From Local to Global: A GraphRAG Approach to Query-Focused Summarization
읽은 날짜: 2025년 5월 12일 ~ 5월 18일
Abstract
기존 RAG(Retrieval Augement Generation)는 연결된 문서(document)를 기반으로 질문에 답을 할 때 관련 문서를 찾아 답변을 생성한다. 그래서 부분 질문에는 강하지만 전체적인 질문에는 약하다. 이러한 RAG의 한계점을 극복하기 위해 GraphRAG를 소개한다. GraphRAG는 문서 내용을 분석해서 'Entity'들을 연결한 지식 그래프를 만든다. 서로 연관된 Entity들의 집단마다 커뮤니티 요약(community summaries)를 사전에 생성한다. 즉 사용자가 질문을 하면 각 커뮤니티 요약을 기반으로 부분 응답을 생성하고 이 부분 응답들을 하나로 합쳐 최종 답변을 만들어낸다. 이 GraphRAG는 100만 토큰 정도 되는 큰 dataset에서도 잘 작동하고 더 풍부하고 다양한 내용을 담은 답변을 생성한다.
GraphRAG는 복잡하고 큰 문서 집합에 대해 '이 문서들의 핵심은 뭐야?' 같은 큰 그림 질문에 답할 수 있도록 그래프 + 요약 기술을 결합한 질문 응답 시스템이다.
1 Introduction
LLM은 context window를 초과하는 input을 넣을 수 없다. 그래서 RAG를 통해 외부의 방대한 텍스트 corpus에 접근을 하면서 질문과 관련 있는 일부 문서만을 검색해서 답변을 가져온다. 이 검색된 문서도 LLM context window 크기보다는 작아야 한다.
이러한 기존 접근 방식을 vector RAG라고 불리며 질문에 답하기 위해 일부 문서만 참조해도 충분한 경우에는 잘 작동한다. 그러나 vector RAG는 'sensemaking query' 즉 데이터 전체를 종합적으로 이해해야만 답할 수 있는 질문에는 적합하지 않다.
여기서 sensemaking(의미 구성) task란 사람, 장소, 사건 등의 연결 관계를 이해하고 그 흐름을 예측하여 효과적으로 대응하는 것을 요구하는 과제이다. 데이터의 양이 매우 방대할 경우 일반적인 vector RAG 방식으로는 corpus 전체에 대해 sensemaking을 수행하기 어렵다. 이러한 한계를 해결하기 위해 GraphRAG를 제안한다.
GraphRAG를 구성하는 방식이다.
-
LLM을 이용해 지식 그래프를 구축한다.
-
구성된 지식 그래프를 서로 관련 있는 entity들의 커뮤니티로 계층적으로 분할한다.
- 밀접하게 연관된 개체들을 묶어 계층적 커뮤니티 구조를 만든다.
-
각 커뮤니티에 대해 LLM을 사용해 커뮤니티 요약(summary)를 생성한다.
- 상향식(bottom-up)으로 이루어지며 상위 계층의 요약은 하위 계층 요약들을 점차 통합해 구성된다.
- 이를 통해 corpus 전체에 대해 설명과 요약이 가능해진다.
-
Map=Reduce 방식을 사용해 질의에 대한 응답을 생성한다.
- Map 단계에서는 각 커뮤니티 요약을 활용해 부분 응답(partial answers)을 병렬적으로 생성한다.
- Reduce 단계에서는 이 부분 응답들을 결합하여 최종적인 전체 응답(global answeres)을 생성한다.
이러한 GraphRAG를 정답이 명확하지 않은 광범위한 주제나 이슈에 대한 질문을 평가할 수 있도록 LLM-as-a-judge(LLM이 평가자 역할) 기법을 사용한다.
-
첫 번째 LLM이 다양한 '큰 그림 질문'을 만든다.
-
두 가지 시스템인 vector RAG와 GraphRAG가 이 질문에 답한다.
-
LLM(GPT-4)이 두 시스템의 답을 비교하고 평가한다.
GraphRAG는 GitHub에 오픈소스로 공개되었고 LangCahin, LlamaIndex, Neo4J와 같은 오픈소스 라이브러리에도 연동되어 있다.
