
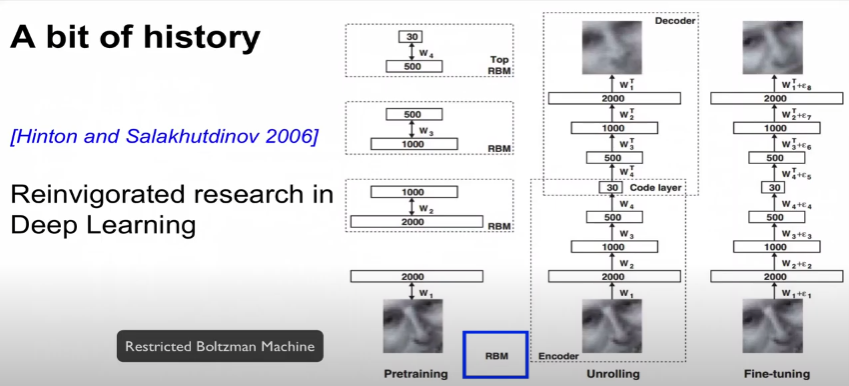
💡 참고자료 : 전이학습과 finetuning

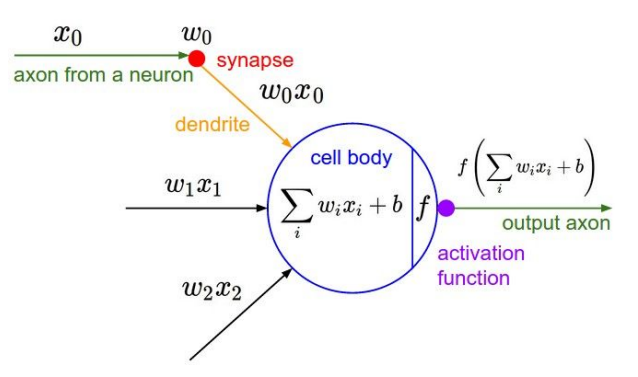
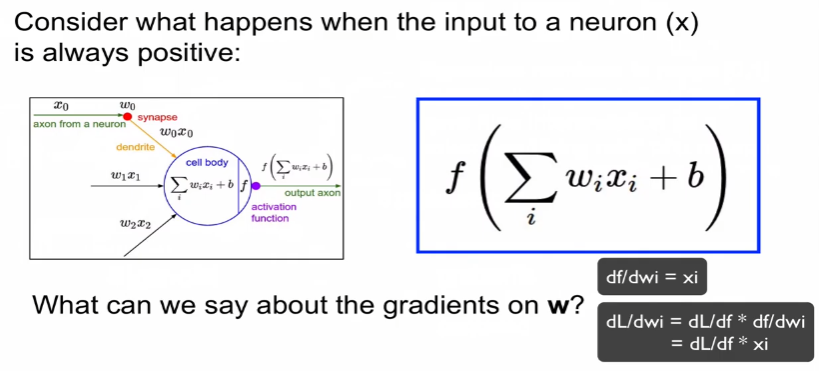
1. 활성 함수(Activation Function)

1) Sigmoid

- 현재는 쓰지 않음
- vanishing gradient 발생 : 포화된 뉴런은 주
- x에 대해 미분을 하면 거의 '0'이 나오게 되는데, "x가 꾀 크거나 작으면"(포화 지점) local gradient가 0이 되어 sparce 하게 됨
- zero-centered 0을 중심으로 되지 않아 매우 느리게 coversionce가 생김.

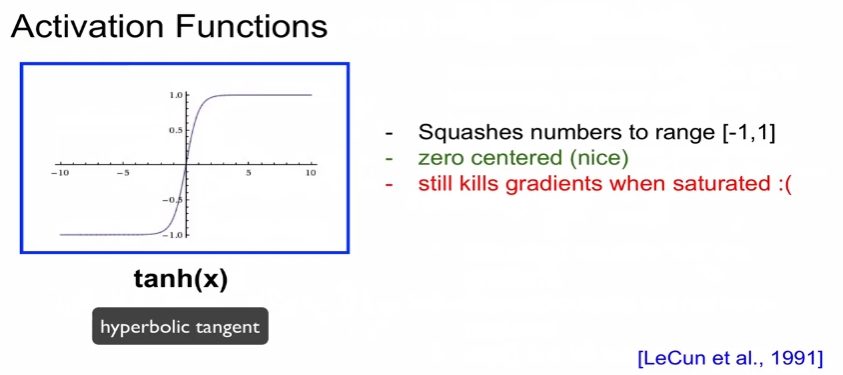
2) tanh(x)
3) ReLU
- 현재 가장 default로 사용하는 activation function
- 양수에서 saturate(포화)이 발생되지 않음
- 연산이 효율적이다.
- 단점 : 0보다 작을 때는 기울기가 여전히 '0'이 된다.
- dead ReLU : data cloud 외부에서는 activate가 되지 않고 업데이트가 되지 않는다. 뉴런의 값이 업데이트를 하다가 data cloud를 넘어서는 경우가 생겨 update가 되지 않는 경우가 있음. 약 10퍼센트
- dead ReLU를 방지하기 위해 0이 아닌 아주 작은 0.0001 같은 learning rate를 넣어주게 된다.
4) Leaky ReLU
- Relu의 보안점

