[논문 Review] VALOR: Vision-Audio-Language Omni-Perception Pretraining Model and Dataset
논문 리뷰
 읽은 날짜: 2025년 4월 14일 ~ 4월 20일
읽은 날짜: 2025년 4월 14일 ~ 4월 20일
Abstract
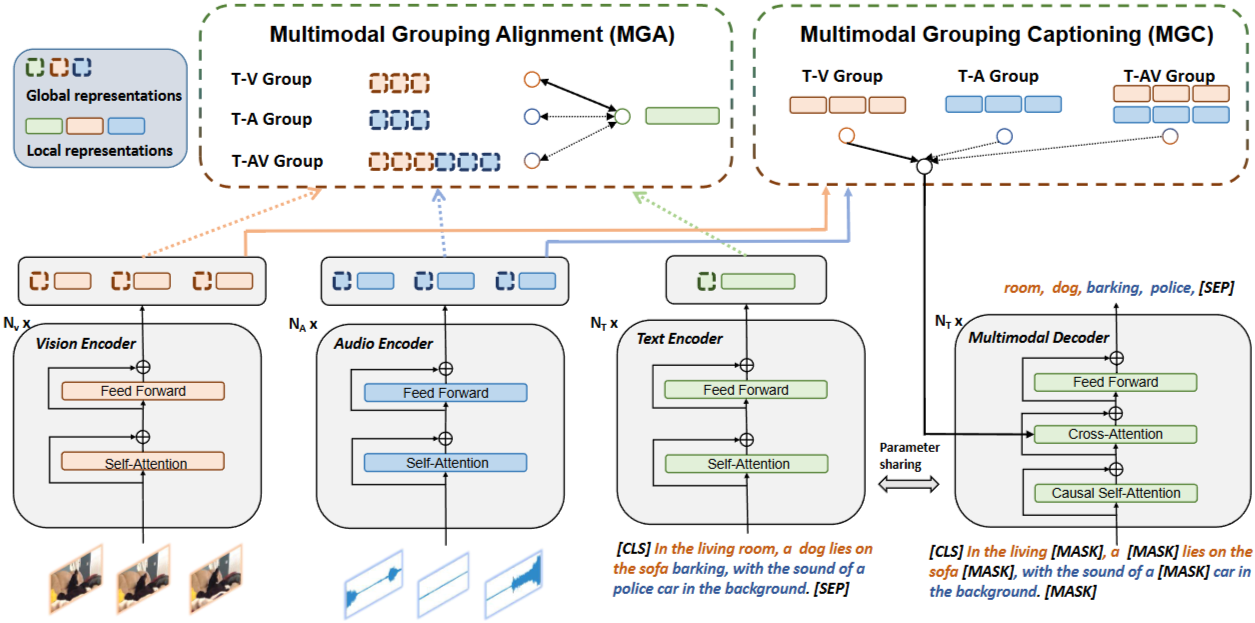
VALOR는 기존 vision-language와 달리 vision, audio, language 간의 관계를 end-to-end 방식으로 공동으로 모델링한다. 단일 modality 표현을 위한 3개의 encoder와 multimodal 조건부 텍스트 생성을 위한 decoder를 포함한다.
two pretext task로 VALOR 모델을 학습한다.
-
MGA (multimodal grouping alignment) : vision, language, audio를 같은 공간에 투영시킴
-
MGC (multimodal grouping captioning) : vision, audio 또는 둘 다의 조건에서 text token을 생성하는 방법을 학습
사용된 데이터셋은 VALOR-1M이다. 이 데이터는 인간이 주석을 단 시청각 캡션이 포함된 1M개의 오디오가 들리는 비디오로 구성된다.
VALOR는 cross-modality 벤치마크에서 sota 모델을 기록했다.
Introduction
자기지도학습(self-supervised learning)의 발전함에 따라 vision-language pretraining이 빠르게 발전했다. 그러나 vision과 language 간의 관계를 모델링하는 것만으로는 아쉽기 때문에 audio-modality를 추가 도입한다. audio-modality를 활용하면 vision을 보완할 수 있고 기계가 주변 환경을 더 잘 이해할 수 있다.
 Fig1. VALOR는 vision-audio-language 데이터를 pretraining을 사용하여 여러 task에 일반화할 수 있다.
Fig1. VALOR는 vision-audio-language 데이터를 pretraining을 사용하여 여러 task에 일반화할 수 있다.
