Learning Transferable Visual Models From Natural Language Supervision
읽은 날짜: 2025년 3월 3일 ~ 3월 9일
Abstract
컴퓨터 비전 분야에서는 이미지를 보고 "이것은 개다", "이것은 고양이다"와 같이 미리 정해진 범주 내에서만 대상을 분류할 수 있었다. 이를 지도 학습(supervised learning)이라고 한다. 그러나 이러한 방식은 한계가 있다. 새로운 범주를 인식하려면 기존에 있던 모델을 추가적으로 학습 시키고 새로운 데이터 라벨을 붙여야 하기 때문이다.
이러한 문제를 해결하기 위해 OpenAI가 CLIP이라는 방법을 제안했다.
CLIP은 이미지에 대한 raw text를 직접 학습하는 방법이 제안되며, 인터넷에서 수집한 4억 개의 (이미지, 텍스트 설명) 쌍으로 학습되었다. 예를 들어:
- 강아지 사진 + "이 강아지는 길을 건너고 있다"
- 고양이 사진 + "검은 고양이가 사다리에서 내려오고 있다"
이렇게 학습된 모델은 단순히 범주만을 인식하는 것이 아니라 새로운 사진에 대한 개념을 자연어를 통해 이해하고 추론할 수 있게 된다.
이렇듯 CLIP은 기존에 학습된 개념이 아니더라도, 새로운 개념을 추가 학습 없이도 자연스럽게 이해할 수 있다. 이를 제로샷(Zero-shot) 학습이라고 부르며, 기존에 학습하지 않은 새로운 개념도 이해하고 적용할 수 있는 방식이다.
OpenAI 연구팀은 CLIP을 테스트하기 위해 OCR(문자 인식), 비디오 속 동작 인식, 지리적 위치 파악, 다양한 세부 객체 분류 등 30개 이상의 과제를 평가했다. 결과적으로 추가 훈련 없이도 기존의 지도학습 모델과 비슷한 성능을 낼 수 있었다.
Introduction
사전 연구
- Mori et al. (1999)는 이미지와 연결된 텍스트 문서에서 명사와 형용사를 예측하도록 모델을 훈련하여 콘텐츠 기반 이미지 검색(content-based image retrieval)을 개선하려는 시도를 했다.
- Quattoni et al. (2007)는 이미지 캡션의 단어를 예측하는 분류기를 활용하여 효율적인 이미지 표현(image representation)을 학습하는 것이 가능함을 입증했다.
- 2012년에는 Srivastava & Salakhutdinov이 멀티모달 딥 볼츠만 머신(Multimodal Deep Boltzmann Machines)을 사용하여 이미지와 텍스트 태그를 함께 학습하는 연구를 진행했다.
- Joulin et al. (2016)는 합성곱 신경망(CNNs)을 활용하여 이미지 캡션의 단어를 예측하는 방식으로 이미지 표현을 학습하는 연구를 진행했다.
- Li et al. (2017)는 개별 단어 예측을 넘어 문구(phrase) 단위의 n-gram 예측을 수행하도록 학습했고 이를 통해 새로운 이미지 분류 태스크에 대해 제로샷 전이 학습(Zero-Shot Transfer)이 가능함을 증명했다.
Background
Image classification
- 입력 이미지를 사전에 정의한 클래스 중 하나로 분류하는 문제
- 일반적으로 이미지를 입력, 클래스 레이블을 출력으로 하는 지도학습 적용
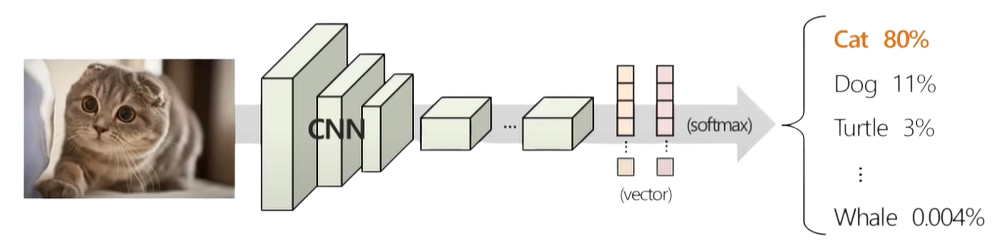
Traditional supervised image classifiers
- 대규모 데이터셋을 기반으로 모델을 pre-traning (사전학습)
