지난 CLIP 모델을 읽고 스스로가 많이 부족하고 기초부터 차근차근 공부해나가야 한다고 생각이 들었다. 그래서 LMM과 관련된 Review 논문을 찾아 읽었다. 그러나 구글 스칼라에도 등록이 안된 논문이라 아쉬움이 컸다. 다음부터는 더 좋은 논문을 읽을 수 있도록 꼼꼼하게 살펴봐야겠다.

A Survey on Multimodal Large Language Model
읽은 날짜: 2025년 3월 10일 ~ 3월 16일
Abstract
GPT-4V와 같은 멀티모달 대형 언어 모델(MLLM)이 핫해졌다.
이 논문은 최근 MLLM 발전을 요약하는 논문이다.
먼저 MLLM의 기본 개념을 정의하고, 확장된 연구 주제를 다루고, 할루시네이션 문제와 확장기법을 다루고 마지막으로 도전 과제를 논의한다.
Introduction
LLM과 LVM이 발전함에 따라 MLLM의 연구가 빠르게 발전되고 있다.
초기 MLLM 연구는 text prompt를 기반으로 text, image, video, audio를 생성하는 모델 개발에 초점을 맞추었다. 다음은 MLLM 연구의 주요 확장 방향성이다:
(1) 사용자 프롬프트에 대한 더 세밀한 조작이 가능하도록 개선 필요
(2) 기존의 image, video, audio 외에도 다양한 모달리티 확장 필요
(3) 더 다양한 언어 지원 필요
(4) 다양한 분야 및 사용 사례로의 확장 필요
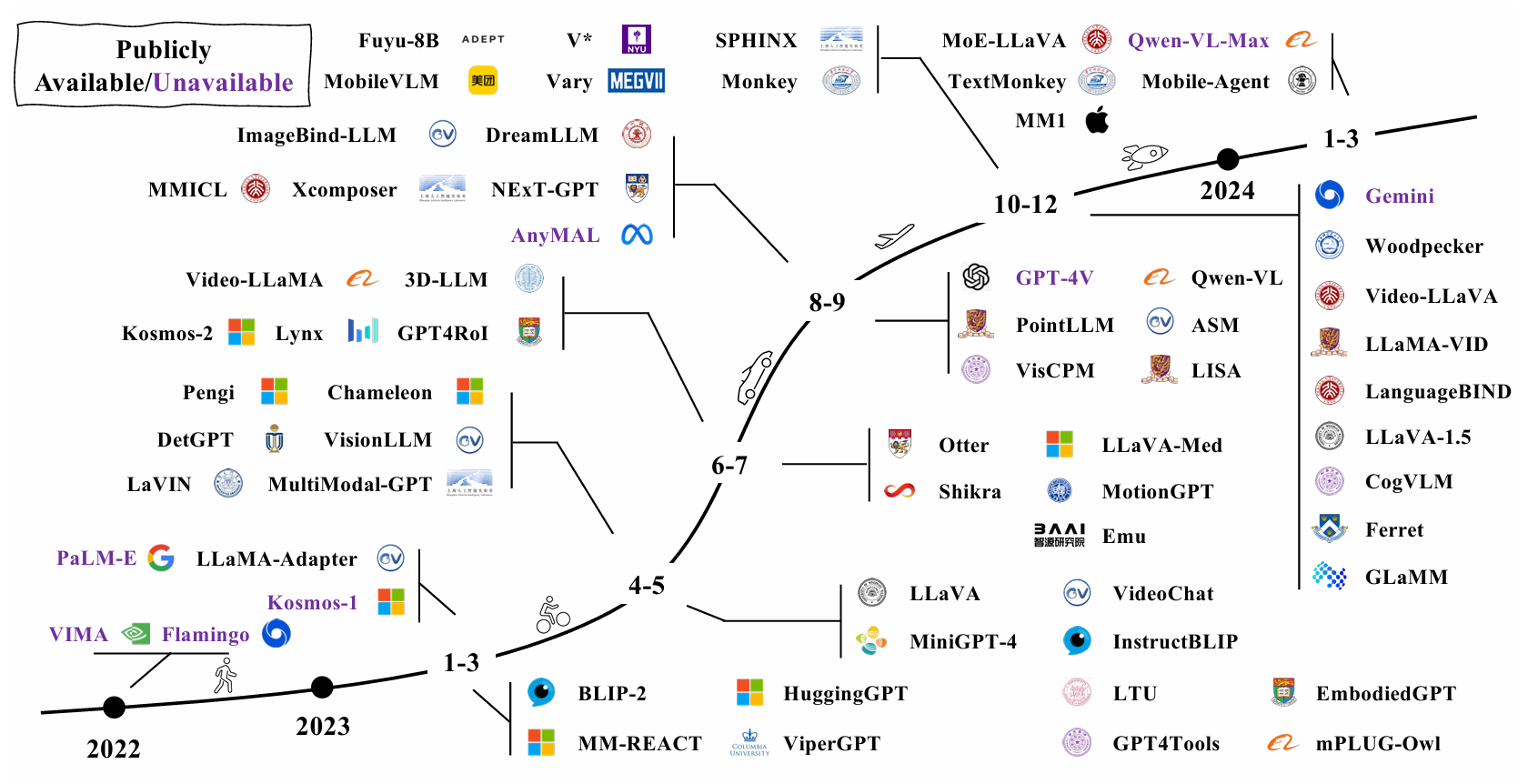
MLLM의 발전 과정은 많이 본 그림이다.