5) ELU

- Relu의 장점을 가지고
- 단점 :
6) Maxout
- 두개 파라미터를 가지고 있어 연산량이 2배로 늘어나는 단점이 있다.
정리

2. 데이터 전처리(Data Preprocessing)
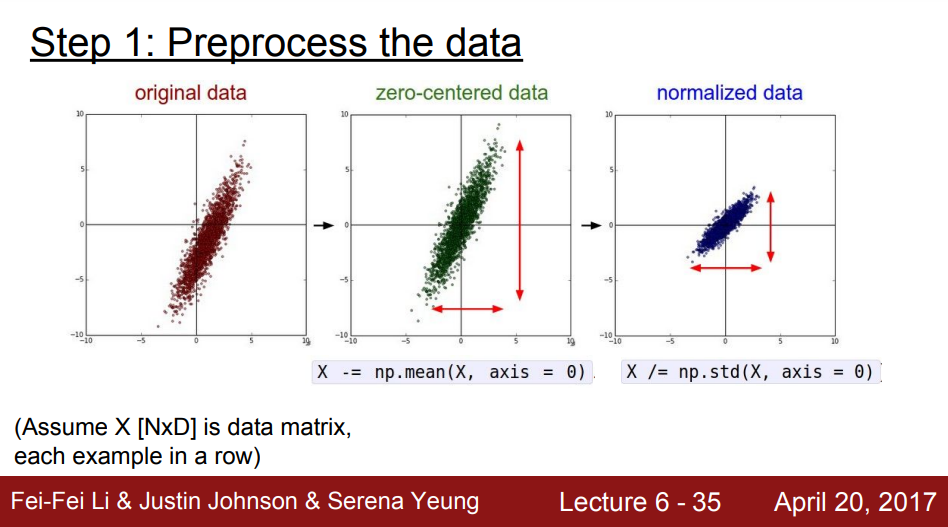
- 하지만 이미지에서는 zero-centered는 일반적으로 해주지만 Normalized는 해주지 않는다.
- Why? 0~255라는 특정 범위에 이미 들어가 있기 때문
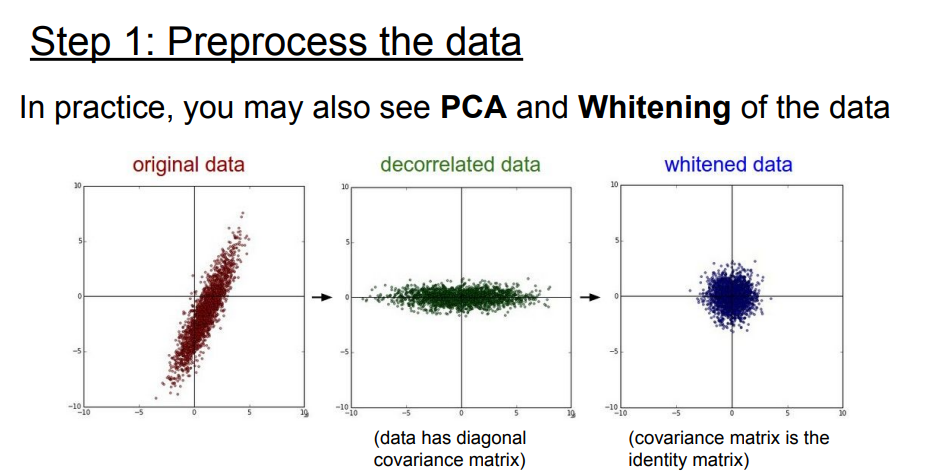
- 이미지에 관해서는 pca와 whitened는 해주지 않는다.
- pca :
- whitened : 인접하는 픽셀 간의 중복성
∴ 이미지에서 전처리는 zero-centered만 신경써주면 된다.
방식
- 평균 이미지를 빼주는 것
- 각 채널별로 mean값을 빼주는 것(훨씬 편리)
3. 가중치 초기화(Weight Initialization)