예 : ResNet, VGGNet, EfficientNet - 학습된 모델을 fine-tuning하여 다양한 downstream task에 활용
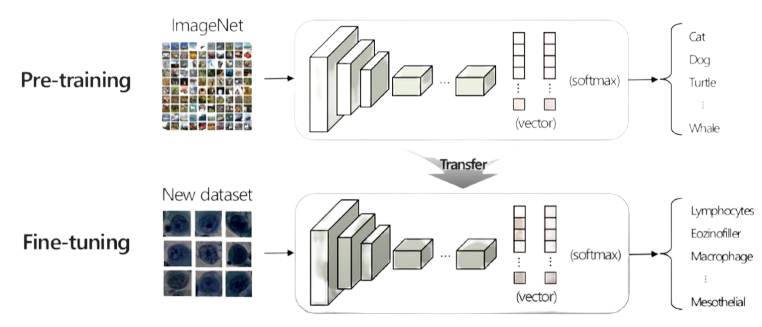
Limitation(1)
- Fine-tuning 없이 새로운 downstream task에 적용하기 어려움
- 모델의 일반화를 하기 어려움
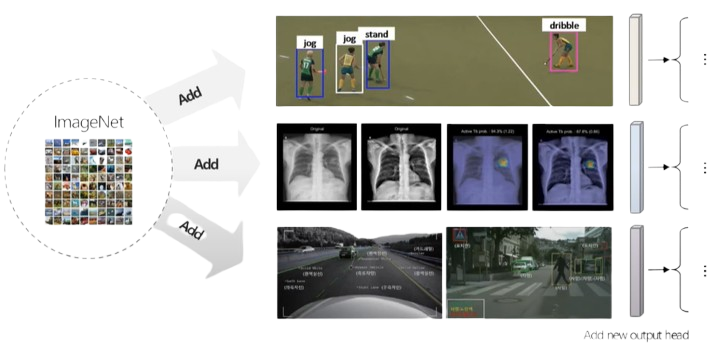
Limitation(2)
- 새로운 downstream task에 적합한 다량의 이미지와 레이블링 작업을 요함
- 이미지 수집 및 정답 레이블 생성에 많은 인력과 비용이 요구됨
Limitation(3)
- 벤치마크 데이터셋 성능과 실제 현실에서 수집한 데이터셋 성능과는 차이 존재
- 벤치마크 데이터셋에 최적화되어 그 외 데이터셋에서는 저조한 성능을 보임
- 모델의 강건성이 떨어짐
- 모델의 강건성이란 머신러닝 모델이 입력 데이터에 작은 변화(perturbation)나 예상치 못한 노이즈가 포함되더라도 성능이 크게 저하되지 않는 성질을 의미함

Downstream task
-
컴퓨터 비전에서의 Downstream task 예시
- 이미지 분류 : 이미지를 특정 범주에 할당
- 객체 탐지 : 이미지 내 여러 객체를 탐지하고 위치 표시
- 이미지 캡셔닝 : 이미지에 대한 설명 자동 생성
- 이미지 세분화 : 픽셀 단위로 객체 분할
-
Downstream task 성능 향상 기법
- Fine-tuning
- Transfer-Learning
- Probing
구체적으로 풀고 싶은 문제를 뜻함
Approach
Natural Language Supervision
CLIP의 핵심은 텍스트(자연어)에서 제공하는 학습 신호를 활용하여 시각적 개념을 학습하는 것이다.
즉, 텍스트가 학습 신호 역할을 하며 모델이 스스로 Image-Text 관계를 학습하는 방식이다.
학습 신호란 모델이 패턴을 학습할 수 있도록 제공되는 정보를 뜻한다.
Use Image-Text pair
- 기존 일반적인 분류 모델은 이미지의 의미론적 정보를 학습하지 못함
- CLIP은 이미지와 이미지를 설명하는 텍스트를 결합한 image-text 쌍을 입력으로 사용함
- 이미지와 언어에 대한 representation을 함께 학습하여 일반화된 특징 학습 가능

Creating a Sufficiently Large Dataset
인터넷에서 4억 개의 image-text 쌍을 수집하여 새로운 데이터셋을 구축한다.
이것이 WebImageText(WIT) 데이터셋이다. WebImageText(WIT) 특징은 다음과 같다.
- 다양한 분야의 image-text 데이터를 수집하기 위해 총 50만 개의 검색 기반
- 이미지 균형을 맞추기 위해 각 검색어당 이미지는 최대 2만개로 조절
- GPT-2의 WebText 데이터셋과 전체 단어 수(word count) 유사

- ImageNet
- 규모 : 1천 400만개
- 범주 : 2만 2천개
- 레이블링 인력 : 약 2만 5천명
- WebImageText
- 규모 : 4억개
- 범주 : 50만개
- 레이블링 인력 : 0명
Selecting an Efficient Pre-Training Method
기존 방식보다 효율적인 대조 학습(Contrastive Learning)을 활용하여 pre-training을 진행하는 방법을 선택했다.
대조 학습(Contrastive Learning)은 정확한 단어를 맞추는 것이 아니라 올바른 image-text pair를 맞추는 방식이므로 학습이 쉬워진다.
