Bag of Tricks for Image Classification with Convolutional Neural Network
읽은 날짜: 2025년 5월 5일 ~ 5월 11일
Abstract
최근 논문들은 image classification에서 성능을 높이기 위해 대부분 데이터 증강 혹은 최적화 방법을 통해 훈련 절차 개선 위주의 방법론들이 설명된다. 그러나 문헌의 대부분의 개선 사항은 간단한히 언급만 되고 있다. 그래서 이 논문에서는 개선 사항 모음을 살펴보고 ablation study를 통해 정확도에 미치는 영향을 평가하고 실험해보려고 한다.
1. Introduction
2012년에 CNN기반의 이미지 분류 모델인 AlexNet를 도입된 이후 다양한 VGG, NiN, Inception, ResNet, DenseNet, NASNet을 포함한 다양한 아키텍처가 제안되면서 모델 정확도도 꾸준하게 향상되었다.
그러나 이러한 모델 정확도 향상은 새로운 아키텍처 제안으로만 향상된 것이 아니라 손실 함수, 데이터 전처리 및 최적화 방법의 변경을 포함한 훈련 절차 개선도 중요한 역할을 했다.
그래서 이 논문에서는 모델 정확도를 향상시키지만 계산 복잡성을 거의 변경하지 않는 훈련 절차 및 모델 아키텍처 개선 사항 모음을 살펴본다. 이러한 개선 사항에서의 대부분은 convolutional layer의 stride size를 수정하거나 학습률을 조정하는 사소한 tricks이다. 그러나 이것은 큰 차이를 만들어 낸다.
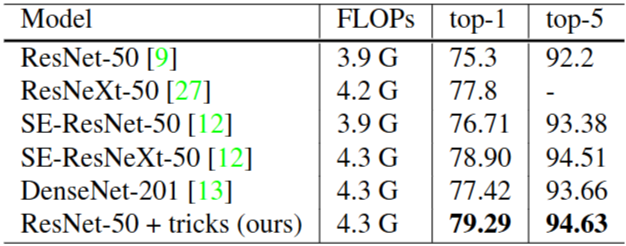 Table 1. 모델 향상 비법
Table 1. 모델 향상 비법
Table 1을 보면 논문에서 소개하는 tricks을 이용하면 정확도 향상으로 이어지고 이를 결합하면 모델 정확도가 더 올라가는 것을 입증하고 있다.
2. Training Procedures
 Algorithm 1. Train a neural network with mini-bath stochastic gradient descent
Algorithm 1. Train a neural network with mini-bath stochastic gradient descent
mini-bath stochastic gradient descent를 사용한 신경망 학습 템플릿은 Algorithm 1에 나와 있다. 각 반복에서 기울기를 계산하기 위해 b개의 이미지를 임의로 샘플링한 다음 네트워크 parameter를 업데이트한다. 데이터 세트를 K번 통과한 후 중지된다. Algorithm 1의 모든 함수와 hyper-parameter는 여러 가지 방법으로 구현할 수 있다.
2.1 Baseline Training Procedure
위 논문은 널리 사용되는 ResNet의 pipeline을 기준으로 한다.
이미지 학습 준비 과정 (전처리)
- 이미지 샘플링 및 디코딩
- 임의의 이미지를 선택해서 불러옴
- 이미지를 32-bit float로 디코딩한다. 픽셀값은 [0,225] 범위다.,
- 랜덤 크롭(Crop) 및 리사이즈
- 이미지를 가로세로 비율을 [3/4, 4/3] 범위에서 랜덤 선택
- 전체 이미지 중 일정 면적인 8%~10%를 랜덤하게 선택해서 자름
- 이후 잘라낸 부분을 224-by-224 크기의 정사각형으로 resize
- 수평 반전
- 50% 확률로 수평으로 뒤집기
- 색상 변환
- 색조, 채도 및 밝기를 [0.6, 1.4]에서 균일하게 가져온 계수로 조정
- PCA 노이즈 추가
- PCA를 기반으로 한 노이즈를 이미지에 추가
- 노이즈의 계수는 정규분포 N(0,0.1)에서 샘플링
- 정규화(Normalization)
- 각 RGB 채널마다 다음 값을 빼고 지정된 표준 편차로 나눔
- R: (x - 123.68) / 58.393
- G: (x - 116.779) / 57.12
- B: (x - 103.939) / 57.375
- 각 RGB 채널마다 다음 값을 빼고 지정된 표준 편차로 나눔
검증하는 과정
검증하는 과정에는 학습과 달리 랜덤한 변화는 하지 않고 고정된 방식으로 처리한다.