통합된 end-to-end 프레임워크에서 세 가지 modality를 모델링하면 모델의 일반화 기능을 향상시키고 다양한 vision-language, audio-language, audiovisual-language 및 vision-audio downstream task에 도움이 될 수 있다.
VALOR는 두 개의 pretext task가 있다.
-
Multimodal Grouping Alignment (MGA)
: 세 모달리티(vision-language, audio-language, audiovisual-language)를 한 공간에 넣고 세밀하게 정렬을 한다. -
Multimodal Grouping Captioning (MGC)
: cross-attention layer를 통해 vision, audio 또는 둘 다에 의해 조건화된 임의로 modeling된 텍스트 token을 재구성하도록 요구한다.
기존에 공개되어 있는 데이터는 audio-signal이 포함되어 있지 않아 tri-modality model을 훈련하는데 적합하지 않다. 그래서 vision-audio-language dataset (VALOR-1M)을 구축한다. 이 데이터셋은 인간이 주석을 단 시청각 캡션이 포함된 오디오가 들리는 비디오다.
또한 audiovisual-language를 평가하기 위해 VALOR-32K 벤치마크도 만들었다.
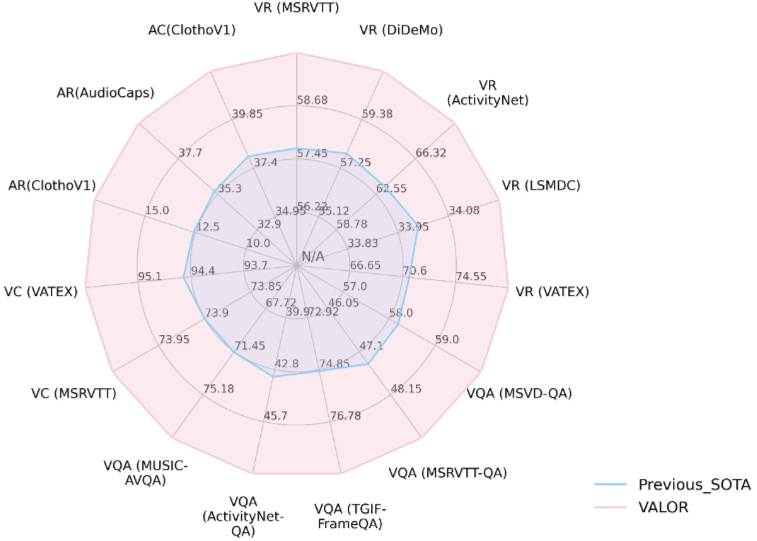 Fig2. VALOR는 cross-modality 벤치마크에서 sota 모델을 달성했다.
Fig2. VALOR는 cross-modality 벤치마크에서 sota 모델을 달성했다.
Related work
멀티모달 pretraining에 사용하는 cross-modality dataset 소개와 vision-language pretraining 방법과 video-language 학습을 위해 vision 및 text 이상의 modality를 활용하는 방법을 소개한다.
Cross-modality datsets for multimodal pretraining
사전학습을 위해서 이상적인 vision-language dataset을 충분히 큰 스케일과 강력한 visual-textual 상관관계라는 두 가지 기본 요구 사항을 충족해야 한다. 문장 수준 캡션 주석이 단어 수준 레이블 태깅보다 훨씬 더 많은 리소스를 소비한다는 점을 고려해서 일부 방법에서는 사람의 음성이 포함된 비디오를 수집하고 ASR transcription 캡션으로 추출하려고 시도한다.
 Fig 3. 비디오-언어 사전 훈련 데이터세트 시각화
Fig 3. 비디오-언어 사전 훈련 데이터세트 시각화
-
HowTo100M은 122만 개의 해설된 교육용 YouTube 동영상에서 가져온 1억 3,600만 개의 비디오 클립으로 구성되어 있으며 초기 video-language pretraining 방법에서 주로 사용하는 dataset이 되었다.
-
위와 같은 방식을 따라 6백만 개의 YouTube 동영상에서 가져온 1억 8천만 개의 clip을 포함하는 YT-Temporal180M을 제안했다.
-
더 다양한 이미지와 더 큰 이미지 해상도를 가진 330만 개의 YouTube 동영상에서 가져온 1억 개의 clip으로 구성된 HD VILA 100M을 수집했다.
