Towards Transforming Tabular Datasets into Knowledge Graphs
읽은 날짜: 2025년 4월 28일 ~ 5월 4일
- 논문 PDF
- Extended Semantic Web Conference (2020)
Abstract
표 형식 데이터를 지식 그래프(KG)에 통합할 수 있는 방법에 대해 중점적으로 다룬다. 여기서 소개한 방법들은 머신러닝 기반이다. 생물 다양성 데이터를 활용하고 있다.
1. Introduction
데이터들은 FAIR 원칙을 따라야 한다.
- Findable
- Accesible
- Interoperable
- Reusable
그러나 데이터 세트를 수동 변환으로 KG에 추가하는 것은 매우 비용이 많이 든다. 이 문제를 해결하기 위해 시맨틱 웹 기술과 머신 러닝 기술을 결합한다.
2. State of the Art
하위 섹션에서 제안된 프레임워크에 필요한 필수 관련 연구를 소개한다.
2.1 Understanding Tabular Data
테이블 데이터의 구조와 의미를 파악하기 위한 두 가지 주요 접근 방식이 있다.
-
KG 매칭: 테이블의 셀 값, 열, 열-열 관계를 지식 그래프(KG)의 엔티티, 클래스, 속성에 매칭시키는 방법이다. 예를 들어 테이블 셀의 "Germany"라는 값을 DBpedia의 dbr:Germany 엔티티에 연결하고 국가 목록이 있는 열을 dbo:Country 클래스에 매핑한다.
-
테이블 속성 학습: 테이블 열의 의미적 속성을 학습하여 지식 베이스(KB)에 존재하지 않을 수 있는 일반적인 열의 클래스를 예측하는 방법이다.
2.2 Understanding Textual Data
- 개체명 인식 (Named Entity Recognition, NER):
NER은 자연어 텍스트에서 언급된 개체(entity)를 추출하고, 미리 정의된 범주(예: 사람, 장소, 조직)로 분류하는 기술이다.
A Survey on Deep Learning for Named Entity Recognition에서는 NER 시스템의 일반적인 프레임워크를 제시하고 접근 방식을 크게 두 가지로 나눈다.
- 전통적인 접근 방식: 규칙 기반, 비지도 학습, 특징 기반 지도 학습 등이 있다. 이 방법들은 의미 있는 특징을 선택하는 것이 중요하다.
- 딥러닝 기술: 순환 신경망(RNN) 등을 사용하여 특징을 자동적으로 학습함으로써 전통적인 방식의 문제점을 해결한다.
-
Bio-NER Biomedical Named Entity Recognition based on Deep Neutral Network은 생물 의학 텍스트에서 단어 벡터를 학습하여 입력 표현을 개선하고 외부 자원(예: Wikipedia Exploiting Wikipedia as External Knowledge for Named Entity Recognition)의 의미 정보를 활용하여 NER 성능을 향상시킨다.
-
관계 추출 (Relation Extraction, RE):
RE는 텍스트 내에서 개체 간의 의미적 관계를 추출하고 분류하는 기술이다.
A Review of Relation Extraction에서는 지도 학습 및 준지도 학습 기술을 다루지만 수동 어노테이션의 부담과 새로운 관계 탐지를 위한 학습 데이터 부족 등의 한계를 지적한다.
Relation Extraction Using Distant Supervision에서는 KB(Knowledge Base, 지식 베이스)를 활용하여 데이터 라벨링 비용 없이 관계 추출을 수행하는 distant supervision 기술을 소개한다. 이 기술은 기존 KB를 확장하는 데 유용하지만 처음부터 KB를 구축하는 데는 적합하지 않다.
4 Research Methodology and Approach
4.1 Research Methodology
 Fig 1. Research methodology pipeline
Fig 1. Research methodology pipeline
Fig 1은 연구 방법론 파이프라인으로 테이블 형태의 데이터를 지식 그래프로 변환하기 위한 연구를 수행하는 데 필요한 단계들을 소개한다.