Architecture
MLLM은 세 가지 주요 모듈로 구성된다.
-
사전 학습된 모달리티 인코터(Pre-trained Modality Encoder)
: 인간의 눈/귀 처럼 시각적 청각적 신호를 받아들이고 전처리하는 역할 -
사전 학습된 대형 언어 모델(Pre-trained LLM)
:인간의 뇌처럼 정보를 이해하고 추론하는 역할 -
모달리티 인터페이스(Modality Interface)
: 서로 다른 모달리티를 정렬하는 역할- Project-based(투영 방식) : 비정형 데이터를 임베딩하여 텍스트처럼 변환
- Query-based(질의 방식) : LLM의 image 혹은 audio에서 필요한 정보 추출
- Fusion-based(융합 방식) : LLM과 비정형 데이터의 피처를 직접 융합
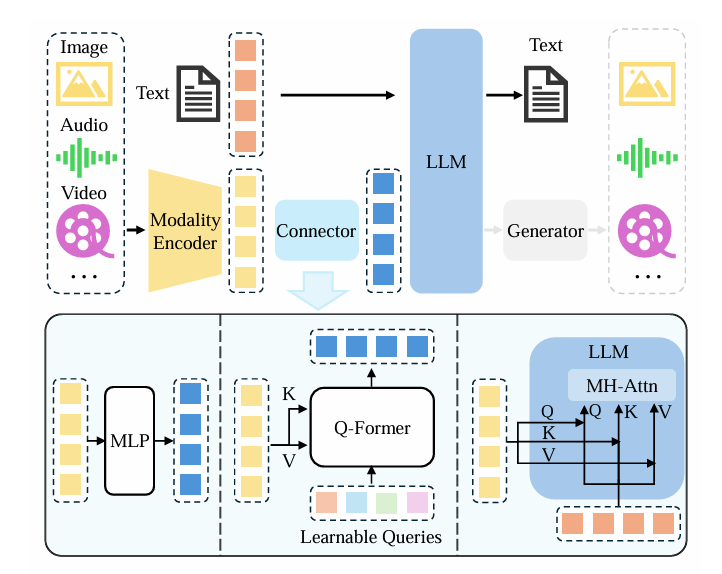
위 세 가지 주요 모듈의 아키텍처를 도식화 한 그림이다.
Pre-trained Modality Encoder
모달리티 인코더는 image, audio 등의 raw data를 압축된 표현(representation : 벡터 형태로 변환)으로 변환하는 역할이다. 일반적으로 처음부터 학습하는 대신 사전 학습된(pre-trained) 인코더를 사용하는 것이 일반적이다. 일부 연구에서는 인코더 없는 (encoder-free) 방식으로 실험되고 있다.
인코더 선택 시 고려할 요소
(1) 해상도(Resolution)
: 고해상도를 사용할수록 성능이 향상됨
- 해상도를 높이는 방법
- 직접 스케일링(Direct scaling) : 더 높은 해상도의 이미지를 인코더에 입력
- 패치 분할 : 큰 이미지를 작은 패치로 나누고, 각 패치를 저해상도 이미지와 함께 인코딩
(2) 파라미터 크기
(3) 학습 데이터 구성
해상도가 가장 중요한 요소이다.