1. 256 픽셀을 맞추면서 비율 유지
2. 가운데 224-by-224 정사각형 부분을 잘름 (center crop)
3. RGB 정규화는 동일하게 수행
모델 초기 설정
파라미터 초기화 방법
1. Convolutional / Fully-connected Layer
- Xavier 초기화 방식 사용:
- [-a, a] 범위에서 무작위로 값 선택
- a = √6 / (din + dout) -> din: 입력 채널 수, dout: 출력 채널 수
- 바이어스(Bias)는 모두 0으로 초기화
2. Batch Normalization Layer
- γ (스케일 계수)는 1, β (편향 계수)는 0으로 초기화
학습 방법
모델 학습 방법
- 총 120번 학습(epoch)
- 총 배치 크기 : 256장
- 8개의 고성능 GPU 사용
학습률
- 처음에는 0.1로 시작
- 30번째, 60번째, 90번째 학습 끝나면 10배씩 줄임 : 0.1 → 0.01 → 0.001 → 0.0001
옵티마이저 : NAG
- 일종의 빠르게 움직이는 경사 하강법(SGD)의 업그레이드 버전
- 더 부드럽고 예측력 있는 학습 방식
즉 ResNet 학습 설정 요약
| 항목 | 내용 |
|---|---|
| 이미지 크기 | 224x224 |
| 학습용 이미지 | 잘라내고, 뒤집고, 색 바꾸고, 노이즈 넣고, 정규화 |
| 검증용 이미지 | 사이즈 고정하고 정중앙만 자르고 정규화만 함 |
| 초기값 | 가중치 랜덤, 바이어스 0, 정규화 계수: 1과 0 |
| 학습 방식 | 총 120번, 처음엔 빠르게 배우고 점점 천천히 |
| 사용 기기 | GPU 8개 |
| 옵티마이저 | NAG 방식 (똑똑한 경사하강법) |
2.2 Experiment Results
세 가지 CNN, 즉 ResNet-50, InceptionV3 및 MobileNet을 평가한다.
학습용 이미지 130만 개와 1000개의 클래스가 있는 ISLVRC2012 데이터 세트를 사용한다.
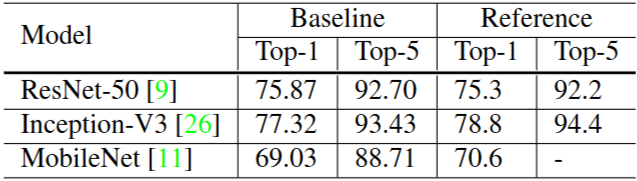 Table 2. Validation accuracy of reference implementa-tions and our baseline.
Table 2. Validation accuracy of reference implementa-tions and our baseline.
검증 정확도는 Table 2와 같다.
3. Efficient Training
GPU는 최근 몇 년 동안 빠르게 발전함에 따라 성능 관련 절충에 대한 최적의 선택들이 변경되어 왔다. 그래서 이번 섹션에서는 모델 정확도를 희생하지 않고도 낮은 정밀도와 큰 배치 학습을 가능하게 하는 다양한 기술을 살펴본다.
3.1. Large-batch training
Mini-batch SGD는 여러 개 샘플을 한 덩어리로 묶어서 한 번에 학습하다 보니 연산 속도와 병렬 처리에는 좋지만 정확도는 떨어질 수 있다. 그래서 큰 배치 사이즈를 쓸수록 검증 정확도가 떨어지는 경향이 있다. 그래서 이 문제를 해결하기 위해 4개의 heuristics을 제안한다.
Linear scaling learning rate(선형 스케일링 법칙)
큰 배치 사이즈를 사용할 때 학습률을 더 크게 설정해야 한다.
