 Recent Trends in Deep Learning Based Natural Language Processing
Recent Trends in Deep Learning Based Natural Language Processing
읽은 날짜: 2025년 3월 31일 ~ 4월 13일
- 논문 PDF
- IEEE (2018)
- NLP Review Paper
Abstract
이 논문에서는 수많은 NLP 분야에 적용된 의미 있는 딥러닝 모델과 기법을 설명한다.
또한 다양한 모델들을 비교, 대조함으로써 딥러닝 기반 NLP 분야의 과거, 현재, 미래에 대해 이해할 수 있도록 해준다.
Introduction
자연어처리(NLP)는 인간 언어를 분석하고 표현하는 계산 기법으로 초기 배치 처리 시대에서 오늘날 실시간 웹처리 시대로 발전해왔다. 최근 딥러닝의 발전으로 기존의 얕은 머신러닝 모델 대신 뉴럴 네트워크 기반의 dense 표현 학습이 각광받고 있다.
전통적인 NLP는 사람이 직접 추출한 피처에 의존했지만 딥러닝은 자동화된 표현 학습을 가능케 한다. Collobert 등의 연구 이후 NER, SRL, POS tagging 등 다양한 태스크에 딥러닝이 적용되며 성능을 개선해왔다.
이 논문은 CNN, RNN, Recursive NN, 어텐션, 강화학습, 심층 생성 모델 등 다양한 딥러닝 기법을 종합적으로 소개한다.
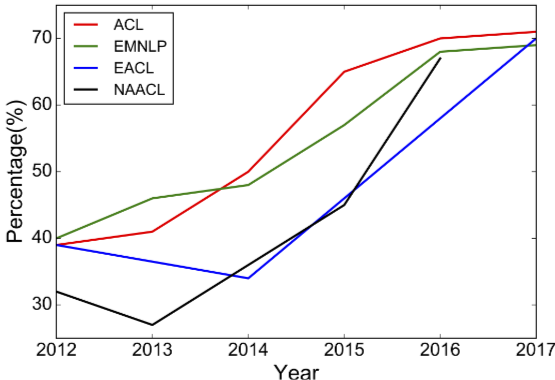 Fig 1. NLP 학회들의 논문 비율
Fig 1. NLP 학회들의 논문 비율
DISTRIBUTED REPRESENTATION
word Embeddings (단어 임베딩)
딥러닝 모델의 첫 번째 데이터 처리 계층에 자주 사용한다.
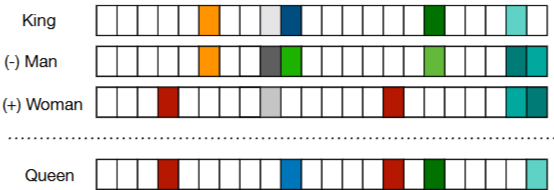 Fig 2. 벡터로 표현된 분산 벡터
Fig 2. 벡터로 표현된 분산 벡터
레이블이 없는 방대한 말뭉치(corpous)에서 '보조적인 목적함수'를 최적화함으로써 사전 학습한다.
- 보조적인 목적 함수 : 이웃단어로 중심단어 예측, 각 단어벡터는 일반적인 문법적, 의미적 정보를 내포함
word Embeddings의 특징으로는
- 문맥 유사도를 잡아내는데 효율적
- 차원이 작아 덕분에 계산이 빠르고 효율적
- 문맥을 통해 학습
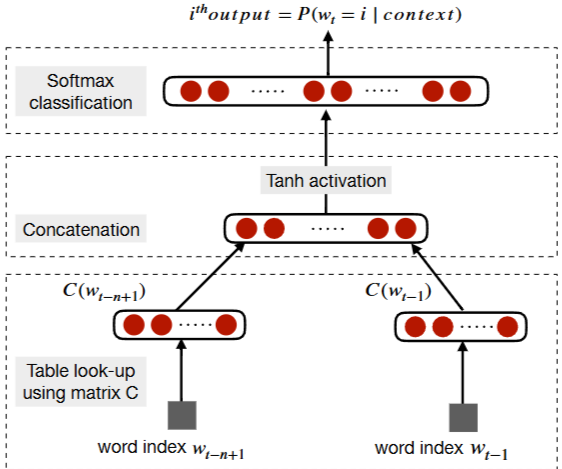 Fig 3. 신경 언어 모델
Fig 3. 신경 언어 모델
Word2vec
Word2vec는 대표적으로 2개의 모델이 있다.
- CBOW (Continuous Bag of Words) : k개 만큼의 주변 단어가 주어졌을 때 중심 단어의 조건부 확률을 계산
- Skip-Gram : 중심단어가 주어지면 주변 단어를 예측
단, 개별 임베딩에는 한계점이 있다.
- 두 개 이상의 단어 조합이 개별 단어 벡터의 조합으로 표현될 수 없다.
- 주변 단어의 작은 window 내에만 기반한 임베딩을 학습한다.
레이블이 없는 데이터로부터 n-gram 임베딩을 직접적으로 학습시키는 방법이다.
