Pytorch로 손글씨와 Mnist를 분류해보자(이번 시간은 코랩으로 실습만 진행.!!)
%matplotlib inline
import matplotlib.pyplot as plt # 시각화를 위한 맷플롯립
from sklearn.datasets import load_digits
digits = load_digits() # 1,979개의 이미지 데이터 로드
mnist = fetch_openml('mnist_784', version=1, cache=True)
print(digits.images[0]) 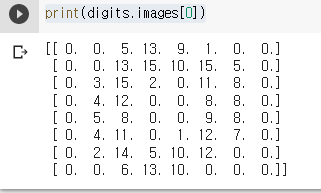
print('전체 샘플의 수 : {}'.format(len(digits.images)))
print(digits.target[0])# 첫번째 샘플의 레이블른 0이다 
for i in range(5):
print(i,'번 인덱스 샘플의 레이블 : ',digits.target[i])
# 5개 샘플 레이블확인하기 
images_and_labels = list(zip(digits.images, digits.target))
for index, (image, label) in enumerate(images_and_labels[:5]): # 상위 5개의 샘플만 출력
plt.subplot(2, 5, index + 1)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('sample: %i' % label)
# 상위 5개의 샘플을 시각화해봤는데, 순서대로 숫자 0, 1, 2, 3, 4의 손글씨인 것처럼 보인다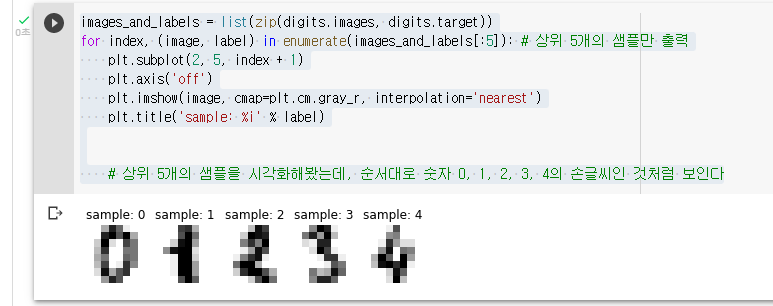
훈련 데이터와 레이블을 각각 X, Y에 저장해본다. digits.images는 모든 샘플을 8 × 8 행렬로 저장하고 있다(기존에 활용하던 mnist예제랑 다름)
더 나은 방법은 digts.data를 사용. 이는 8 × 8 행렬을 전부 64차원의 벡터로 변환해서 저장한 상태이기 때문. digits.data를 이용해서 첫번째 샘플을 출력해보자
print(digits.data[0])
# 8 × 8 행렬이 아니라 64차원의 벡터로 저장되있다. 이를 X로 저장하고, 레이블을 Y에 저장 
X = digits.data # 이미지. 즉, 특성 행렬
Y = digits.target # 각 이미지에 대한 레이블(답)파이토치로 다층 퍼셉트론 분류기 만들기
import torch
import torch.nn as nn
from torch import optim
model = nn.Sequential(
nn.Linear(64, 32), # input_layer = 64, hidden_layer1 = 32
nn.ReLU(),
nn.Linear(32, 16), # hidden_layer2 = 32, hidden_layer3 = 16
nn.ReLU(),
nn.Linear(16, 10) # hidden_layer3 = 16, output_layer = 10
)
X = torch.tensor(X, dtype=torch.float32) # 실수텐서
Y = torch.tensor(Y, dtype=torch.int64) # 8바이트 정수텐서
loss_fn = nn.CrossEntropyLoss() # 여기서 손실 함수는 소프트맥스 함수를 포함하고 있음.