배치가 크면 gradient가 정확해져서 더 빠르게 이동해도 괜찮기 때문에 배치 크기에 비례해서 학습률을 선형으로 늘린다.
공식은 새 학습률 = 기존 학습률 × (새 배치 크기 ÷ 기준 배치 크기)
Learning rate warmup
학습 초기에 너무 큰 학습률을 쓰면 모델이 불안정해질 수 있기 때문에 초반에는 작은 학습률 부터 시작해서 점점 키우는 방식이다.
공식은 iη/m (i: 현재 배치 순서, m: 전체 워밍업 배치 수, η: 목표 학습률)
Zero γ
ResNet이 처음부터 너무 깊으면 학습이 어려워질 수 있다. 그래서 처음엔 '잔차 블록'이 아무 일도 안 하는 것처럼 보이게 만든다.
결과적으로 모델이 초기에는 얕은 네트워크처럼 동작해 안정적으로 학습 시작할 수 있다.
No bias decay
이 기법은 학습에서 자주 사용되는 L2 정규화(weight decay)를 조금 더 똑똑하게 적용하는 방법으로 가중치에만 decay 적용하고 bias, BN 계수(γ, β)에는 적용하지 않는다.
결과적으로 모델이 더 잘 일반화되고, 과도한 규제가 줄어든다.
3.2. Low-precision training
정밀도(precision)를 FP32에서 FP16으로 줄이면 속도는 빠르지만 FP16으로 표현할 수 있는 숫자 범위가 작아서 불안정할 수 있다. 그래서 혼합 정밀도 학습(Mixed Precision Training)을 사용한다. 혼합 정밀도 학습은 연산은 FP16으로 하고 파라미터 업데이트는 FP32으로 수행하는 방법이다.
3.3 Experiment Results
 Table 3. Comparison of the training time and validation accuracy for ResNet-50 between the baseline (BS=256 with FP32) and a more hardware efficient setting (BS=1024 with FP16.
Table 3. Comparison of the training time and validation accuracy for ResNet-50 between the baseline (BS=256 with FP32) and a more hardware efficient setting (BS=1024 with FP16.
위에서 말한 모든 기법들(heuristics)을 실제로 적용했을 때 얼마나 효과가 있었는지를 실험 결과표이다.
4. Model Tweaks
Model Tweaks은 특정 convolutional layer의 stride를 변경하는 것과 같은 아키텍처에 대한 사소한 조정이다. 이 논문에서는 ResNet을 예로 들어 model tweaks의 효과를 살펴본다.
4.1 ResNet Architecture
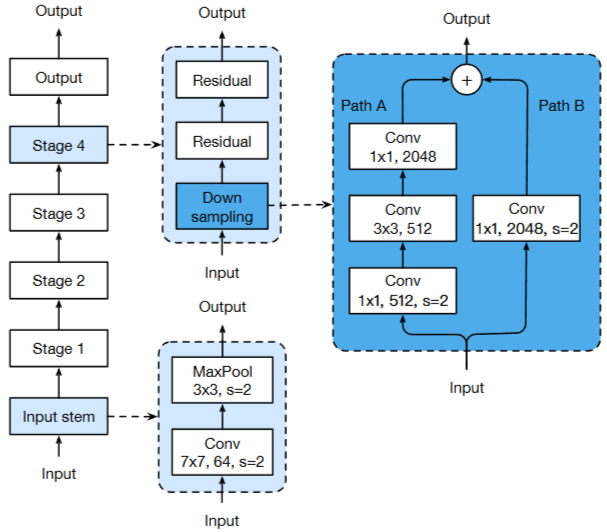
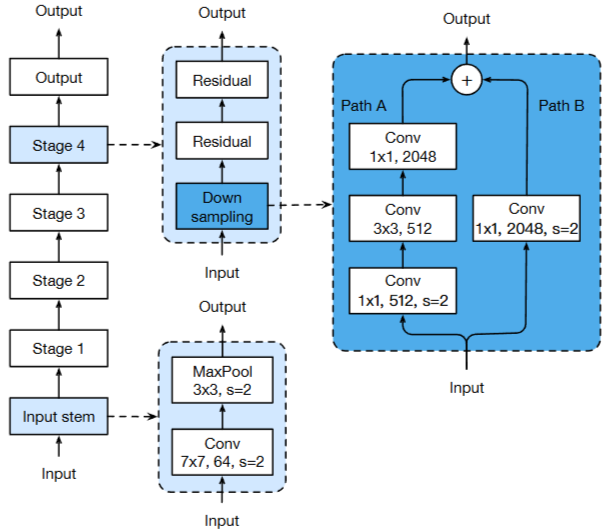 Figure 1. The architecture of ResNet-50. The convolution kernel size, output channel size and stride size (default is 1) are illustrated, similar for pooling layers
Figure 1. The architecture of ResNet-50. The convolution kernel size, output channel size and stride size (default is 1) are illustrated, similar for pooling layers
ResNet 아키텍처를 간단하게 설명하면 ResNet의 아키텍처는 입력 stem, 4개의 후속 stage 및 최종 출력 layer로 구성된다.