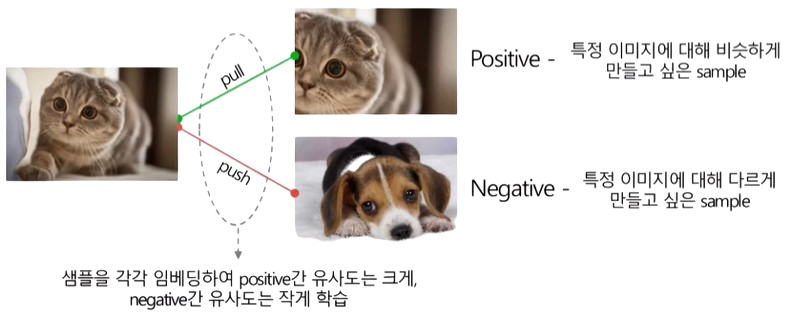

일반적인 대조학습은 이미지만을 사용해 학습하지만 CLIP은 image-text pair를 사용하여 학습한다.
Zero-shot prediction에서도 상대적으로 가장 우수한 성능을 보였다. Zero-shot prediction이란 한 번도 본적이 없는 특정 하위 문제의 데이터셋에서 대해 예측을 수행하는 것을 뜻한다.

Experiments
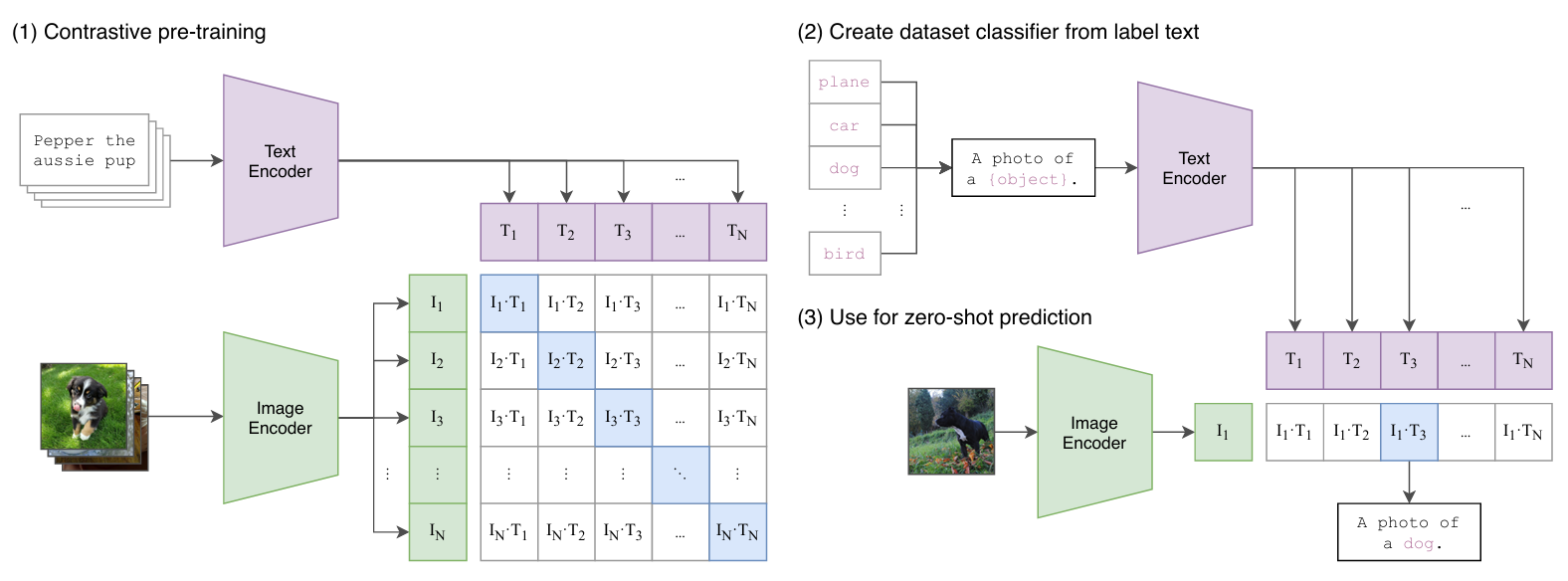
