
활성화함수 종류
-tahn : Sigmoid 함수를 재활용하기 위한 함수, 일반적인 시그모이드는 0과 1사이 값이지만, tahn은 -1~1까지 값을 가진다.
-ReLu : Max(o, x)처럼 음수에 대해서만 0으로 처리하는 함수
-Leaky ReLu : Relu 함수의 변형으로 음수에 대해 1/10로 값을 줄여서 사용하는 함수
-ELU : ReLu를 0이 아닌 다른 값을 기준으로 사용하는 함수
-Maxout : 두 개의 w와 b 중에서 큰 값이 나온 것을 사용하는 함수
Q. ReLu를 쓰지 sigmoid는 안 쓰는가?
Relu -> 딥한 신경망에서 학습이 안 되는 문제 해결
sigmoid -> 얕은 신경망에서는 여전히 유효하다.
옵티마이저
-손실함수를 목표치(0)까지 구할 떄 사용하는 최적화기법
- 문제(회귀/분류-이항 or 다항) 별로 다양한 손실함수가 제안됨
-기본적인 옵티마이저 : 경사하강법(신경망에서 정말 중요하다)
손실(loss)함수의 종류
-회귀
- MSE / MAE / MSLE / MAPEKLD / Poisson / Logcosh ...
-분류
- Binary cross-entropy/Categorical cross-entropy/Sparse categorical ..
Gradient Descent
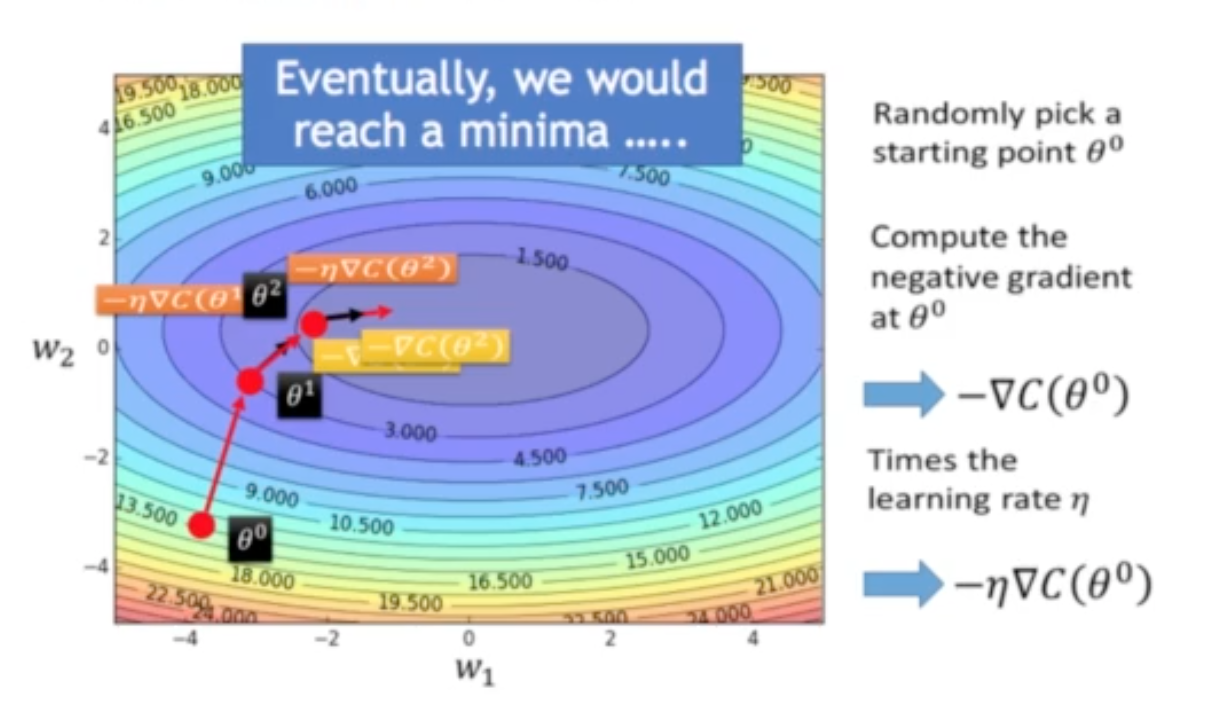
함수를 미분 = 0 -> 극값(접선의 기울기가 0이 되는 값)
-손실함수를 최소화하는 값을 찾을 때 사용
-convex타입(단조증가/감소)의 경우에만 적용이 가능
-local minimum(지역최소값)을 찾는 데 사용
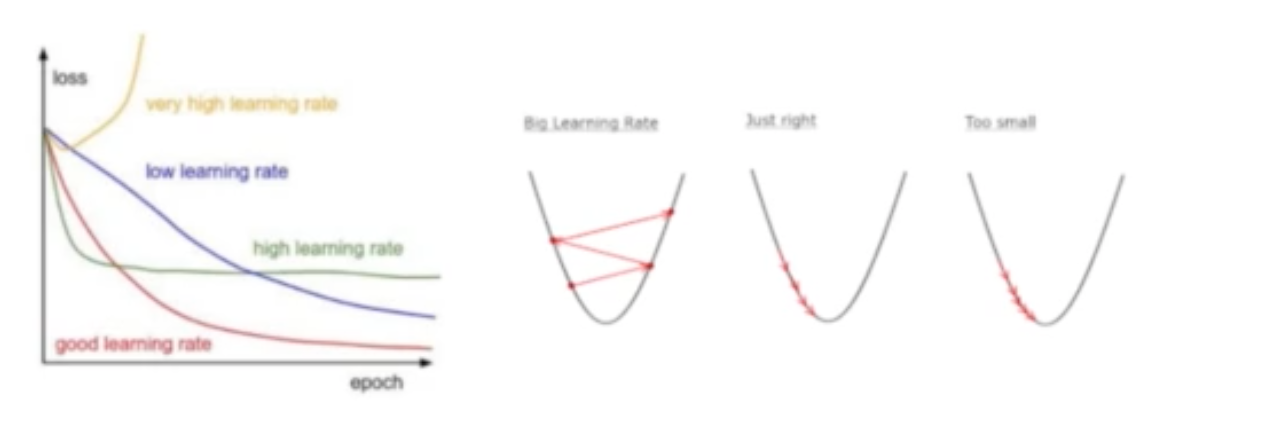
Learning Rate
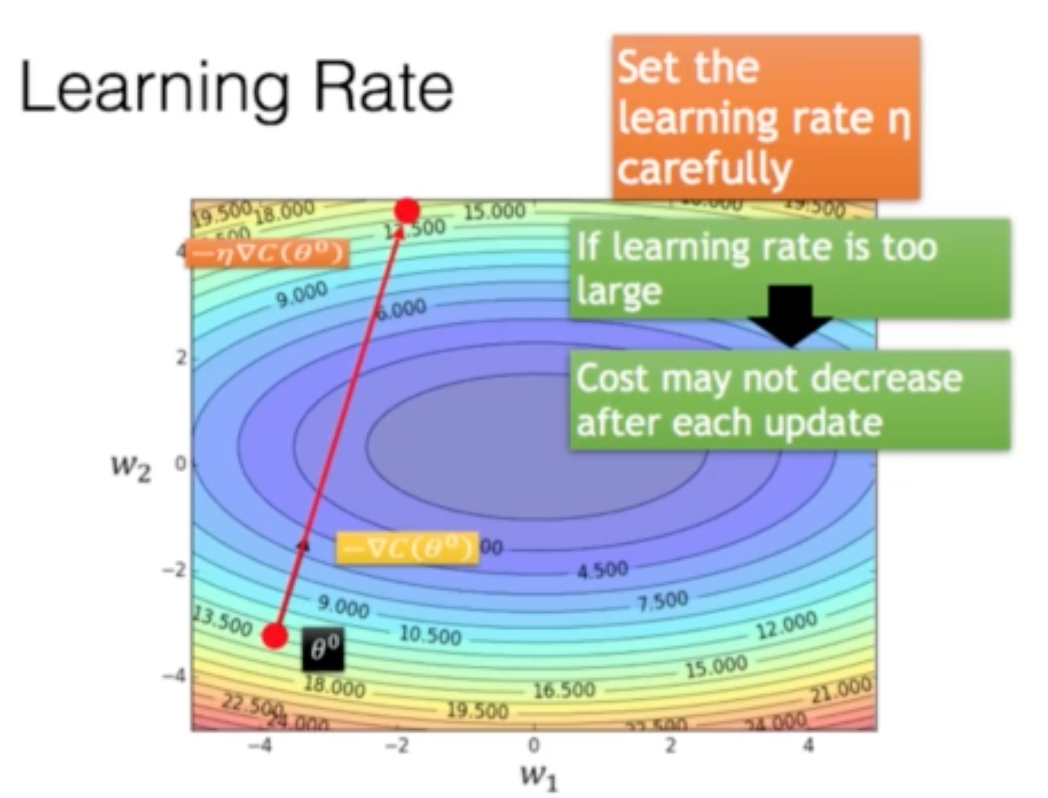
-경사하강법에서 기울기에 학습률(보폭)을 곱해 다음 값을 결정
-최적값을 구하기 쉽지 않은 문제가 있다(직접 다 돌려봐야함)
-빨간색 간격을 학습률 (Learing rate)라고함
-경사하강법에서 기울기에 학습률(보폭)을 곱해 다음 값을 결정
-최적값을 구하기 쉽지 않은 문제가 있다.