자세하게 살펴보면
- Input Stem : 처음 입력을 처리하는 부분 (7×7 conv + 3×3 maxpool)
- Stage 1~4 : 여러 개의 downsampling block + residual block으로 구성
- Downsampling Block : 크기를 줄이면서 채널 수 늘리는 블록 (stride=2)
- Residual Block : 특성을 학습하는 핵심 블록 (stride=1)
- ResNet-50 / 152 차이 : stage마다 residual block의 개수 차이
4.2. ResNet Tweaks
ResNet-B 및 ResNet-C라고 하는 두 가지 인기 있는 ResNet tweak을 살펴본다.
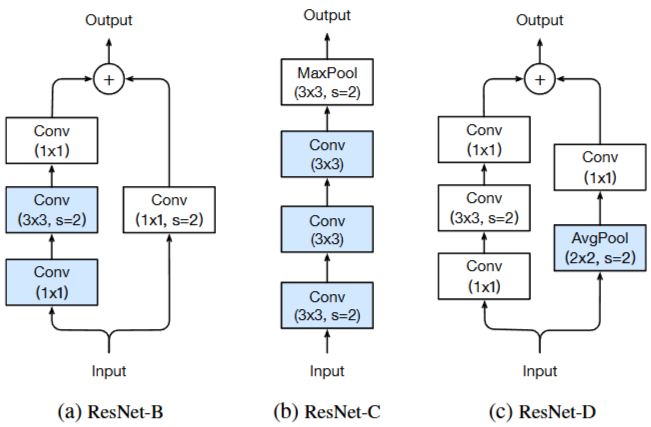 Figure 2. Three ResNet tweaks. ResNet-B modifies the downsampling block of Resnet. ResNet-C further modifies the input stem. On top of that, ResNet-D again modifies the downsampling block.
Figure 2. Three ResNet tweaks. ResNet-B modifies the downsampling block of Resnet. ResNet-C further modifies the input stem. On top of that, ResNet-D again modifies the downsampling block.
ResNet-B
기존 ResNet Path A에서 stride의 위치를 변경한 모델이다.
기존 방식은 입력 특성의 75%를 무시하기 때문에 정보 손실을 줄이면서도 출력 크기는 그대로 유지한다.
ResNet-C
기존 ResNet에서 입력 stem 단계에서 7x7 convolution을 사용(stride=2)을 했는데 3x3 convolution으로 변경한다.
기존 방식에서 연산량은 낮아지고 성능은 유지되거나 향상된다.
ResNet-D
기존 ResNet Path B의 1×1 convolution (stride=2)을 stride 1로 바꾸고 앞에 2×2 average pooling을(stride=2) 추가힌다.
기존 방식에서 입력 정보를 더 많이 보존하면서도 출력 크기는 동일하게 유지한다.
