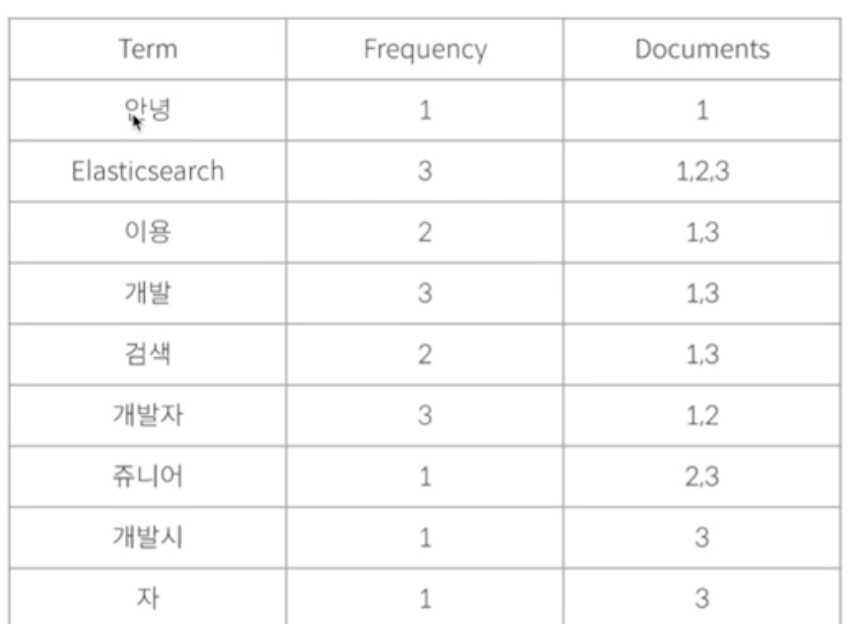
엘라스틱서치에게 루신이란 뭘까요?
4가지만 잘 기억하면된다.!!
-역인덱스 파일
-인덱스 writer = 색인
-인덱스 서쳐 = 검색
-인덱스 애널라이자 = 형태소분석?
Elastic이란? = 아파치 루신을 기본으로 한 오픈소스 분산 검색엔진이다...
루신이란?
- 아파치 프로젝트 중 하나로 정보검색 오픈소스 라이브러리..
- 루신이 하는일?? = 색인과 검색을 쉽게 추가 가능할 수 있도록 한다.(문서를 색인해 저장하고, 저장한 색인을 바탕으로 검색할 수 있도록한다.)
- 자바로 처음 만들어졌지만, 다른 언러로 포팅 가능(다른 언어간에도 색인대이터 호환가능)
-fulltext와 text를 단어로 쪼개는 방법을 제시하면 index를 자동 생성해줌
루신의 기본 개념
- 인덱스
- 문서
- 필드field
- 용어term
루신은 fulltext 검색엔진이다.
-fulltext검색이란, 단어 검색이 아닌 문서자체를 검색하는것???
-긴문장이 있으면 이를 analysis(형태소분석기)가 볼 수 있도록 prasego text로 추출하고 붆석기에 넣ㄴ음 -> 그다음 루신이 인덱스(색인)을 생성해줌
색인이란?
-
[동사] 색인 (indexing) : 데이터가 검색될 수 있는 구조로 변경하기 위해 원본 문서를 검색어 토큰들으로 변환하여 저장하는 일련의 과정입니다. 이 책에서는 색인 또는 색인 과정이라고 표기합니다.
-
[명사] 인덱스 (index, indices) : 색인 과정을 거친 결과물, 또는 색인된 데이터가 저장되는 저장소입니다. 또한 Elasticsearch에서 도큐먼트들의 논리적인 집합을 표현하는 단위이기도 합니다. 이 책에서는 인덱스라고 표기합니다.
-
검색 (search) : 인덱스에 들어있는 검색어 토큰들을 포함하고 있는 문서를 찾아가는 과정입니다.
-
질의 (query) : 사용자가 원하는 문서를 찾거나 집계 결과를 출력하기 위해 검색 시 입력하는 검색어 또는 검색 조건입니다. 이 책에서는 질의 또는 쿼리라고 표현합니다.
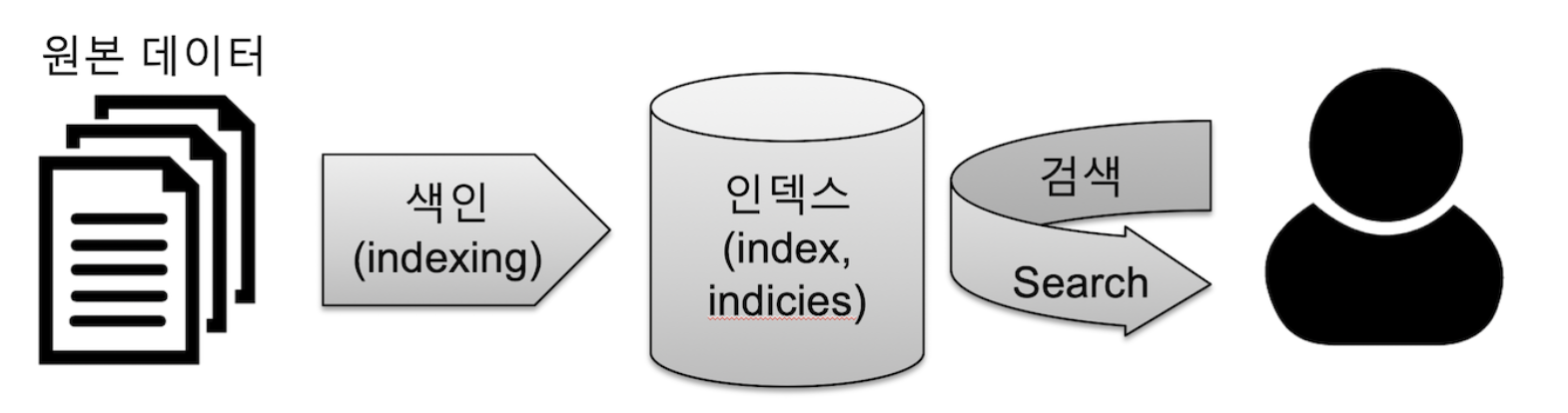
출처 : 엘라스틱 가이드북 [ https://esbook.kimjmin.net/02-install/2.1]
쉽게 이해하면