(1) Constrative pre-training
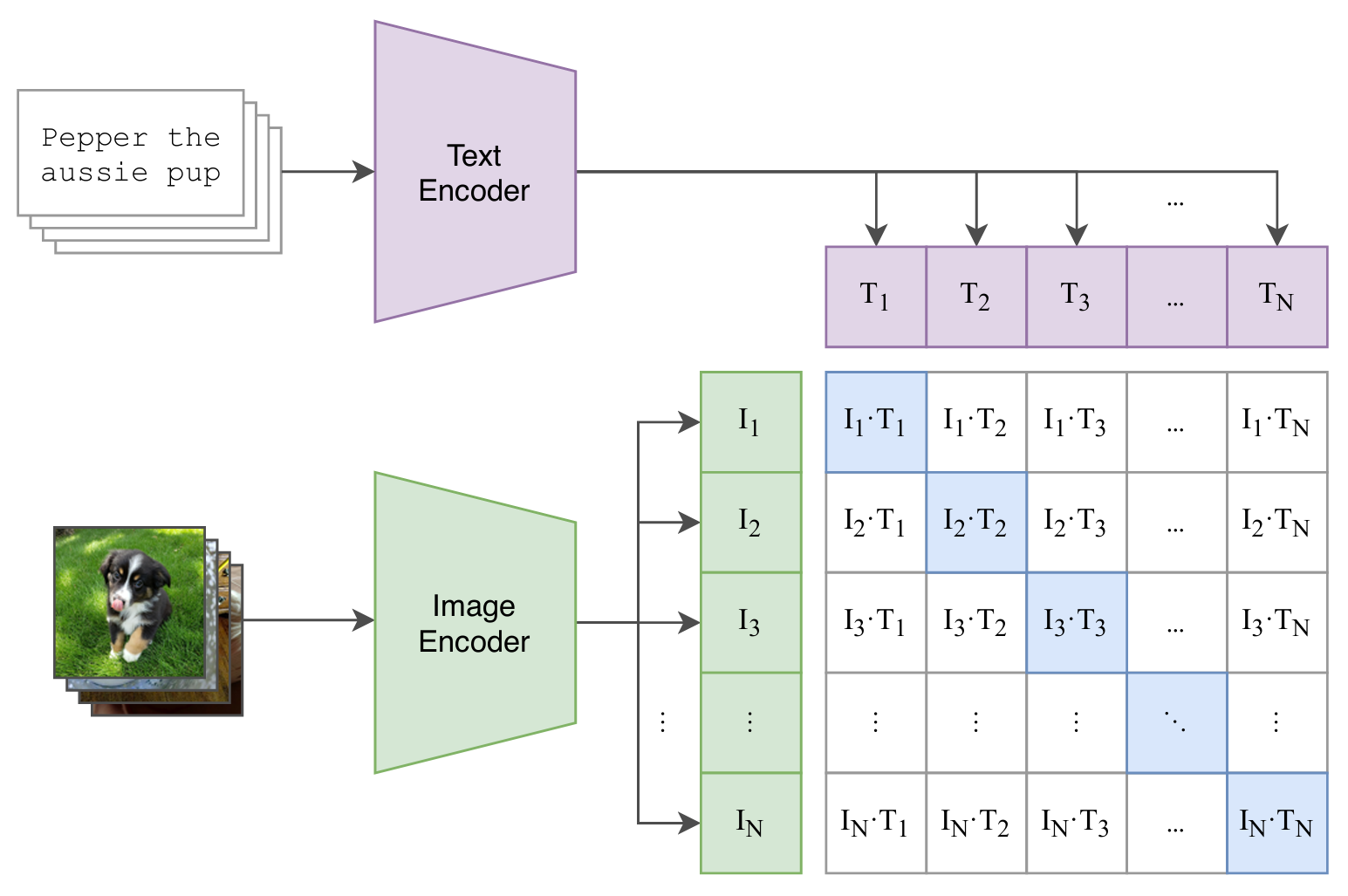
배치 단위로 이루어진 N개의 image와 text를 각각 인코더에 통과시켜 임베딩 벡터를 산출한다.
- image encoder : Modified ResNet, Vision Transformer
- text encoder : Transformer
image와 text 벡터간의 내적을 통해 코사인 유사도를 계산한다.