4.3. Experiment Results
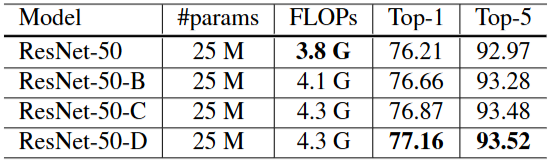 Table 5: Compare ResNet-50 with three model tweaks on model size, FLOPs and ImageNet validation accuracy
Table 5: Compare ResNet-50 with three model tweaks on model size, FLOPs and ImageNet validation accuracy
기존 ResNet과 위에서 소개한 ResNet Tweaks 기법들을 실험한 결과다
| 모델 버전 | 추가된 트윅 | 성능 향상 (vs ResNet-50) |
|---|---|---|
| ResNet-B | Path A에서 stride 위치 변경 | +0.5% |
| ResNet-C | 입력 stem 7×7 → 3×3×3 | +0.2% |
| ResNet-D | Path B에도 stride 개선 | +0.3% |
| 총합 | 모든 트윅 적용 (B+C+D) | +1.0% 향상 |
5. Training Refinements
모델 정확도를 향상시키기 위한 네 가지 training refinements에 대해 소개한다.
5.1. Cosine Learning Rate Decay
학습률 조절(learning rate scheduling)의 중요성과 2개의 스케줄링 방법을 비교한다.
학습률이 너무 크거나 작으면 학습이 잘 안되기 때문에 학습 중에 학습률을 점점 줄이는 전략이 필요하다. 대표적인 방법으로는 Step Decay와 Cosine Decay가 있다.
- Step Decay : 일정 에폭마다 학습률을 뚝뚝 줄이는 방식
- Cosine Decay : 학습률을 코사인 곡선처럼 천천히 줄이는 방식
결론적으로 Cosine Decay이 부드럽게 감소하며 성능 향상에 도움을 준다.
5.2. Label Smoothing
Label Smoothing이라는 기법이 이미지 분류 모델(특히 ResNet-50-D)의 출력 분포와 일반화 성능에 어떤 영향을 주는지를 설명한다.
Cross Entropy Loss는 모델이 확신(confident)하게 정답만 맞히는 걸 유도하므로 과적합(overfitting) 위험 있다. 그래서 Label Smoothing을 통해 정답의 확률을 1에서 조금 낮추고, 나머지 클래스에도 작은 확률을 부여하는 방식이다.
결론적으로 출력값이 너무 극단적으로 커지지 않고 일반화 성능이 향상된다.
5.3. Knowledge Distillation
Knowledge Distillation (지식 증류) 기법에 대해 설명한다.
작은 모델(student)이 큰 모델(teacher)의 예측을 모방하면 성능이 향상 되므로 정답 CrossEntropy + soft-label CrossEntropy 병행 학습을 한다.
결론적으로 student 모델의 정확도 향상(모델 크기는 유지)이 된다.
5.4. Mixup Training
Mixup은 이미지 두 장과 라벨을 섞어서 새로운 학습 데이터를 만드는 방법으로 모델이 더 일반화되고 노이즈에 강한 성능을 갖게 해주는 중요한 기법이다.
5.5. Experiment Results
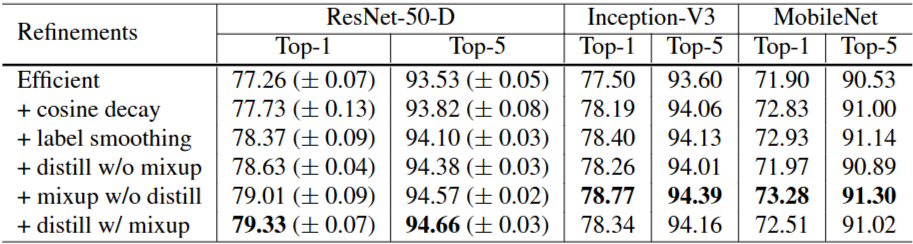 Table 6. The validation accuracies on ImageNet for stacking training refinements one by one. The baseline models are btained from Section 3. We repeat each refinement on ResNet-50-D for 4 times with different initialization, and report the mean and standard deviation in the table
Table 6. The validation accuracies on ImageNet for stacking training refinements one by one. The baseline models are btained from Section 3. We repeat each refinement on ResNet-50-D for 4 times with different initialization, and report the mean and standard deviation in the table
위에서 소개한 training refinements를 하나씩 적용했을 때의 validation 정확도를 표 6에 정리했다.