- 동일한 연산을 수행하게 됨
- symentric waiting이 발생 하지 않음
때문에 가중치 초기화하는 아이디어
1. 작은 범위의 random number를 사용한다.
- 문제점 : 네트워크가 커지면 std 0으로 수렴 => 모든 activation이 0이 된단는 것. => vanishing gradient가 발생한다.
- input의 갯수를 2로 나눠준다.
4. Batch Normalization
- vanishing gradient가 일어나지 않도록 하는 아이디어
- 학습하는 과정에 직접 안정화되게 만들어주는 방법
- 입력값을 평균과 분산으로 정규화해주는 방법
- 이전까지는 학습 => 간접적 적용하는 방법
- 여태까지는 activation 함수 적용
- 가중치 초기화를 신중하게 함
- train에서는 mean과 std를 미리 계산하여 batch 크기로 훈련하게 되지만 test에서는 전체를 테스트한다
- 장점
- 네트워크 상에서 gradient flow를 개선해 줌
- 높은 학습율을 사용할 수 있다 ⇨ 보다 빠른 학습이 가능
- 초기화에 너무 의존 하지 않아도 됨
- batch normalization 자체가 regularization해주는 효과를 얻는다.
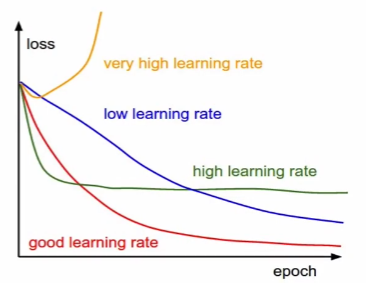
💡 learning rate이 너무 작을때, 너무 큰수를 사용했을땐 어떤 일이 발생하는 가?
(정리해보자)

적절한 learning rate를 찾기 위해서는 cross validation을 진행하여야 한다.
5. Hyperparameter Optimization
-
cross validation 전략 : -> fine
first step :
second step : -
Finer Search : Random vs Grid
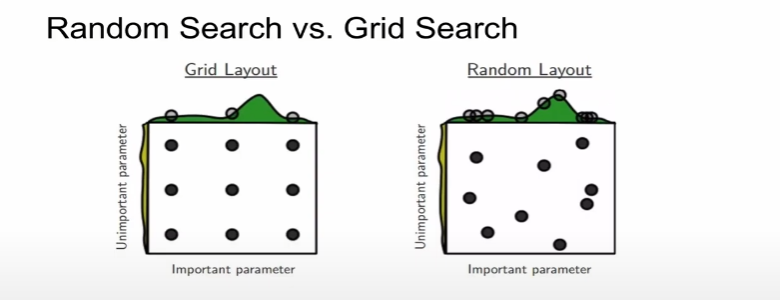
-
언제 hyperparameter를 필요한가?
- network architecture : 노드의 수, hidden layer의 수 등
- learning rate, its decay schedule, update type
- regularization(L2, Dropout strength)
-
이 많은 것을 가지고 모니터링 대상
-
loss 값
-
accuracy : loss 보다 수치에 대한 해석이 가능함(∵ 모니터링 대상으로 선호됨)
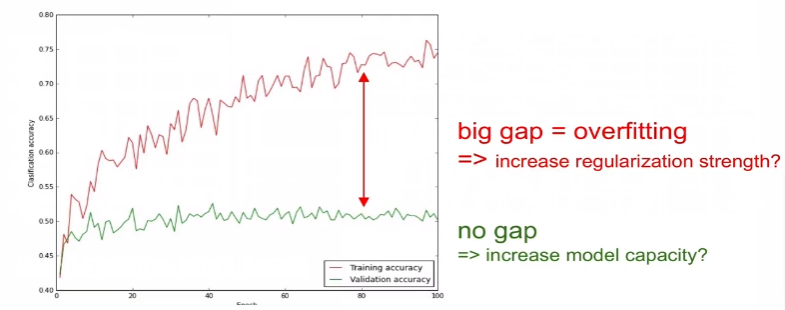
- 보통 gap이 생기는 것이 정상이나
- 아래의 이미지와 같이 gap이 너무 클 때는 Overfitting을 의심!
- regularization strength을 높일 필요 있음
- 오히려 gap이 없는 경우, capacity(파라미터의 수)를 증가(조정)해야 함
-
weight updates/weight magnitudes의 비
파라미터가 한번 update 되는 크기를 전체 파라미터의 크기로 나눠준 것임
약 1/1000 수준이 되고 있는지 확인