- n-gram : 문장을 연속된 N개의 단어(또는 문자) 단위로 잘라서 보는 방식
n-gram 종류- n = 1(Unigram) : 텍스트를 개별 단어 또는 문자로 분리한 것
- 예시 (단어) : '나는', '학교에', '간다'
- 예시 (문자) : '나', '는', '학', '교', '에', '간', '다'
- n = 2(Bigram) : 연속된 2개의 단어 또는 문자의 시퀀스
- 예시 (단어) : '나는 학교에', '학교에 간다'
- 예시 (문자) : '나는', '는 학', '학교', '교에', '에 간', '간다'
- n = 1(Unigram) : 텍스트를 개별 단어 또는 문자로 분리한 것
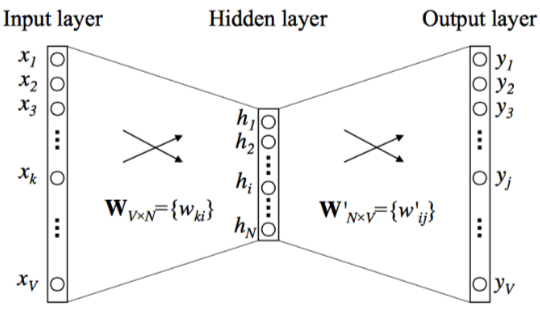 Fig 4. CBOW 모델
Fig 4. CBOW 모델
Character Embeddings (문자 임베딩)
미등재 단어(the unknown word) 이슈에 자연스럽게 대처하게 된다. 단어는 개별 문자의 결합이다.
Contextualized Word Embeddings (맥락화된 단어 임베딩)
최근 자연어 처리(NLP) 분야에서는 단어의 의미를 문맥에 따라 파악하는 맥락화된 단어 임베딩이 주목받고 있다.
기존 워드 임베딩 방식과 달리 ELMo와 같은 모델은 문맥을 고려하여 단어의 의미를 정확하게 표현한다. 특히 BERT와 같은 모델은 Transformer 네트워크를 활용하여 문장 내 단어 간 관계를 학습하고 QA나 NLI와 같은 작업에서 뛰어난 성능을 보인다.
이러한 맥락화된 임베딩은 전이 학습을 통해 NLP 모델의 성능을 크게 향상시킬 수 있다.
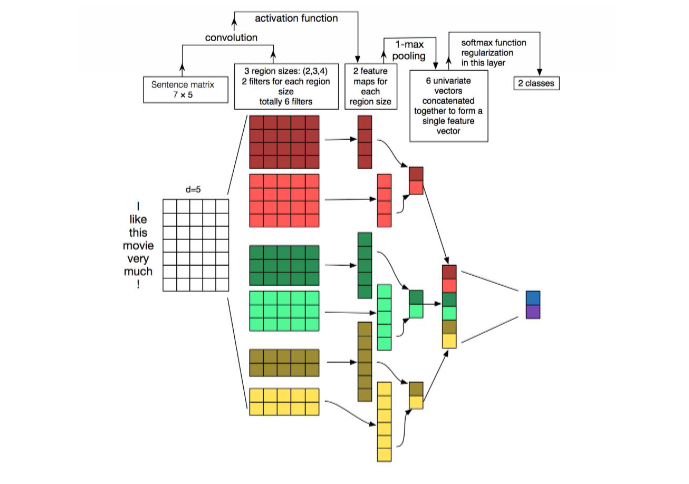
CONVOLUTIONAL NEURAL NETWORKS (CNN)
문장 모델링에서 CNN을 사용하는 것은 다범주 예측 결과를 출력하기 위해 multi-task learning을 사용해 NLP 과제를 수행하기 위함이다.
참조 테이블을 활용해 벡터 나열로 변환한다.
- 참조 테이블 : 단어와 해당 단어의 벡터를 짝지어 놓은 사전
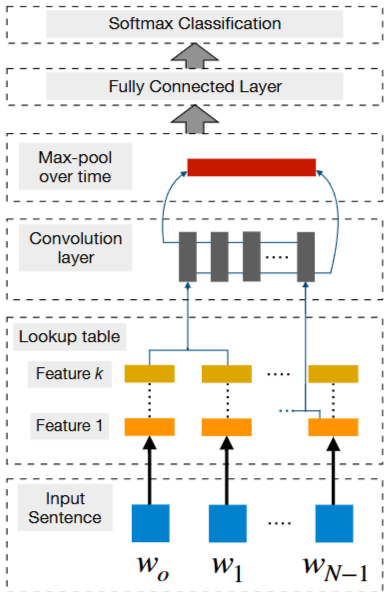 Fig 5. CNN Framework는 단어 단위 클래스를 예측을 수행한다.
Fig 5. CNN Framework는 단어 단위 클래스를 예측을 수행한다.
CNN은 문장의 잠재적인 semantic representation(의미 표현)을 만들어내기 위해 입력 문장으로 부터 핵심적인 n-gram 피처를 추출하는 능력을 갖고 있다.