2 Background
2.1 RAG Approaches and Systems
RAG는 사용자의 질의(query)를 바탕으로 외부 데이터 소스에서 질문과 의미적으로 유사한 문서들만 검색하고 이 정보를 LLM이 답변 생성에 활용하는 시스템이다. 질문과 검색된 문서들은 prompt template에 채워지고 이 템플릿이 LLM에 전달되어 응답이 생성된다. RAG는 데이터 소스 내 문서가 너무 많아 한 번에 LLM에 입력할 수 없을 때 가장 효과적이다.
GraphRAG는 원본 데이터로부터 그래프 인덱스(graph index)를 생성하고 그래프 기반 커뮤니티 탐지(graph-based community detection)을 수행하여 데이터 전체를 주제별로 나누는 방식(thematic partitioning)을 적용함으로써 차별점이 있다.
2.2 Using Knowledge Graphs with LLMs and RAG
자연어 text corpus로부터 지식 그래프를 추출하는 기존 접근 방식은 다음과 같다.
- 규칙 기반(rule-based)
- 통계적 패턴 인식(statistical pattern recognition)
- 클러스터링(clustering)
- 임베딩 기반 방법(embeddings)
GraphRAG는 LLM을 활용하여 지식 그래프를 추출하는 방식이다. 또한 지식 그래프를 인덱스로 활용하는 RAG 방식에 대한 연구도 증가하고 있다.
- 서브그래프(subgraph) 또는 그래프의 구성요소/구조 정보를 직접 프롬프트에 활용
- 사실적 근거(factual grounding)로 사용하여 생성된 응답의 신뢰성을 높임
2.3 Adaptive benchmarking for RAG Evaluation
기존 RAG의 벤치마크는 팩트 중심이라 큰 그림 질문에 약하다. 그래서 이 논문은 LLM이 가상의 사용자 페르소나를 생성해서 RAG 시스템을 사용할 법한 다양한 사용자의 유형의 추론을 통해 사용 사례를 도출한다. 이 사례를 바탕으로 해당 corpus에 특화된 의미 구성 질문(sensemaking queries)을 생성한다.
2.4 RAG evaluation criteria
기존 vector RAG의 평가방식(RAGAS)에 따르면 다음과 같다.
- 문창 유창성(fluency)
- 문맥 관련성(context relevance)
- 정확성/사실성(faithfulness)
- 답변의 관련성(answer relevance)
이러한 평가방식은 RAG에 적합하지만 데이터셋 전체를 이해하는 "큰 그림 질문"에는 한계가 있다.
그래서 정확한 기준 답변이 존재하지 않기 때문에 두 개의 서로 다른 모델(RAG, GraphRAG)이 생성한 답변을 비교하여 상대적인 성능(relative performances)을 LLM(GPT-4)이 평가하도록 한다. 이를 LLM-as-a-judge 방식이라고 한다.
3 Methods
3.1 GraphRAG Workflow
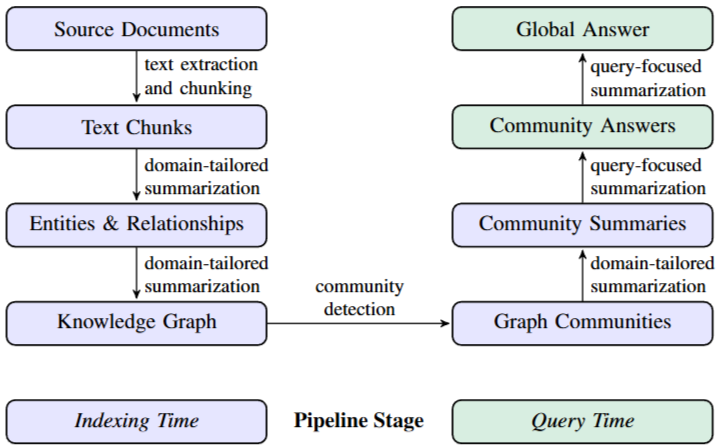
 Figure 1. Graph RAG pipeline using an LLM-derived graph index of source document text
Figure 1. Graph RAG pipeline using an LLM-derived graph index of source document text
Figure 1은 GraphRAG 접근 방식 및 pipeline을 보여준다.
3.1.1 Source Documents → Text Chunks
우선 corpus에 포함된 문서들을 text chunks로 분할한다. 단 chunk size를 어떻게 설정할 것인지는 매우 중요하다.
긴 청크를 사용하면 LLM 호출 횟수가 줄어들어 비용이 감소하지만 정보의 재현률이 떨어질 수 있다는 단점이 있다.
