MLP 신경망의 학습***
- 딥러닝의 "학습" = 전파 + 역전파
- 전파 1회 + 역전파 1회 -> epoch - 전파(순전파 : Foward Propagation)
- 입력이 들어와서 최종출력값을 계산하는 일련의 과정 - 역전파(Back propagation)****
- 최종출력갑싱 원하는 결과값이 아닐 경우 오차값을 줄이기 위해
- 편미분(최종결과값에 입력값의 기여도 계산) - 목표치가 달성되면 학습 종료
- 학습중에는 가중치가 변경 -> 종료되면 가중치가 고정
ex) 야구를 예시로 들면..?
WAR을 예로 들면 쉽게 알 수 있다.
1승을 했는데 팀원별로 승을 나눈다.= 전파
실제 성적 데이터 -> war -> 예측 성적
팀 성적 편미분 -> 개별 선수의 기여도
개별 선수 WAR의 합 = 팁 WAR(예측 성적)
입사할 때 류현진은 한 이닝에 공 한 번 던질때 천만원씩번다.
류현진 2000천만불
2000만불
25-30번 등판
150~200이닝
1이닝 당 10만 불
1이닝당 투구수
13개 / 이닝당
7이닝 투구
1구당 가치
1구 천만원
우리나라 연봉에는 WAR 같이 계산할 수 있는 시스템이 없음,.,
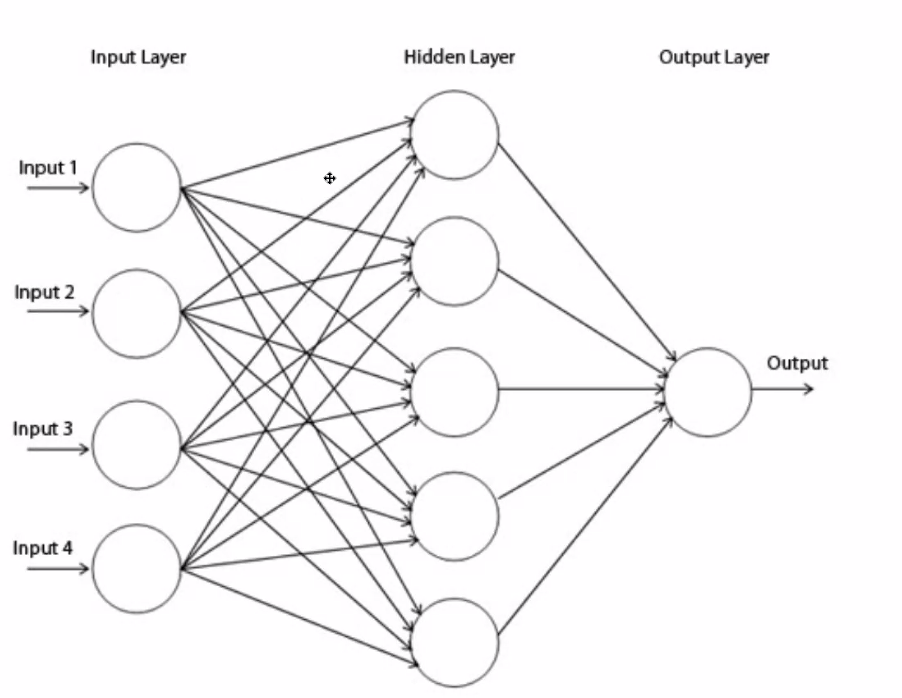
MLP 신경망의 학습***
-MLP는 퍼셉트론을 여러 단 쌓은 것
- 최초입력 ->출력 입력 출력 .. 입력 -> 최종 출력
- DNN
기울기 손실 문제
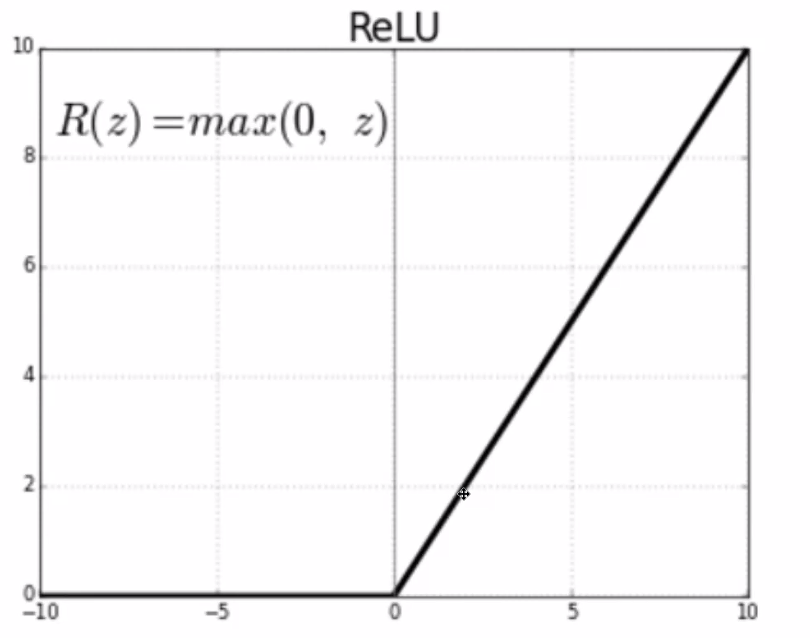
돌파구 - ReLU(Rectifed Linear Unit)
- 시그모이드의 대체재, 2006년 힌튼 교수 연구팀에서 제안
- MaxOut 특성을 이용
- 렐루 덕분에 수 백개 히든레이어가 깊어져도 학습 가능
역전파 과정에서 가중치 값이 제대로 나오고, 계산난이도가 급격하게 감소 - 현재는 다양한 활성화 함수(하이퍼볼릭 탄젠트, 릭키 렉루)
- 둘 다 학습이 가능한 상황에서는 오히려 시그모이드가 더 잘 됨? -> 히든레이어가 적은 경우 시그모이드가 잘 나오는 경우가 있으므로, 상황에 따라 사용
- 지수함수 미분 vs 1차함수 미분
돌파구 - GPU