그러나 YouTube를 통한 dataset의 캡션의 품질이 만족스럽지 않다. 게다가 speech 인식 에러가 날 수도 있고 ASR transcription은 객관적인 아이디어 대신 주관적인 아이디어를 전달할 수 있다. 또한 시간적 불일치 문제도 있다.
이러한 문제를 극복하기 위해 alt-texts와 쌍을 이루는 250만 개의 비디오로 구성된 WebVid를 수집했다. 완전하지는 않지만 alt-texts는 ASR transcription 보다 비디오 컨텐츠와 더 강력한 상관관계를 가지며 최신 video-language pretraining 방법에 널리 사용되었다. 그러나 vision-audio-language pretraining 데이터가 없으므로 tri-modality pretraining 개발을 위해 VALOR-M datasset 수집을 하게 되었다.
vision-language pretraining
Bert의 성공에 영향을 받아 vision-language pretraining이 빠르게 발전했다.
1) cross-modality pretraining framework design
다양한 네트워크에 따라 vision-language 모델을 주로 dual-encoder 패러다임과 fusion-encoder 패러다임으로 나뉜다.
-
dual-encoder : vision과 language를 가볍게 융합하여 교차 modality 검색 및 zero-shot 분류에 효율적으로 사용할 수 있다.
-
fusion-encoder : 두 modality를 깊이 융합하여 캡션 또는 VQA와 같은 세분화된 작업에 적합하다.
또한 다양한 자기지도학습 pretext tasks가 더 나은 cross-modality 기능 표현 학습을 위해 제안되었다. 예를 들어 MLM, MVM, VTM, VTC가 있다.
시각적 표현과 관련해서 초기 방법에는 off-line 객체 감지기(예를 들어 Faster R-CNN)을 사용하여 객체 수준 이미지 기능을 추출하거나 3D Convolutional neural networks를 사용하여 clip-level video 특징을 추출한다.
vision transformer의 등장으로 image-language와 video-language는 모델 이미지 또는 샘플링된 프레임을 공급하여 통합할 수 있다.
2) unified multi-task modeling
통합된 multi-task 모델링을 위해 통합된 프레임워크로 다양한 작업을 보편적으로 모델링하고 task-sepcific fine-tuning 헤드를 제거해 pretraining 데이터를 더 효율적으로 활용한다. VL-T5가 처음으로 sequence-to-sequence framework를 사용해 VQA(이미지를 입력으로 받아 해당 이미지에 대한 자연어 질문에 답변) 및 visual grounding(자연어로 주어진 설명 이미지 상의 어느부문을 의미하는지 찾는 task)과 같은 vision-language 작업을 모델링한다. sequence-to-sequence 외에도 일부 연구에서는 constrative learning 혹은 masked language modeling을 통해 여러 vision-language 작업을 통합하기도 한다.
그러나 위의 방법들을 사용해 여러 작업을 통합했더라도 vision-language 도메인에 제약된다. 반면에 VALOR는 visionaudio-language 도메인으로 일반화될 수 있다.
3) vision-language foundation models
vision-language 모델은 constrative learning, language modeling으로 지도학습 된다. Foundation models는 vision-language 벤치마크에서 우수한 성능을 달성했다.
예를 들어
-
Flamingo : 모델 크기를 80.2B로 확장해 VQAv2에서 84점(accuracy)을 획득했다.
-
GIT2 : 데이터 크기를 129B image-text 쌍으로 확장하여 COCO Caption에서 149.8 CIDG 점수를 획득했다.
하지만 파라미터 수나 데이터 양을 늘리는 접근은 계산 비용과 분산 학습 복잡도 때문에 비효율적이다. 이에 비해 VALOR는 audio를 추가하여 tri-modality connection을 구성함으로써 모달리티 차원에서의 확장으로 더 효율적이다.
Auxiliary Modality Enhanced Video-Language Understanding
비디오는 multimodal 매체이며 각 modality는 풍부한 의미를 포함하므로 video-language를 향상시키기 위해 더 많은 modality를 활용했다.
-
MMT는 text-video 검색을 위해 7개의 modal 전문가를 융합하는 멀티모달 트랜스포머를 제안했다.