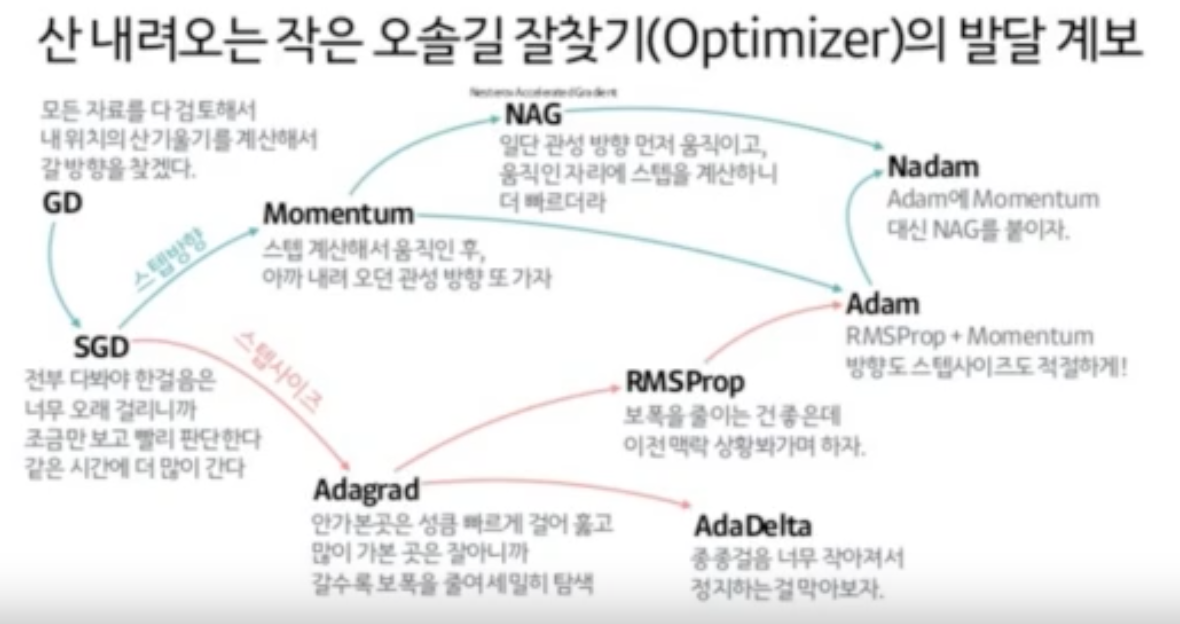
옵티마이저의 종류
-Gradient Desent
-stochastic GD(SGD)
-Momentum
-Adagrad :