(2) Create dataset classifier from label text
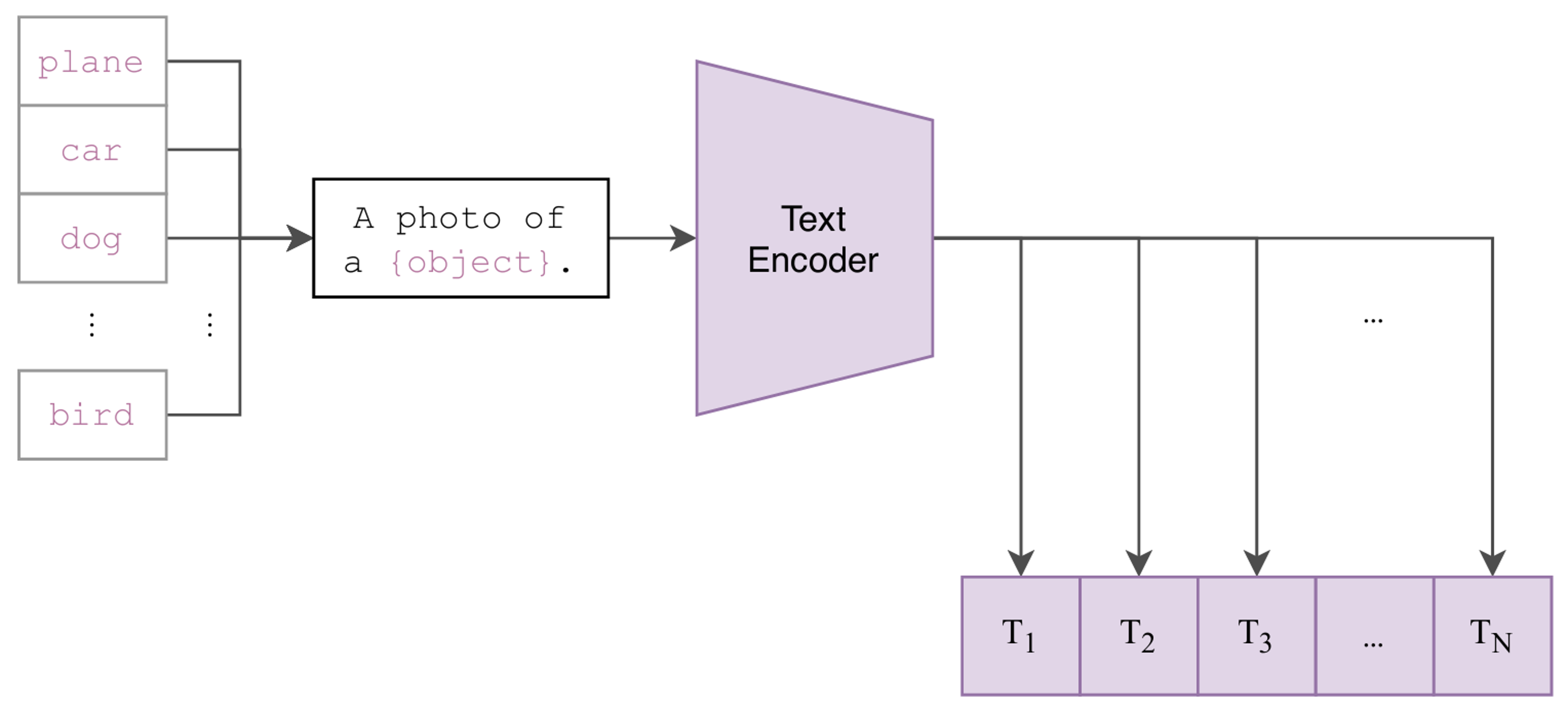
CLIP의 zero-shot 성능을 높이기 위해 사용한 2가지 방법이 있다.
1. 프롬프트 엔지니어링(Prompt Engineering)
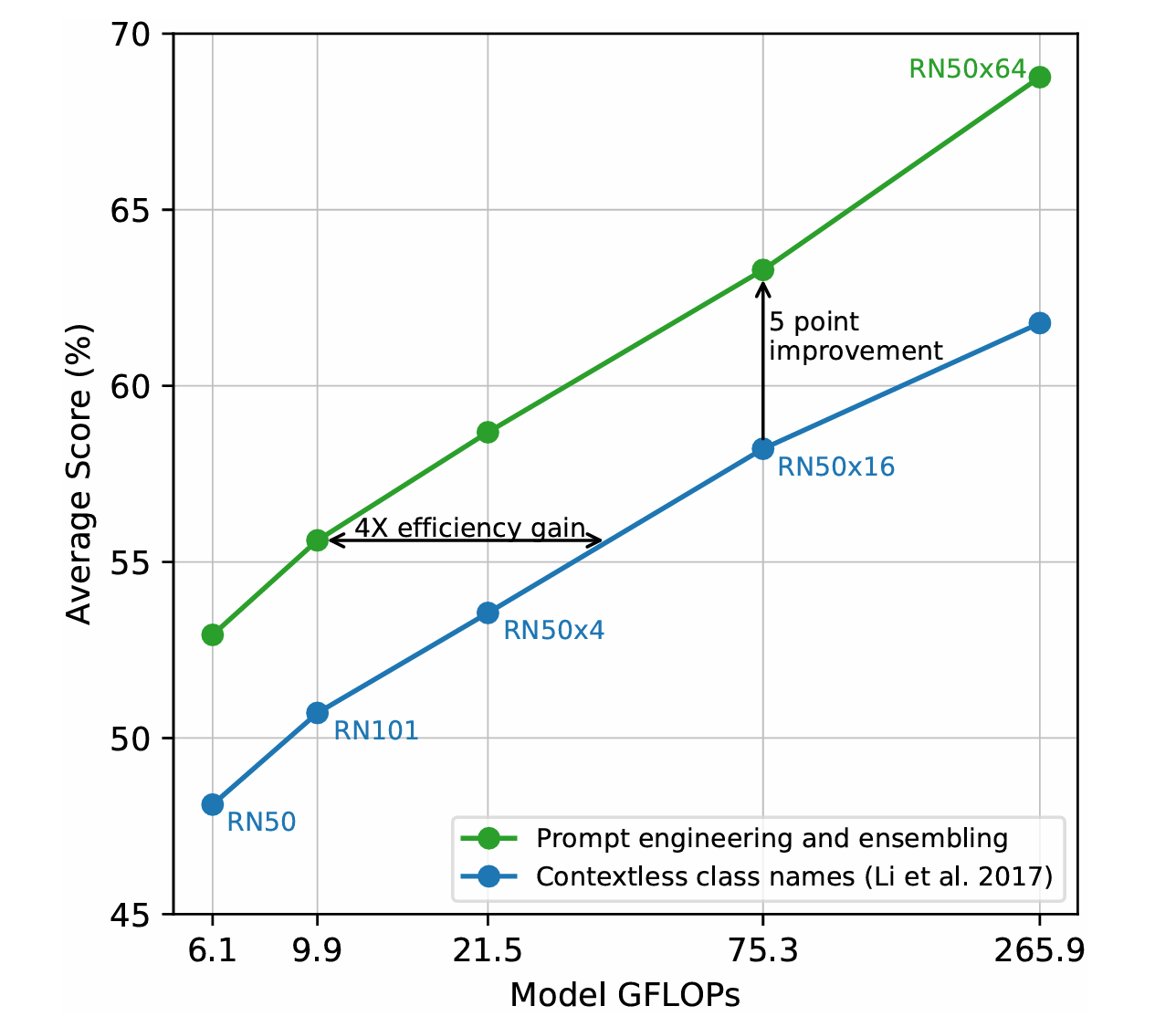
단어만을 사용하게 되면 다의어 문제가 발생하게 된다. 그래서 적절한 문장을 추가하여 문맥을 제공한다. 기본 프롬프트인 A photo of a {label}만 추가해도 ImageNet 성능이 1.3% 향상되었고 태스크별 맞춤 프롬프트를 사용하면 더 높은 성능 향상 가능하다.