3.1.2 Text Chunks → Entities & Relationships
이 단계에서는 LLM에게 특정 text chunks로부터 Entity와 relation을 추출하도록 지시한다. 또한 LLM은 각 Entity 및 relation에 대한 간단한 설명도 생성한다.
적절한 도메인별 few-shot 예시를 in-context learning 방식으로 prompt를 작성한다. 또한 LLM은 탐지된 Entity들에 대한 주장(claims)을 추출하도록 prompt할 수도 있다. 여기서 주장이란 특정 Entity에 대한 사실적 진술에 대한 것이며 예를 들어 날짜, 사건, 다른 Entity와의 상호작용등을 의미한다.
작성한 entity_exration prompt와 claim_extraction prompt는 GitHub에 공개 되어 있다.
3.1.3 Entities & Relationships → Knowledge Graph
LLM을 활용하여 Entity, relation, claims을 추출하는 과정은 일종의 추상적 요약이다. 특히 relation과 claim은 텍스트에 명시적으로 드러나지 않더라도 개념적으로 의미 있는 요약 정보로 간주된다.
이러한 추출 과정에서 동일한 요소가 여러 문서에서 반복적으로 탐지 되기 때문에 하나의 요소에 대해 여러 인스턴스(instane)가 생성된다. 지식 그래프 추출의 마지막 단계에서는 이러한 인스턴스들이 각각 그래프의 노드(node)와 엣지(edge)로 전환된다. 각 노드와 엣지에는 해당되는 설명들이 집계되고 요약되어 저장된다. 하나의 관계가 여러 번 등장할 경우 이 중복 횟수는 엣지의 가중치(edge weight)로 기록된다.
위 논문에서는 동일 entity를 하나로 통합하는 작업을 위해 문자열 정확 일치(exact string matching)를 사용했다.
3.1.4 Knowledge Graph → Graph Communities
이전 단계에서 생성된 그래프 인덱스(graph index)를 기반으로 서로 강하게 연결된 노드들끼리 커뮤니티로 분할하기 위해 Leiden 커뮤니티 감지 알고리즘을 사용하여 계층적 방식(hierarchical manner)로 적용한다.
하나의 커뮤니티가 감지되면 그 커뮤니 안에서 다시 서브 커뮤니티를 탐지하고 이를 반복하여 더 이상 분활할 수 없는 말단 커뮤니티(leaf community)에 도달할 때까지 재귀적으로 분할한다.
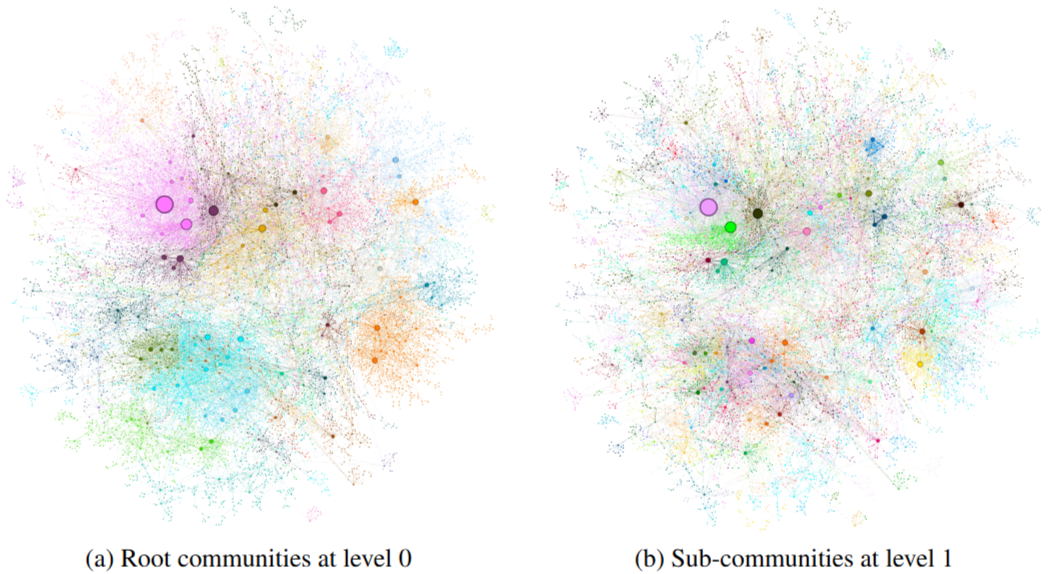 Figure 4. Graph communities detected using the Leiden algorithm over the MultiHop-RAG dataset as indexed. Node colors represent entity communities, shown at two levels of hierarchical clustering : (a) Level 0, corresponding to the hierarchical partition with maximum modularity, and (b) Level 1, which reveals internal structure within these root-level communitie
Figure 4. Graph communities detected using the Leiden algorithm over the MultiHop-RAG dataset as indexed. Node colors represent entity communities, shown at two levels of hierarchical clustering : (a) Level 0, corresponding to the hierarchical partition with maximum modularity, and (b) Level 1, which reveals internal structure within these root-level communitie
Figure 4는 GraphRAG 커뮤니티의 예시이다. 색깔들이 커뮤니티를 뜻하며 level이 클 수록 더 세분화된 커뮤니티를 생성한다. 노드의 중요성에 따라 크기가 커진다.