-Adadelta
-AdagradDA
-RMSprop
-Adam : 보폭 + 관성
Q. ADAM이 제일 좋은건가? --> 경험적으로 옵티마이저를 다 적용시켜봐야한다.

이항분류 / 다항분류
-이항분류 : 2개의 값 중에서 선택
-다항분류 : 여러 개의 값 중에서 선택
ex)
0입니까? 0이 아닙니까 --> 이항분류
0~9 사이의 숫자 중 어느 것입니까? --> 다항분류
다항분류 과정
1) 이항 분류 함수를 각각 적용(결국 이항 분류를 여러번 적용=개별 이항 분류)
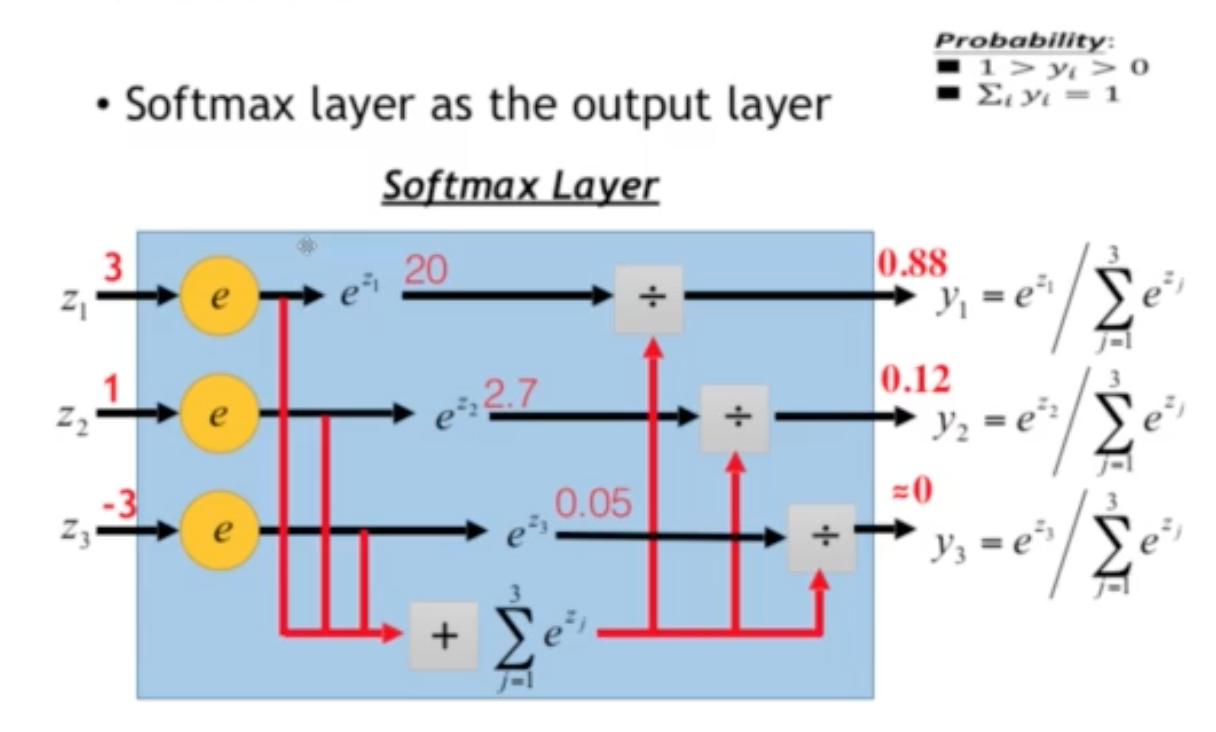
2) Softmax 처리 : 전체를 1로 만드는 작업
3) one-hot인코딩 : 주성분만 남기고 나머지를 버리는 과정

Softmax
One-hot Encoding
-하나의 주 성분만 가지도록 처리

다항분류(케라스)
-케라스에서는 NLP의 마지막 레이어를 분류할 종류 수 만큼 노드를 지정하고 활성화함수로 "Softmax" 지정
-손실함수를 "Cateogorical_Crossentropy"지정(원핫인코딩?)
- 이항분류의 경우 손실함수를 MSE 지정
- 활성화 함수는 "sigmoid /relu"
예시

위에서 Dense 뒤 10이 의미하는 것은 분류할 문제 수(예를 들어 감정 종류의 수 10개)
다항분류의 예시가 됨.
model.fit : 학습을 진행, 학습용이미지
6만개/학습용데이터
model.evaluate : 테스트 진행, verbose =로그를 어떤 레벨로 남길것인가??)

0.067의 의미는? = 로스값
0.9788 = 정답률