이후 학습된 Text Encoder에 통과 시켜 텍스트 임베딩 벡터값을 산출한다.
2. 앙상블(Ensembling)
임베딩 공간에서 앙상블을 수행하여 여러 개의 프롬프트를 사용한 제로샷 분류기 앙상블을 통해 성능을 추가적으로 향상시킬 수 있다.
(3) Use for zero-shot prediction
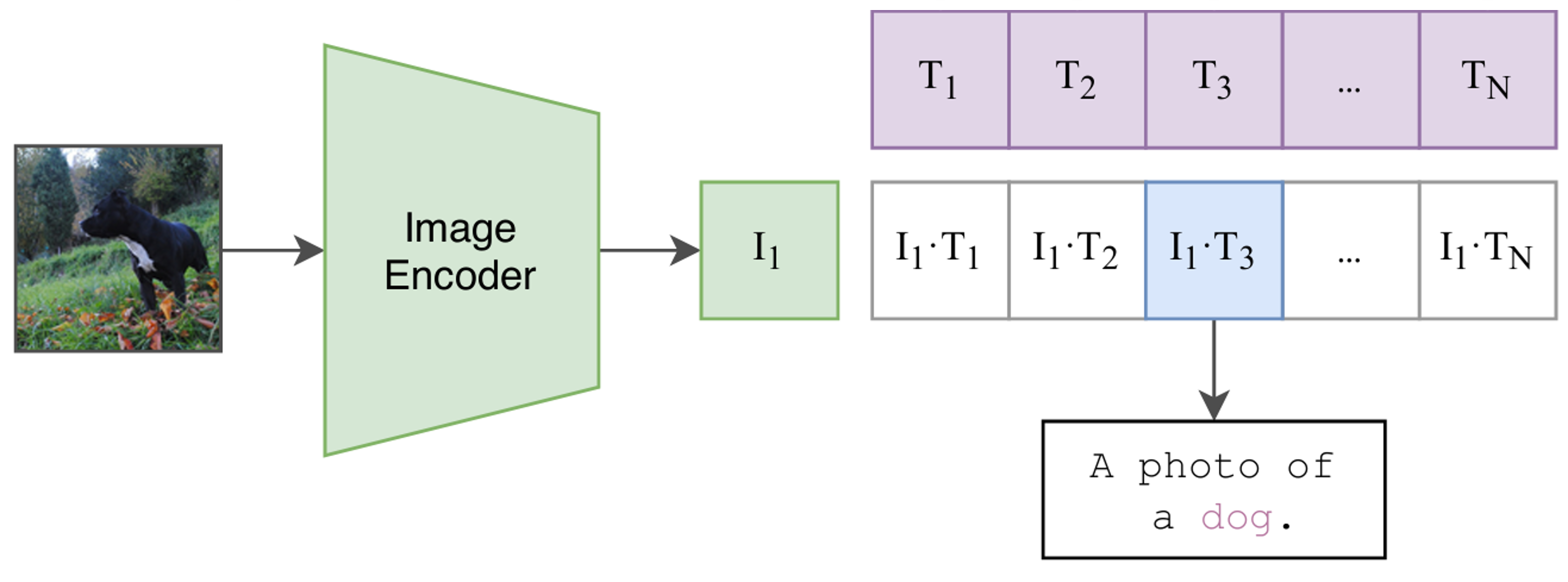
예측하고자 하는 이미지를 학습된 이미지 인코더에 통과시켜 이미지 임베딩 벡터값을 산출한다. 텍스트 임베딩 벡터와 코사인 유사도를 계산하여 상대적으로 높은 값을 갖는 텍스트를 선택한다.