-
SMPFF는 비디오 캡셔닝 성능 향상을 위해 객관적 특징과 오디오 특징을 추가했다.
pretraining 환경에서 audio와 subtitle이 보조 modality로 많이 사용된다. 기존 연구에서 UniVL, VLM, MV-GPT 등은 비디오 + 자막 중심이고 AVLNet, MCN은 audio를 사용한다. 그래서 대부분은 pretraining과 fine-tuning 간 modality 불일치 문제가 발생한다.
VALOR의 차별성은
1. tri-modality dataset (vision-audio-language) 사용해서 pretraining과 fine-tuning 간 일관성이 있다.
- discriminative, contrasitive, generative task가 모두 가능하다. 이는 통합 아키텍처와 설계된 사전학습 task 덕분이다.
VALOR DATASET FOR AUDIOVISUAL-LANGUAGE PRETRAINING
캡션이 ASR transcription 또는 alt-text인 video-language dataset은 텍스트 문장과 오디오 개념 간의 명시적 대응이 부족하여 vision-audio-language pretraining에 적합한 task가 아니다. 기존 video-language dataset의 한계(audio와 text의 불일치)를 극복하기 위해, VALOR는 audio-vision-language가 강하게 연결된 데이터셋을 새로 구축했다.
audiovisual data collection
vision-audio-language 데이터셋의 비디오는 품질과 다양성을 갖춘 data가 필요하기 때문에 audio 인식을 위해 수집된 dataset인 AudioSet에서 video를 선택한다. AudioSet에서 YouTube url이 유효한 것과 품질을 필터링해서 1M개의 비디오를 다운로드 했다. 이 데이터를 쪼개 VALOR-1M tri-modality pretraining dataset을 만들고 VALOR-32K audio-visual-language downstream benchmark dataset으로 만들었다.
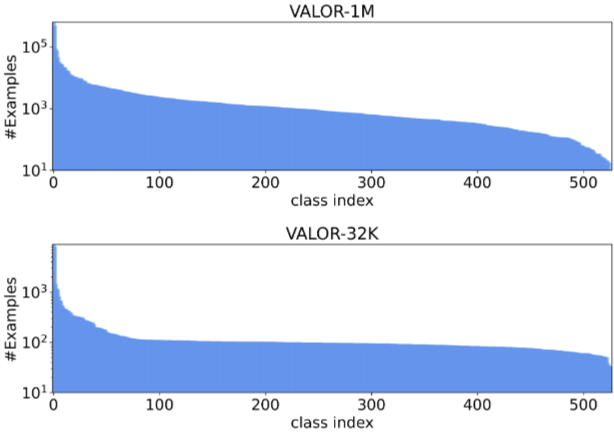 Fig 4. VALOR-1M과 VALOR-32K의 audio 클래스 분포
Fig 4. VALOR-1M과 VALOR-32K의 audio 클래스 분포
VALOR-32K는 VALOR-1M에 비해 균형 잡힌 audio 클래스 분포를 가진다.
AudioVisual Caption Annotation
VALOR dataset에 대한 audiovisual 설명을 얻기 위해 돈을 지급하고 수작업으로 labeling을 진행했다. 이러한 주석 작업을 3가지 step으로 진행했다.
step1. annotator training
500명을 온라인 교육을 실시하고 중요한 구성 요소가 설명에 포괄적으로 반영되어야 함을 강조한다. 주석 형식을 미리 숙지하게 sample video-audio caption을 제공한다. 또한 각 video가 어떤 소리와 연관이 있는지 미리 정리한 사전 정보로 제공하고, 주석자들이 라벨링을 시작하기 전에 이를 참고해서 더 정확한 설명을 작성하도록 한다.
step2. first-stage annotaion
주석자에게 VALOR-32K 영상을 제공하고 주석자들이 작성한 주석을 검토하고 문제점을 피드백하고 재수성 요청을 한다. 이 과정을 반복함으로써 주석자들이 어떤 주석이 좋은 주석인지 학습하고 라벨링 품질을 점차 향상 시킨다.
step3. second-stage annotation
VALOR-1M의 영향에 대해 주석자들이 설명을 작성하고 3명의 검수자들이 다시 확인한다. 만약 3명 중 2명 이상이 '품질이 낮다'고 판단하면 해당 설명을 다시 작성해야 한다.
VALOR-32K Benchmark
VALOR-32K 벤치마크를 만들어 audiovisual retrieval(AVR)과 audiovisual captioning(AVC)의 두 가지 작업이 포함된다.