optimizer = optim.Adam(model.parameters())
losses = []
for epoch in range(100):
optimizer.zero_grad() # 누적안되게 초기화 하는거
y_pred = model(X) # forward 연산, 모델을 지정하고 나서 x값을 넣어서 출력값이 예측값인 y프레드 값이 나온다고 가정하면
loss = loss_fn(y_pred, Y) # 이 값의 차이가 오차다,
loss.backward() # 하나씩 증분해서 편미분하는거
optimizer.step()
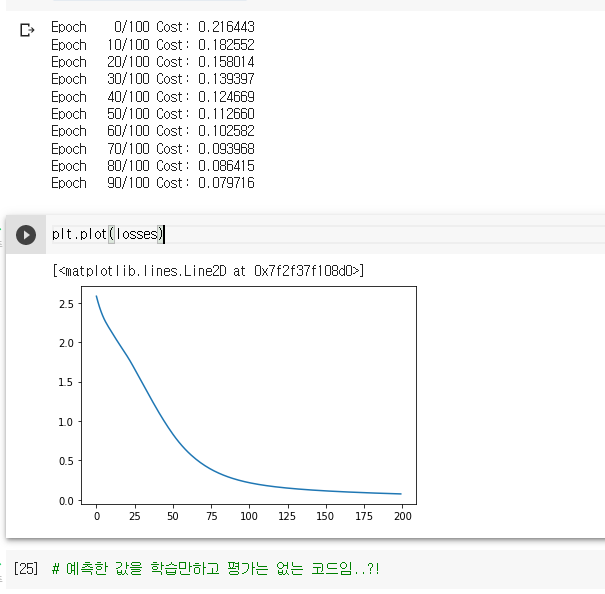
if epoch % 10 == 0: # 에포크 10번마다 찍어라
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, 100, loss.item()
))
losses.append(loss.item())
mnist 분류하기
- 앞선 소프트맥스 회귀 또한 인공 신경망이라고 볼 수 있는데, 입력층과 출력층만 존재하므로 소프트맥스 함수를 활성화 함수로 사용한 '단층 퍼셉트론'이라고 할 수 있다ㅣ,
- 이번 실습은 은닉층을 추가로 넣어 다층 퍼셉트론을 구현하고, 딥러닝을 통해서 MNIST 데이터를 분류해본다.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import fetch_openml
import pandas as pd에러발생!
(X[0]) 인덱싱을 해보니 데이터 프레임이라 안 된다.
그래서 데이터프레임 -> 리스트 -> np.array로 변환해주었다.
생각해보니까 df에서 arr로 바로 바꾸는건 안되나?---> 쌉가능이다.
mnist_arr = mnist.data.to_numpy()
X = mnist_arr 이렇게 바로 변환하는게 편하고 변수초기화를 두번안해도 된다.
에러 2
target은 마찬가지로 시리즈 형태여서 .values 를 통해 array 형태로 바꿔줌
그랬더니
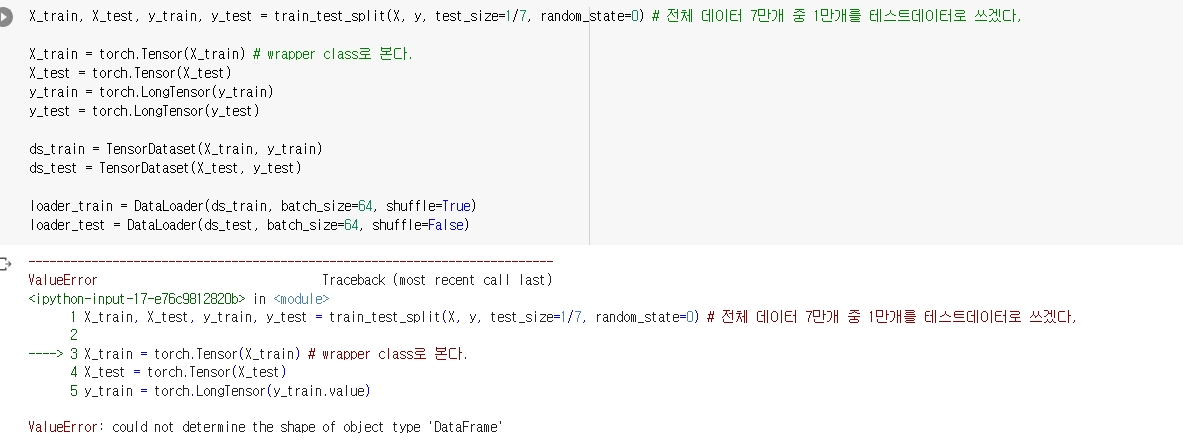

바로 해결되었다!
mnist = fetch_openml('mnist_784', version=1, cache=True)
mnist.target = mnist.target.astype(np.int8)
X = mnist.data / 255 # 0-255값을 [0,1] 구간으로 정규화
y = mnist.target과적합 방지 방법
- 데이터의 양을 늘리기
- 모델의 복잡도 줄이기
- 가중치 규제(Regularization) 적용하기
-
L1 규제 : 가중치 w들의 절대값 합계를 비용 함수에 추가 ( 맨해튼 )
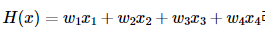
-
L2 규제 : 모든 가중치 w들의 제곱합을 비용 함수에 추가 ( 유클리드 )
model = Architecture1(10, 20, 2) optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-5)
- 드롭아웃(Dropout)
- 예를 들어 드롭아웃의 비율을 0.5로 한다면 학습 과정마다 랜덤으로 절반의 뉴런을 사용하지 않고, 절반의 뉴런만을 사용
- 단점 : 학습 시간이 많이 걸림.!
- 배치 정규화
CNN에서 보완하기 위한 방법, 정규분포