Fine-tuning을 하지 않아도 새로운 이미지에 대해서 예측이 가능하다.
Comparison
Zero-shot CLIP is competitive with a fully supervised baseline
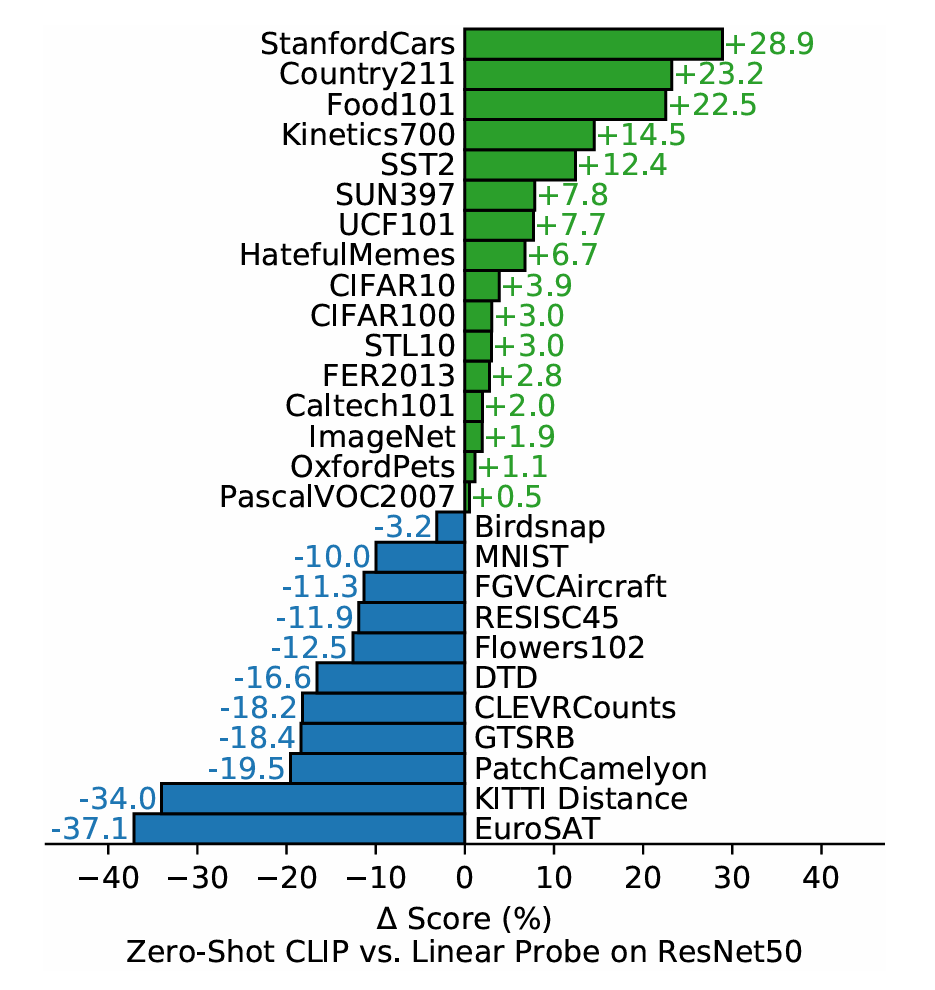
Zero-shot CLIP과 지도 학습(Logistic Regression) 모델을 비교해본 결과 16개의 데이터셋에서 높은 성능을 보였다.
그러나 위성 이미지 분류(EuroSAT), 자율주행 관련 태스크(KITTI Distance), 의료 영상 분석(PatchCamelyon) 등과 같은 데이터셋에서는 약한 모습을 나타냈다.