-
계산량 문제
- 병렬처리 기술의 발전으로 많은 계산을 동시에 가능
- GPUPU(General Processing on GPU) -
그래픽 연산에 최적화된 GPU를 일반계산에 사용하는 기술
- CPU의 코어 = GPU의 스트림 프로세서
라이젠 5950 vs 지포스 3080
GPGPU
- 그래픽 연산에 최적화된 GPU를 일반계산에 사용하는 기술
- CPU의 코어 = GPU의 스트림 프로세서 - 표준 OpenCL(Computing Language) vs NVIDA CUDA
- CUDA > OpenCL - 텐서플로는 기본적으로 CUDA에 최적화된 기술
- OpenCL버전은 버전이 낮고 늦게 나옴(상대적) - 텐서플로
- CUDACUDA
-GTX/RTX(게임용 / Direct) -> FP(실수연산) 정밀도(단정밀도)
-Quadro(CAD/OpenGL) -> 배정밀도
-전용딥러닝카드 v100 A100
-cf. 텐서코어 -> 행렬연산
결과
- Relu
- 편미분계산 난이도 낮춤 (시그모이드 대비)- Vanishing Gradient 문제 해결
- GPUPU
- MLP의 많은 계산량 해결
- 결과
- 더 많은 히든층을 넣어 계산가능
- 수 백 계층가진 딥뉴럴네트워크(DNN)을 계산할 수 있음
- 현재 ResNet-152
Keras는 MLP만 이해해도 괜춘..?
하이퍼파라메타..

로스함수,
절차만 이해하면 쉽다.
하이퍼파라메타만 이해해보자.
시퀀셜모델과 펑셔널모델(고급)로 본다.
일반적으로 시퀀셜모델로 한다.
텐서플로 기본

텐서플로 1과 2의 코드가 완전히 다르다!
non-eager = 1
line by line 방식 = eager2
Keras란?
- 구글 엔지니어인 프랑소와 쏠레가 만듦
- 파이썬 기반 하이레벨 뉴털네트워크 딥러닝 라이브러리
- 텐서플로 , Theano, CNTK 지원 - 텐서플로우 2.0부터 Keras가 필수로 변경!!
- 간단한 정의 (Sequantial 모델)
- MLP에 최적화..굉장히 직관적이고 깔끔하다!
- 하지만 전체 신경망 시스템을 이해하고 있어야 함 - 케라스 vs 텐서플로 : 원래는 필수/권장/선택