3.1.5 Graph Communities → Community Summaries
이번 단계에서는 커뮤니티 계층 구조에 포함된 각 커뮤니티에 대해 보고서 형식의 요약(summary)을 생성한다. 이 방식을 통해 매우 큰 규모의 dataset의 전체 구조나 의미를 이해할 수 있다.
GraphRAG의 커뮤니티 요약은 다음 방식과 같다. 각 커뮤니티 요약은 해당 커뮤니티에 포함된 노드,엣지, 관련 주장(claims)에 대한 요약들을 커뮤니티 요약 템플릿(community summary template)에 채워 넣는 방식으로 구성한다. 하위 커뮤니티 요약들은 상위 커뮤니티의 요약을 생성하는 데 활용되며 상향식(bottom-up)으로 계층적 요약이 완성된다.
계층 구조에 따른 커뮤니티 구분 방법은 다음과 같다.
- leaf-level 커뮤니티(말단 커뮤니티)
- 각 커뮤니티의 구성 요소(노드,엣지,주장)에 대한 요약(element summaries)들을 우선순위에 따라 정렬 후 LLM의 토큰 한도 내에서 이 요약들을 하나씩 차례로 넣어 요약 문장을 생성한다.
- 우선순위 기준은 하나의 노드에 더 많은 엣지나 다른 노드들이 연결되어 있는 기준으로 중요도를 산정한다.
- 포함되는 정보는 출발 노드, 대상 노드, 엣지 자체의 설명, 해당 관계에 관련된 claim이 포함된다.
- higher-level 커뮤니티(상위 커뮤니티)
- 모든 요소 요약(element summaries)이 LLM의 context window 들어가면 leaf-level과 동일하게 전체 요약 수행을 한다.
- 토큰 수가 너무 많아서 다 못 넣는다면 각 하위 커뮤니티(sub-community)를 요약의 토큰 수 기준으로 정렬한다. 요약이 긴 요소들은 더 짧은 하위 커뮤니티 요약(sub-summary)로 대체함으로써 이 과정을 반복하여 전체 요약이 LLM의 토큰 한도 안에 들어가도록 조절한다.
3.1.6 Community Summaries → Community Answers → Global Answer
사용자의 질의(query)가 주어지면 커뮤니티 요약(community summaries)을 활용해 여러 단계를 거쳐 최종 응답(global answer)을 생성하게 된다.
전체적인 요약을 해주는 답을 해주는 과정은 다음과 같다.
-
커뮤니티 요약 준비(prepare community summaries)
: 커뮤니티 요약들을 random sampling 후 미리 정의된 토큰 크기 단위로 chunk로 나눈다. 관련 정보가 한 context window에 집중되어 손실되는 것을 방지하고 여러 chunk에 고르게 분산되도록 한다. -
커뮤니티 응답 생성(map community answers)
: 중간 응답(intermediate answers)을 병렬적으로 생성한다. 이 때 LLM은 응답이 질의에 얼마나 도움이 되는지를 0~100점 사이의 점수를 부여하며 0점 응답은 필터링되어 제거 된다. -
전역 응답 생성(Reduce to global answer)
: 중간 커뮤니티 응답들을 도움 점수(helfulness score)기준으로 내림차순 정렬한 뒤 토큰 제한에 도달할 때까지 점수가 높은 응답부터 새로운 context window에 하나씩 추가하며 최종 context를 사용하여 전역 응답을 생성한다.
3.2 Global Sensemaking Question Generation
GraphRAG의 효과성을 평가하기 위해 LLM을 사용하여 특정 corpus에 맞춘 평가하는 질문 세트를 생성한다. 이러한 질문들은 개별 사실을 검색할 필요 없이 전체에 대한 개괄적인 이해 능력을 평가하는데 목적이 있다.