Zero-shotCLIP is much more robust to distribution shift than standard ImageNet models
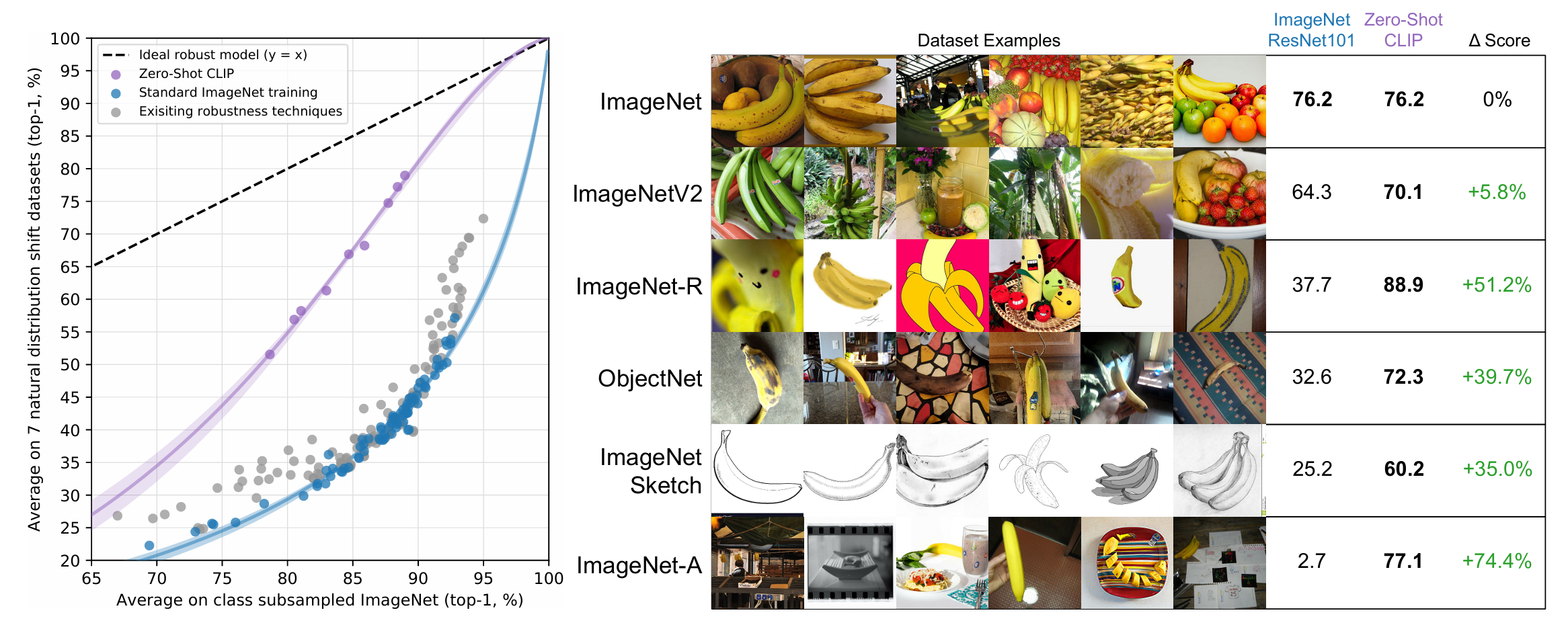
ImageNet 모델은 자연 분포 변화에서 성능이 급격히 저하한다. 반면에 Zero-shot CLIP은 자연 분포 변화에서도 상대적으로 강건성이 높게 나타났다.
Limitations
CLIP은 혁신적인 아이디어이지만 여전히 많은 한계점을 갖고 있다.
-
The performance of zero-shot CLIP is on average competitive with the simple supervised baseline of a linear classifier on top of ResNet-50 eatures.
: CLIP의 Zero-shot 성능이 단순한 ResNet-50 기반 선형 분류기와 비슷하다. -
CLIP’s zero-shot performance is still quite weak on several kinds of tasks
: 특정 태스크에서 성능이 저하한다 -
We’ve observed that zero-shot CLIP still generalizes poorly to data that is truly out-of-distribution for it.
: CLIP은 새로운 태스크에 대해 제로샷 분류기를 생성할 수 있지만 결국 사전 학습된 개념 내에서만 선택할 수 있다. -
CLIP is trained on text paired with images on the internet. These image-text pairs are unfiltered and uncurated and result in CLIP models learning many social biases.
: 사회적 편향 데이터를 학습할 수 있다.
Research Questions
Q1. Fine-tuning이 필요없는 모델이 없을까?
Q2. 이미지 수집 및 정답 레이블 생서에 적은 노력이 드는 모델이 없을까?
Q3. 벤치마크 데이터셋 외 여러 real world에서도 좋은 성능을 보이는 강건성이 좋은 모델이 없을까?
CLIP(Contrastive Language–Image Pretraining)은 대량의 레이블링이 필요없는 데이터셋인 Web-Based image-text pair 기반으로 visual representaion이 가능한 모델로 Zero-shot을 통해 Fine-tuning이 필요없다. Constrative learning 기반 pre-traning을 통해 효율적이고 domain shift에 강건한 학습 가능하다.
출처
-
Learning Transferable Visual Models From Natural Language Supervision