Pre-trained LLM
MLLM을 처음부터 학습을 시키는 것은 비효율적이기 때문에 사전 학습(Pre-trained)된 LLM을 기반으로 모델을 구축한다. LLM은 Web Corpus 학습을 통해 강력한 일반화 능력(Generalization ability)와 추론 능력(Reasoning ability)를 갖게 된다.
Modality Interface
LLM은 text 형식만 이해할 수 있기 때문에 image, audio 등 모달리티를 LLM이 이해할 수 있게 변환해야 한다. 그러나 LMM이 처음부터 끝까지 (end-to-end) 학습하는 것은 비용이 높기 때문에 효율적인 방식으로 학습해야 한다.
- 학습 가능한 연결 모듈 (Learnable Connector)
- 전문가 모델 활용 방식 (Expert Model)
Training
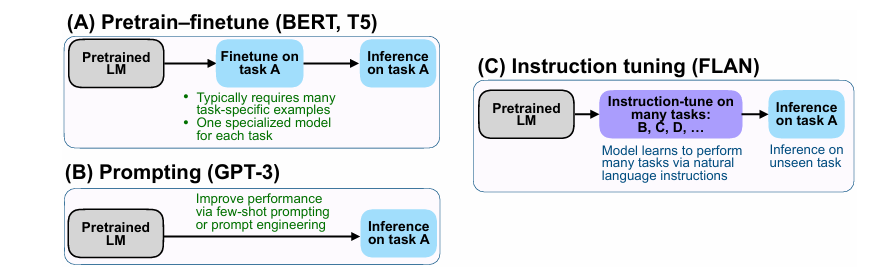
MML을 개발하기 위해서 세 가지 주요 학습 단계를 거쳐야 한다.
- Pre-training (사전 학습)
- Instruction-tuning (명령어 튜닝, 지시 조정)
- Alignment tuning (정렬 튜닝, 사용자 선호 조정)
Pre-training
Training Detail
사전 학습 단계에는 다양한 모달리티들의 정렬을 수행하고 멀티모달 세계지식을 학습하는 것이 목표다. 이 단계에서는 주로 대규모 text-image pair data를 사용하여 모델이 텍스트 및 비전 정보를 결합하는 방법을 학습한다.
다음과 같은 과정이다.
- 이미지와 텍스트 캡션(설명) 데이터를 입력으로 제공
- LLM이 캡션을 예측하도록 학습
- Cross-Entropy를 사용해 모델을 최적화
Data
사전 학습 데이터의 목적은 모달리티 정렬, 세계 지식 학습이다.
데이터 유형
-
Coarsed-grained data (웹 크롤링 데이터)
: 노이즈가 많아 정밀한 모델 학습에는 한계가 있다. -
Fine-grained (고품질 캡션 및 정밀한 정렬)
: 정밀도가 높음
Instruction-tuning
Introduction
Instruction-tuning은 모델이 주어진 사용자 지시문에 따라 더 효과적으로 작동하도록 학습하는 과정이다.
Training Detail

멀티모달의 명령어(instruction), 입력(input), 응답(Response)로 구성된 데이터셋을 사용해 모델을 학습한다.
예를 들어:
Instruction: {사용자의 명령}
Input: {<이미지>, <텍스트>}
Response: {출력 결과}
->
Instruction: "이 이미지에 대한 질문에 답하세요."
Input: {<이미지>, "이 동물의 종은 무엇인가요?"}
Response: "이 동물은 시베리아 호랑이입니다."Data collection
명령어 데이터(Instruction Data)는 형식이 더 유연하고 task 구성 방식이 다양하기 때문에 데이터 수집하는 과정이 더 어렵다
- 데이터 변환
- 자기 생성
- 데이터 혼합
Data Quality
최근 연구는 Data의 양보다 품질이 더 중요하다고 주장한다.
- Prompt Diversity
: 동일 task도 다양한 방식으로 명령어를 구성해야 한다. - Task Coverage
: 다양한 task를 포함해야 한다.