 Table 7.Results on both the validation set and the test set of MIT Places 365 dataset. Prediction are generated as stated in Section 2.1. ResNet-50-D Efficient refers to ResNet-50-D trained with settings from Section 3, and ResNet-50-D Best further incorporate cosine scheduling, label smoothing and mixup.
Table 7.Results on both the validation set and the test set of MIT Places 365 dataset. Prediction are generated as stated in Section 2.1. ResNet-50-D Efficient refers to ResNet-50-D trained with settings from Section 3, and ResNet-50-D Best further incorporate cosine scheduling, label smoothing and mixup.
Refinements가 validation 및 test set 모두에서 top-5 정확도를 지속적으로 향상시는 것을 표 7에서 볼 수 있다.
6. Transfer Learning
Transfer learning은 훈련된 image classification 모델의 주요 down-streaming task 중 하나이다. 이 섹션에서는 지금까지 논의된 이러한 개선 사항이 transfer learning에 도움이 될 수 있는지 살펴보고 특히 object detection과 semantic segmentation이라는 두 가지 중요한 computer vision 작업을 선택하고 base 모델을 다양하게 하여 성능을 평가한다.
6.1 Object Detection
이미지 분류 모델의 성능 향상이 객체 탐지(object detection) 모델 성능에도 도움이 되는지를 평가한다.
Faster R-CNN에 다양한 pretrained 모델을 backbone으로 사용하고 성능 비교하면 분류 모델 품질을 높이면 객체 탐지 모델도 성능 향상 가능하다.
6.2. Semantic Segmentation
기존 학습 개선 기법들(코사인 decay, label smoothing, mixup 등)이 세그멘테이션에도 효과가 있는지 확인한다.
FCN (Fully Convolutional Network) 모델을 사용하고 ADE20K (대규모 세그멘테이션 벤치마크) 데이터셋을 사용한다.
- 다양한 pretrained 백본 교체
- stage-3, 4에 dilated convolution 적용
- PSPNet/HRNet 방식의 하이퍼파라미터 설정 따름
결론적으로 세그멘테이션은 픽셀 단위의 정밀한 예측이 필요해서 soft한 label은 정보 손실 유발하기 때문에 Label Smoothing, Distillation, Mixup 기법들을 비추천한다.
7. Conclusion
이 논문은 딥러닝 기반 이미지 분류 모델의 성능을 향상시키기 위한 12가지 학습 트릭을 체계적으로 정리하고 다양한 실험을 통해 그 효과를 검증한다. 제안된 트릭들은 모델 구조, 데이터 전처리, 손실 함수, 학습률 스케줄링 등에 걸쳐 있으며 대표적으로 ResNet-B/C/D 구조 변경, label smoothing, knowledge distillation, mixup, cosine learning rate decay 등이 포함된다.
실험은 ResNet-50, Inception-V3, MobileNet 모델을 대상으로 ImageNet 데이터셋에서 진행되었으며 각 기법을 단독으로 적용했을 때와 조합했을 때 모두 모델의 정확도가 향상되었음을 확인하였다. 특히 모든 기법을 조합하면 단일 모델 대비 상당한 성능 향상을 얻을 수 있었다.
또한 이 향상된 분류 모델들이 전이 학습에서도 강력한 성능을 보이는지 검증하기 위해 객체 탐지(Faster R-CNN, VOC)와 의미론적 분할(FCN, ADE20K) 실험도 진행되었다. 그 결과 객체 탐지에서는 분류 정확도가 높은 모델일수록 mAP가 증가하는 일관된 경향을 보였으며 의미론적 분할에서는 cosine decay만 효과적이고 나머지 트릭들은 오히려 픽셀 수준 예측에 부정적인 영향을 줄 수 있음을 보였다.
결론적으로 이 논문은 훈련 기법의 작은 변화만으로도 다양한 딥러닝 모델의 성능을 향상시킬 수 있으며 특히 분류 기반의 전이 학습 문제에서 이러한 트릭들이 널리 활용될 수 있음을 실증적으로 보여준다.