LLM에는 다음과 같은 순서로 prompt가 주어진다.
1. corpus의 전체적인 설명과 목적이 주어지면 LLM은 이 GraphRAG 시스템의 가상의 사용자 페르소나들을 생성한다.
2. 각 사용자에 대해 LLM은 그 사용자가 GraphRAG 시스템을 통해 수행할 법한 task를 정의한다.
3. 사용자의 task 조합마다 해당 사용자가 그 task를 수행하기 위해 corpus 전체를 이해해야만 풀 수 있는 질문들을 생성하도록 LLM에 prompt를 제공한다.
 Algorithm 1. Prompting Procedure for Question Generation
Algorithm 1. Prompting Procedure for Question Generation
이 논문에서는 K = M = N = 5로 실험을 진행해 총 125개의 test questioins per dataset이 생겼다.
 Table 1. Examples of potential users, tasks, and questions generated by the LLM based on short descriptions of the target datasets. Questions target global understanding rather than specific details
Table 1. Examples of potential users, tasks, and questions generated by the LLM based on short descriptions of the target datasets. Questions target global understanding rather than specific details
Table 1은 질문의 예시이다.
3.3 Criteria for Evaluating Global Sensemaking
두 RAG의 주요 평가 기준(target criteria)은 총 4가지가 있다. 이 평가는 LLM 평가자를 통해 계산되는 평가 방식이며 prompt를 사용해서 진행한다.
- 포괄성(comprehensiveness) : 답변이 질문의 모든 측면과 세부사항을 얼마나 잘 다루고 있는가
- 다양성(diversity) : 답변이 다양한 관점과 통찰력을 얼마나 풍부하게 제공하는가
- 이해력 및 판단 지원도(empowerment) : 독자가 주제를 더 잘 이해하고 스스로 판단할 수 있도록 얼마나 잘 도와주는가
- 직접성(Directness) : 답변이 핵심을 명확하게, 간결하게 전달했는가
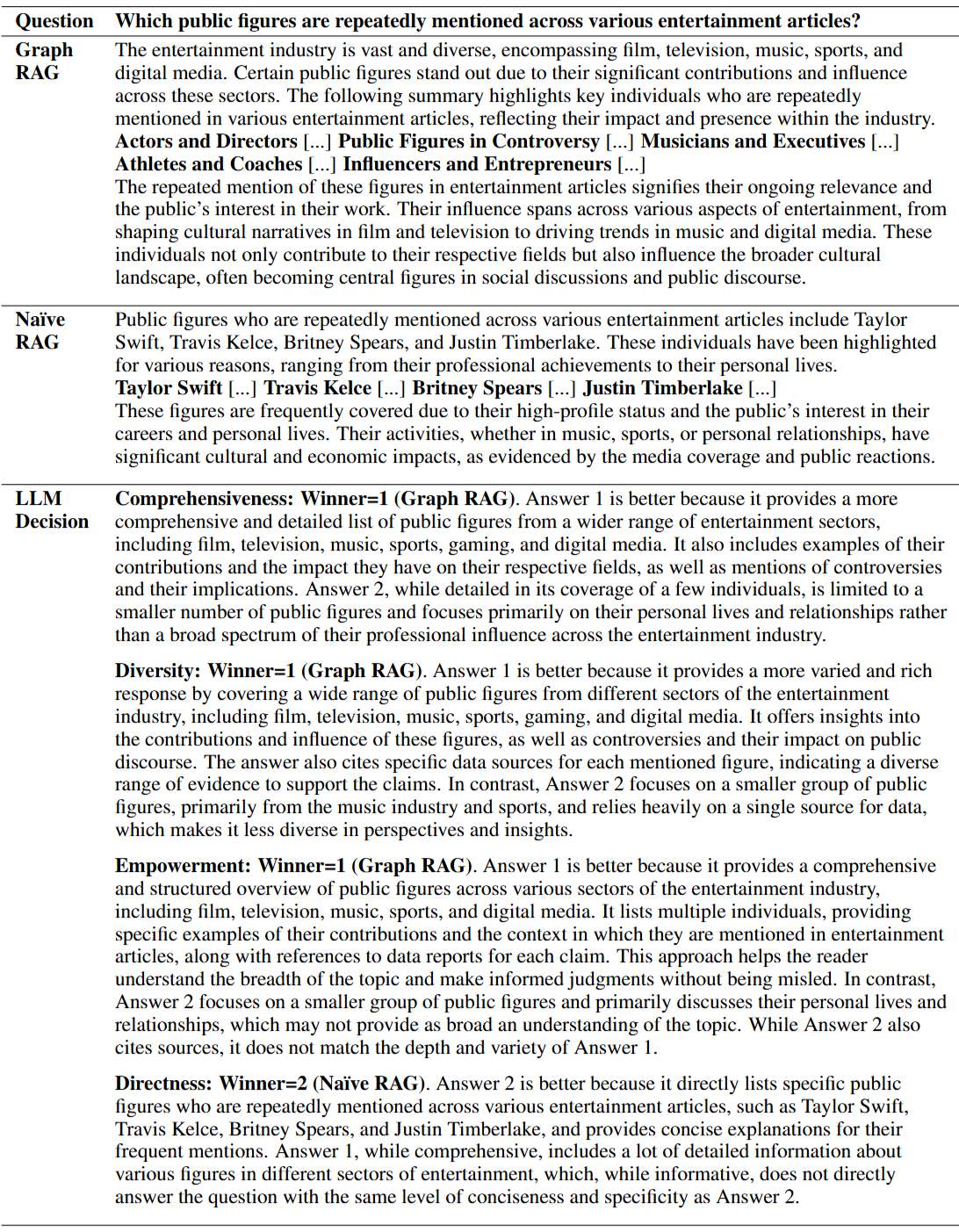 Table 5. Example question, answers, and LLM-generated assessments for the News article dataset
Table 5. Example question, answers, and LLM-generated assessments for the News article dataset