- 문서에서 키워드를 찾아 보기 쉽도록 정렬 및 나열한 목록이다.
- 책에서 맨 앞에 나와 있는 목차를 떠올리면 된다. (좌측 사진)
- 데이터베이스 관점으로 보자면 '분석모형설계', '분석기법적용' 같은 목차의 제목은 PK와 같은 레코드를 대표하는 값을 의미하고, 몇번 페이지를 나타내는 것은 실제 데이터 레코드가 존재하는 물리적 주소로 이해하면 된다. 레코드에서 대표하는 값을 뽑기 때문에 문서에서 키워드를 뽑는 색인이라고 명명하는 것이다.
따라서,,,indexwriter가 index 파일들을 생성하는 과정
- 수정이 불가능한 immutable type
- 여러가지 생성된 세그먼트 파일들을 merge라는 작업을 통해 하나의 색인 파일로 만드는 과정이 필요
- 하나의 index는 하나의 indexwriter로 구성
역색인이란?

키워드를 통해 문서를 찾아내는 방식이다.
- 책에서 맨 뒤에 나와 있는 찾아 보기를 떠올리면 된다. (위 사진)
- 검색 성능이 매우 빠르다.
- 인덱스를 색인어 기반의 검색을 생성하기 위해 색인어에 대한 통계를 저장하는 구조
- 즉, 용어에 대한 문서를 나열하는 구조가 역인덱스라고 하는 인덱스

검색이란?
IndexWriter 색인 후 IndexSearch로 검색하는 과정
- IndexSrarchsms IndexReader를 이용해서 검색 수행을 하게된다.
- 즉, 하나의 index에는 Segmentquffh N개의 LeafReader가 존재한다.
형태소 분석이란?
입력 받은 문자열에서 검색가능한 정보 구조로 분석 및 분해하는 과정
구성요소
- Analyzer
- Tokenizer
- CharFiler
- TokenFilter
Analyzer는 형태소 분석을 위한 최상위 클래스이며 하나의 tokenizer와 다수의 filter로 구성이된다.

token filter는 정의된 순서에 맞춰 적용되기 때문에 적용 시 순ㅇ서가 중요하다.
루씬에서 제공하고 있는 한글 처리를 위한 Analyzer는 CJK와 Nori Analyzer가 있다.
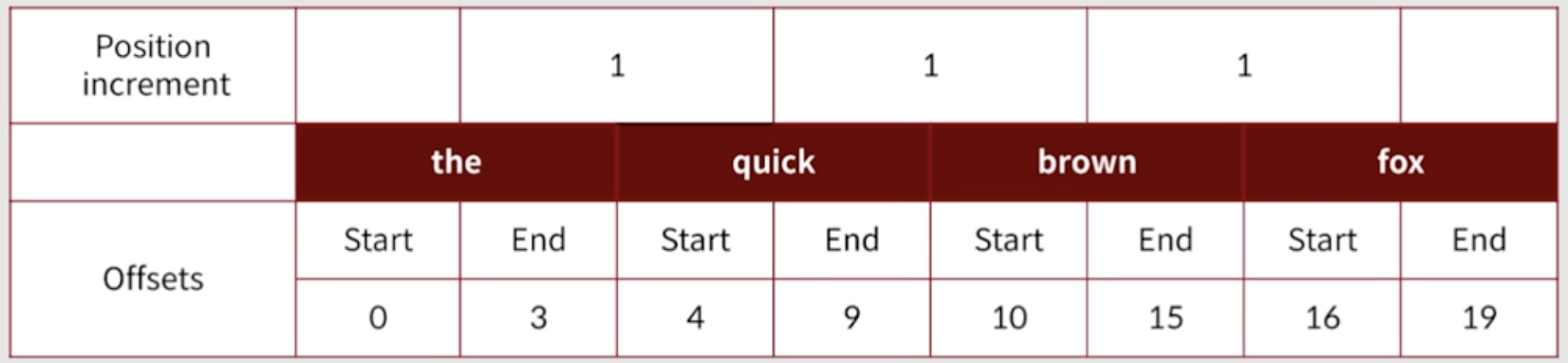
- postion 정보는 0부터 시작해서 1씩 증가하는 구조를 가지며, offset은 token의 start와 End에 대한 정보를 가지고 있다,
- Endoffset이 실제 token의 길이보다 1이 큰 이유는 토큰 추출 시 루씬 내부에서 substring()을 사용하기 때문에 길이보다 1크게 설정된다.
- 추출된 token, postion, offset 정보를 포함ㄴ해서 term이라하고 하고 이를 이용해서 강조와 동의어에 활용한다.
WRAP UP
- 루씬을 이용해서 검색 apppliacation이나 검색엔진을 만들 수 있다.
- 루씬을 이용해서 다양한 text분석 app을 만들수있다.
- 루씬의 index,즉 segemnts파일은 불변
- 루씬의 핵심클래스 3개 IndexWriter, IndexSearcher, Analyzer 꼭 기억하기!!!!!!!
- 소스코드는 꼭 참고( 나중에 보자,, java라 어려움)