4.2 Conceptual Model View
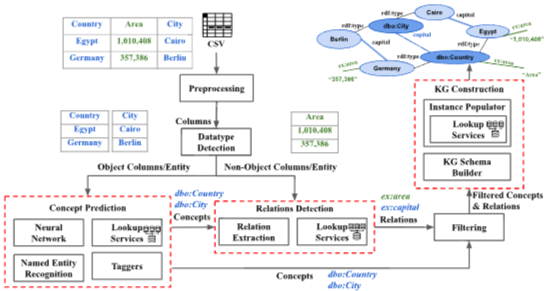
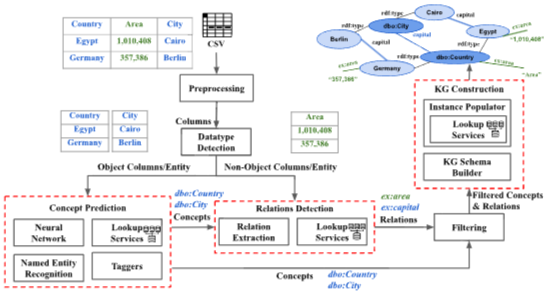 Fig 2. System architecture of the proposed framework with a simple Country-City example in tabular dataset.
Fig 2. System architecture of the proposed framework with a simple Country-City example in tabular dataset.
Fig. 2는 제안하는 프레임워크의 시스템 아키텍처다. 이 프레임워크는 테이블 형태의 데이터셋을 입력으로 받아 이를 지식 그래프(KG)로 변환하는 과정을 나타낸다.
프레임워크는 엑셀 시트(.xlsx) 또는 CSV 파일 형태의 테이블 데이터셋을 입력으로 받고 입력된 테이블 데이터셋은 프레임워크를 통해 완전한 지식 그래프로 변환된다. 이 과정에서 테이블 데이터로부터 스키마와 인스턴스가 추론된다.
이러한 변환 과정은 세 가지 핵심 모듈을 통해 이루어집니다.
-
Concept Prediction (개념 예측): 테이블의 각 열이 나타내는 KG 스키마 클래스를 예측한다. NER, lookup 서비스, 태거(tagger), 분류기(classifier) 등의 다양한 접근 방식을 활용한다.
예시 : city -> dbo:City, country -> dbo:Country -
Relations Detection (관계 탐지): 두 개체 열 사이의 가능한 관계를 추출하거나 도메인 지식을 활용하여 개념과 비-개체(non-object entity) 간의 관계를 찾는다.
예시 : “Berlin” -> capital -> Germany -
KG Construction (KG 구축): 필터링된 개념과 관계를 기반으로 최종적인 지식 그래프를 구축한다.
예시 : “Berlin” -> capital -> Germany
6 Preliminary Results
6.3 Experimental Pipeline
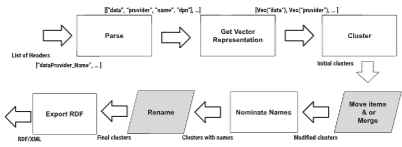 Fig 3. Table header processing pipeline
Fig 3. Table header processing pipeline
Parse (파싱)
: 사람이 읽을 수 있는 형태의 헤더에서 의미 있는 단어들을 추출한다.
-> "dataProvider_Name"헤더에서 "data", "provider", "name"과 같은 단어를 추출
Get Vector Representation (벡터 표현 획득)
: 파싱된 헤더를 벡터 형태로 변환한다.
syntactic : ASCII 코드 기반 (글자 단위)
semantic : word embedding 기반 (의미 단위)
 Table 1. Summary of experimental results
Table 1. Summary of experimental results
실험 결과에서는 semantic이 더 좋게 나옴
Cluster (클러스터링)
: 벡터화된 헤더들을 코사인 거리 기반의 유사도 사용한다.
Move items & or Merge (아이템 이동 및 병합)
: 초기 클러스터링 결과를 바탕으로 사용자가 클러스터의 멤버를 이동하거나 클러스터를 병합하여 클러스터를 수정한다.
Nominate Names (이름 지정)
: 클러스터 멤버들의 공통성을 기반으로 클러스터 이름을 제안한다. 만약 공통 단어를 찾을 수 없다면 "Unknown"이 이름으로 제안된다.
Rename (이름 변경)
: 사용자가 제안된 클러스터 이름을 수동으로 변경한다.
Export RDF (RDF 내보내기)
: 최종 클러스터 결과를 RDF/XML 형태로 내보낸다.