LLM을 통해 평가 결과를 보면 포괄성, 다양성, 이해력 및 판단 지원도는 GraphRAG가 우세하지만 직접성은 RAG가 더 우세함을 나타낸다.
4 Analysis
4.1 Experiment 1
4.1.1 Datasets
위 논문에서는 100만 토큰 규모의 두 개의 dataset을 선정했다.
- 팟캐스트 전사(Podcast transcripts)
- 뉴스 기사(News article)
4.1.2 Conditions
총 6가지 조건을 비교하였다.
| 조건 | 내용 요약 |
|---|---|
| C0~C3 | 그래프 커뮤니티 요약을 사용하는 GraphRAG (상위 → 하위 수준으로 갈수록 세분화됨) |
| TS | 원본 텍스트를 그대로 사용해 map-reduce 방식 적용 |
| SS | 기존 벡터 RAG 방식으로 의미 유사한 텍스트 청크 검색 후 요약 |
응답 생성을 위한 prompt와 context window 크기는 동일하게 설정했다.
4.1.3 Configuration
| 항목 | 설정 |
|---|---|
| 컨텍스트 크기 | 8,000 tokens (요약 및 응답 생성용) |
| 인덱싱 윈도우 | 600-token 단위 (중복 포함) |
| 인덱싱 소요 시간 | Podcast 데이터셋 기준 281분 |
| 사용 환경 | 16GB RAM, Xeon CPU, GPT-4 Turbo API (2M TPM, 10k RPM) |
| 그래프 감지 | graspologic 라이브러리의 Leiden 알고리즘 |
| 프롬프트 정보 | Appendix E (생성용), Appendix F (평가용) |
| 통계 분석 | Appendix G 참고 |
4.2 Experiment 2
실험 1에서 도출된 포괄성 및 다양성 결과를 검증했다.
포괄성을 평가하기 위해 Claimify LLM tool을 사용해 주장(claim)-기반 측정 방식을 측정한다.
다양성을 평가하기 위해 클러스터링을 통해 측정한다.
5 Results
5.1 Experiment 1
그래프 인덱스 결과
1. Podcast 데이터셋 : 총 8,564개의 노드와 20,691개의 엣지(관계) 를 갖는 그래프 생성
- News 데이터셋 : 15,754개의 노드와 19,520개의 엣지 생성됨
 Table 2. Number of context units (community summaries for C0-C3 and text chunks for TS), corre-sponding token counts, and percentage of the maximum token count. Map-reduce summarization of source texts is the most resource-intensive approach requiring the highest number of context tokens. Root-level community summaries (C0) require dramatically fewer tokens per query (9x-43x).