Alignment Tuning
Alignment Tuning은 모델이 인간의 선호도를 반영하여 보다 신뢰할 수 있고 안전한 응답을 생성하도록 조정하는 과정이다.
Training Detail
Alignment Tuning의 대표적인 기법은 RLHF(Reinforcement Learning with Human Feedback)와 DPO(Direct Preference Optimization)이다.
-
RLHF
: RLHF는 인간의 선호도를 반영하여 모델 출력을 개선하며 세 가지 학습 과정을 따른다.(1) Supervised Fine-tuning (지도 학습 기반 미세 조정)
(2) Reward Model 학습 (보상 모델 학습)
(3) PPO(정책 최적화) 기반 강화 학습 -
DPO
: DPO는 보상 모델을 별도로 학습할 필요 없이 직접 선호 데이터를 활용하여 모델을 조정한다.
Extensions
최근 연구는 MLLM의 기본 기능을 확장하는 다양한 방법들이 시도되고 있다.
-
Granularity Support (더 세밀한 데이터 처리 지원)
: MLLM은 일반적으로 text와 image를 큰 단위로 처리하는데 더 세밀한 컨트롤이 가능하도록 확장하는 연구가 진행 중이다. -
Modality Support (다양한 모달리티 지원 확장)
-
Language Support (다국어 지원 강화)
-
Scenario/Task Extension (실제 응용 및 특정 태스크 강화)
: MLLM은 일반적인 대화형 모델로 사용되었지만 특정 산업 및 환경에서 활용될 수 있도록 연구가 진행 중이다.(1) 모바일 환경에서의 경량화 (Lightweight MLLM for Mobile Devices)
(2) GUI 및 실시간 인터랙션 지원 (Human-Computer Interaction)
(3) 의료 및 산업 응용 분야 확대
Multimodal Hallucination
할루시네이션(Hallucination)은 인공지능이 입력한 데이터와 일치하지 않은 잘못된 정보를 생성하는 현상을 말한다.
이 논문에서는 다양한 할루시네이션 유형을 설명했다.
| 유형 | 설명 | 예시 |
|---|---|---|
| 존재 할루시네이션 (Existence Hallucination) | 존재하지 않는 객체를 생성 | "이미지에는 사람이 없는데, 모델이 '남자가 서 있다'고 응답" |
| 속성 할루시네이션 (Attribute Hallucination) | 객체의 속성을 잘못 설명 | "빨간색 사과인데, 모델이 '노란색 사과'라고 설명" |
| 관계 할루시네이션 (Relationship Hallucination) | 객체 간 관계를 잘못 추론 | "고양이가 개 옆에 있는데, 모델이 '고양이가 개 위에 올라가 있다'고 설명" |
Extended Techniques
기존에 있던 기술을 각 모달리티들과 한 공간에 넣어 발전 시켜 나가고 있다.
-
Multimodal In-Context Learning(M-ICL): 모델이 사전 학습 없이 새로운 태스크를 수행하는 능력
-
Multimodal Chain of Thought(M-CoT): 모델이 논리적 사고를 단계적으로 수행하는 기법
-
LLM-Aided Visual Reasoning(LAVR): LLM을 활용하여 이미지 기반 논리적 추론을 강화하는 방식
Challenges and Future Directions
-
대규모 멀티모달 데이터 학습의 어려움
-
멀티모달 정보의 비효율적인 정렬 문제
-
멀티모달 할루시네이션 문제
-
평가 체계의 부족
-
모델의 해석 가능성 및 신뢰성 부족
-
윤리적 문제 및 편향 문제
Conclusion
멀티모달 대형 언어 모델(MLLM)은 최근 AI 연구에서 중요한 주제로 떠오르고 있으며,
text와 image를 결합하여 다양한 task를 수행하는 능력을 보여주고 있다.
특히 GPT-4V와 같은 최신 모델들은 기존 멀티모달 AI가 해결하지 못했던 복잡한 문제들을 처리할 수 있는 가능성을 제시하고 있다.
이 논문에서는 MLLM의 기본 개념, 아키텍처, 학습 전략, 평가 방법, 확장 기술 및 주요 도전 과제를 종합적으로 분석했다.
MLLM이 빠르게 발전하고 있지만 여전히 해결해야 할 중요한 문제가 남아 있다.
출처