 Fig 8. VALOR-32K 벤치마크에서 다양한 모델들의 예측 결과를 시각화한 것
Fig 8. VALOR-32K 벤치마크에서 다양한 모델들의 예측 결과를 시각화한 것
AVC는 모델이 들을 수 있는 비디오에 대한 오디오 시각적 캡션을 생성하도록 요구하고 AVR 작업에서는 모델이 주어진 오디오 시각적 캡션 쿼리에 따라 가장 일치하는 비디오 후보를 검색해야 한다.
Characteristics of VALOR Dataset
VALOR는 vision, audio, language 간의 연관성이 강한 최초의 대규모 데이터셋으로 중요한 점은 풍부한 오디오 개념정보와 시청각 기반의 고품질 설명 데이터에 있다.
Quantitative Comparison
다양한 데이셋에서 캡션에 언급된 오디오 개념의 풍부함을 평가하기 위해 ACD(캡션 안에 오디오 관련 단어가 얼마나 많이 들어 있는지의 지표)라는 지표를 정의한다. 632개의 오디오 클래스 온톨로지에 따라 오디오 개념 세트를 확립했다.
다음과 같이 전처리 한다.
- 쉼표로 나뉜 유사 개념이 있는 경우 해당 클래스를 여러개로 분할
- 모든 단어를 소문자로 변환
- 구두점 제거
이 과정을 거쳐 759개의 audio concepts을 얻는다. 하나의 캡션이 주어지면
- 소문자로 변환하고 구두점을 제거
- 각 오디오 개념이 해당 캡션에 존재하는지 탐지
이 작업을 반복하면서 ACD 지표를 계산한다.
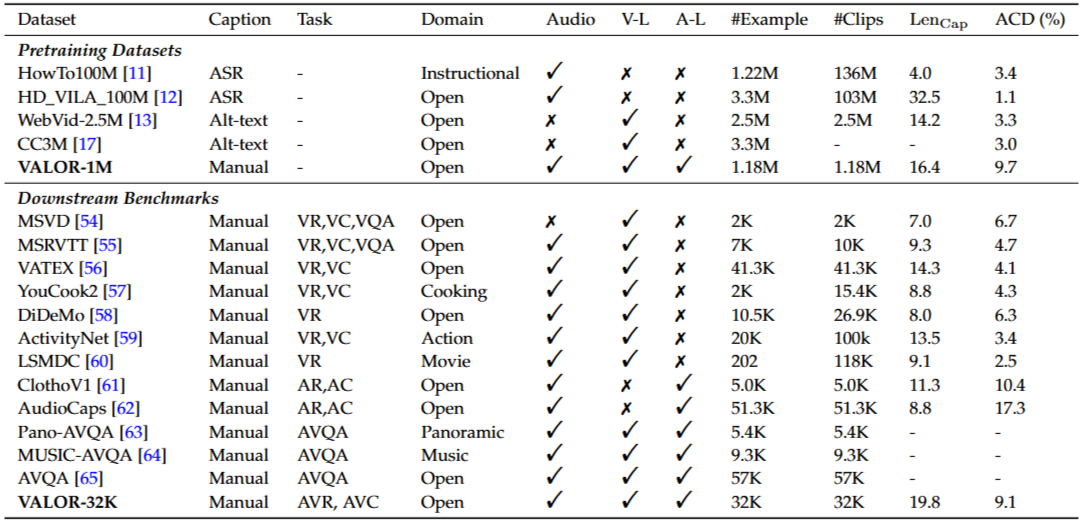 Table 1. 비디오-언어 사전학습(pretraining) 데이터셋과 다운스트림 벤치마크(benchmark) 데이터셋들에 대한 통계표
Table 1. 비디오-언어 사전학습(pretraining) 데이터셋과 다운스트림 벤치마크(benchmark) 데이터셋들에 대한 통계표
VALOR dataset의 ACD값이 다른 video-language dataset 보다 높고 캡션 길이도 길다.
Qualitative Comparison
VALOR-1M을 다른 dataset과 비교했을 때 영상 속의 시각 정보와 소리 정보를 동시에 정확히 반영한 고품질 주석을 제공한다.
- HowTo100M의 캡션은 문장이 불완전하다
- HDVILA 100M은 캡션에 중요한 시각 정보는 반영되지 않는다.
- WebVid-2.5M은 소리(audio)에 대한 묘사가 부족하다.