Table 2. Number of context units (community summaries for C0-C3 and text chunks for TS), corre-sponding token counts, and percentage of the maximum token count. Map-reduce summarization of source texts is the most resource-intensive approach requiring the highest number of context tokens. Root-level community summaries (C0) require dramatically fewer tokens per query (9x-43x).
Table 2는 level에 따른 각 커뮤니티 요약들의 숫자다.
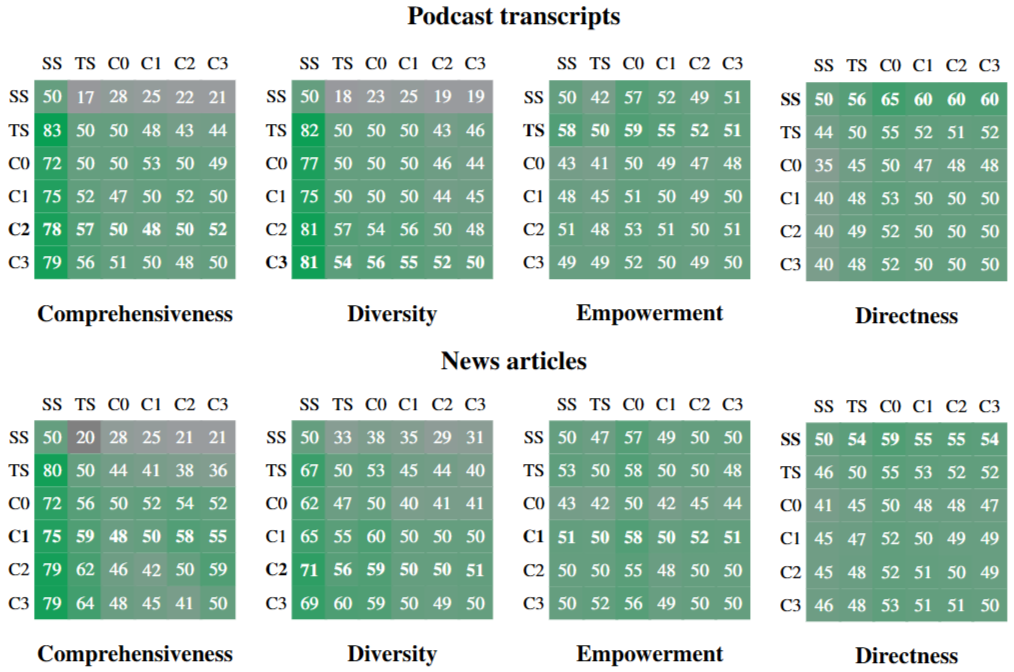 Figure 2. Head-to-head win rate percentages of (row condition) over (column condition) across two datasets, four metrics, and 125 questions per comparison (each repeated five times and averaged)
Figure 2. Head-to-head win rate percentages of (row condition) over (column condition) across two datasets, four metrics, and 125 questions per comparison (each repeated five times and averaged)
Figure 2는 GraphRAG와 vector RAG(ss)를 평가한 결과이다. 대부분의 평가 지표에서 GraphRAG가 vector RAG 보다 성능이 앞서지만 Directness 지표에서는 vector RAG가 강점을 보인다.
커뮤니티 요약와 원문 텍스트 요약도 비교했다.
| 항목 | 설명 |
|---|---|
| 중간/하위 커뮤니티 요약** | 원문보다 포괄성과 다양성에서 더 좋음 |
| 루트 수준 요약(C0) | 성능은 살짝 낮지만, 압도적으로 효율적(토큰 97% 절감) |
| GraphRAG 전반 | 벡터 RAG보다 전반적으로 더 풍부하고 다양한 응답 생성 가능 |
5.2 Experiment 2
실험 1의 LLM 평가가 객관적인 Claim 기반 측정 결과와 꽤 잘 일치했으며 GraphRAG 계열(C0~C3) 과 TS가 기존 vector RAG보다 더 풍부하고 다양한 응답을 만든다는 것이 확인되었다.
6 Discussion
6.1 Limitations of evaluation approach
다양한 도메인과 사용 사례에서의 성능이 일반화되는지 추가 연구가 필요하다. 또한 LLM으로 생성된 응답의 허위 사실 생성률을 비교하는 것도 필요하다.
7 Conclusion
GraphRAG은 전역적인 질문 응답을 위한 더 강력하고 효율적인 RAG 방식으로 적은 토큰으로 더 깊이 있는 응답을 생성할 수 있다.