A. Basic CNN
1) 문장 모델링
문장의 1번째 단어에 해당하는 임베딩 벡터를 Wi, 임베딩 벡터의 차원수를 d라고 하자. n개의 단어로 이루어진 문장이 주어지면 문장은 n x d 크기의 임베딩 행렬로 표현할 수 있다.
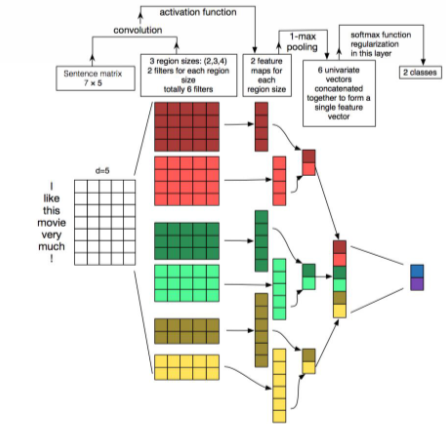 Fig 6. CNN 텍스트 모델링
Fig 6. CNN 텍스트 모델링
CNN은 대부분 맥스풀링 계층을 사용한다. 맥스풀링은 c에 대해 최대값을 취함으로써 입력값을 서브샘플링한다. 이 전략을 쓰는 데는 두 가지 이유가 있다.
-
맥스풀링은 일반적으로 분류에 필요한 고정 길이의 출력을 제공한다.
-
맥스풀링은 전체 문장에서 가장 핵심적인 n-gram 피처를 유지하면서 출력의 차원을 줄인다.
2) 윈도우 접근법
CNN 아키텍처는 완전한 자연어 문장을 벡터로 표현한다. 그러나 개체명인식, 품사태깅, SRL 같은 많은 NLP 문제는 단어 단위의 예측이 필요하다. 이런 태스크에 CNN을 적용하기 위해 윈도우(window) 접근법이 쓰인다.
이는 단어의 범주(tag)가 기본적으로 이웃 단어에 의존할 것이라고 가정한다. 따라서 각 단어에 대해 고정된 크기의 윈도우가 가정되고 윈도우 내에 있는 하위 문장들이 고려된다.
예를 들어
- 문장 = "나는 밥을 먹었다" → 중심 단어 = "밥"
- 윈도우 = ["나는", "밥", "을"]
이 작은 문장(윈도우)을 CNN에 넣어 중앙 단어(여기선 "밥")의 태그를 예측한다.
윈도우 접근법 기반으로 한 CRF, TDNN(Time Delay Neural Network) 기법들이 있다.
B. Applications
NLP 문제에 CNN을 적용한 주요 연구를 소개한다.
간단한 CNN 구조로 감성 분석 등 다양한 문장 분류에서 좋은 성과를 내지만 긴 문장 내 단어 간 관계(장거리 의존성)를 잘 다루지 못한다.
 Fig 7. 7-gram 필터(커널)로 학습된 고빈도 7-gram. 각 필터는 특정 종류의 7-gram에 민감하다.
Fig 7. 7-gram 필터(커널)로 학습된 고빈도 7-gram. 각 필터는 특정 종류의 7-gram에 민감하다.
이를 보완하기 위해 dynamic convolutional neural network(DCNN)기법이 등장했고 이 기법은 dynamic k-max pooling을 제안했다. 필터가 멀리 떨어진 단어 사이 관계도 잡을 수 있게 개선했다.
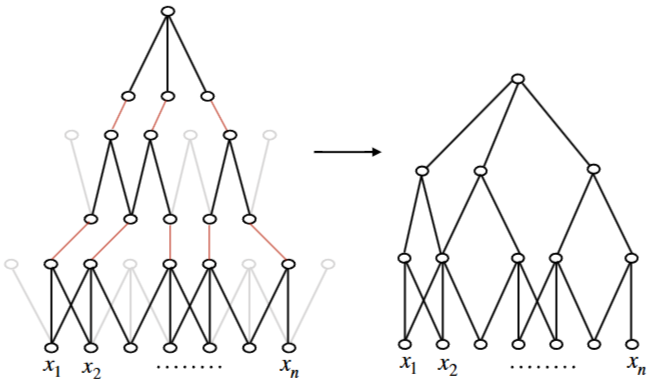 Fig 8. DCNN 서브 그래프
Fig 8. DCNN 서브 그래프
Fig 8에서 상위의 피처는 집중적이고 짧거나, 전역적이고 입력문장처럼 길 수도 있는 매우 가변적인 범위를 가진다.
CNN의 한계점을 정리하면
- CNN은 많은 데이터가 필요하다.
- 멀리 떨어진 단어 관계를 잘 반영 못한다.
- 단어 순서 정보 유지가 어렵다.
CNN은 문맥 단서 포착에 강력하지만 구조적 한계를 보완할 필요가 있어 RNN, Recursive NN 등이 대안으로 사용된다.
RECURRENT NEURAL NETWORKS
