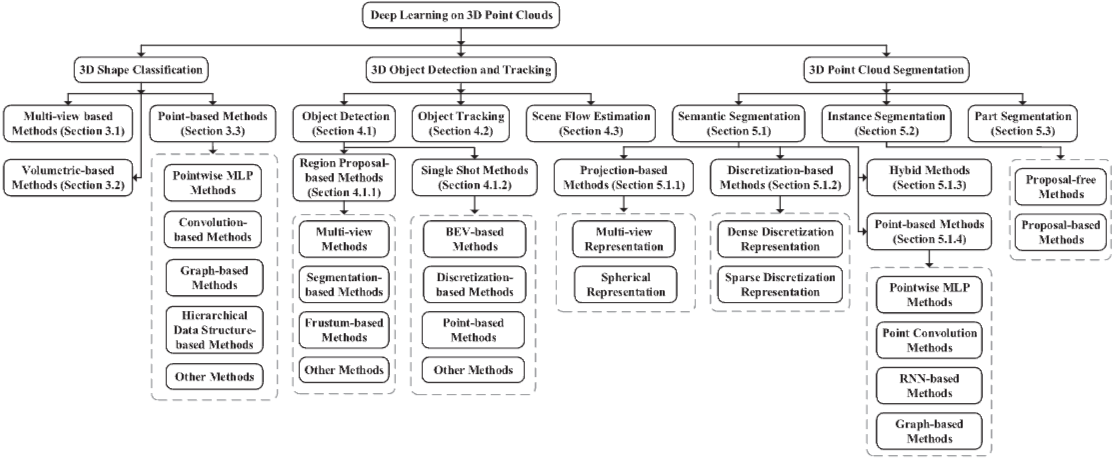
Deep Learning for 3D Point Clouds: A Survey
읽은 날짜: 2025년 10월 20일 ~ 10월 26일
- 논문 PDF
- IEEE 2020
- Key words : Deep learning, point clouds, 3D data, shape classification, shape retrieval, object detection, object tracking, scene flow, instance segmentation, semantic segmentation, part segmentation
Abstract
Point Cloud는 Computer Vision, Autonomous Driving, Robotics 분야에 적용이 되고 있으며 관심이 증가하고 있다.
Point Cloud의 딥러닝은 아직 초기단계이며 다양한 문제들을 직면했지만 최근들어 만은 방법론들이 나오고 있다.
이 논문은 Point Cloud의 세가지 분야인 3D shape classification, 3D object detection and tracking, 3D point cloud segmentation을 중심있게 다룬다.
1. Introduction
3D scanners, LiDARs, and RGB-D cameras를 통해서 3D 센서를 점점 저렴하고 손 쉽게 이용이 가능해졌다. 3D data는 기하학적 모양과 스케일 정보를 제공해준다. 2D 이미지를 보완하여 기계가 주변 정보 환경을 잘 이해할 수 있게 한다.
3D data는 다양한 형태로 나타는데 예를 들어 point clouds, meshes, and volumetric grids가 대표적이다. 그중에서 Point Cloud는 원본 정보를 최대한 보존을 해 정보 손실을 최소화한다. 그러나 3D Point Cloud의 딥러닝을 적용하면 문제점이 있다.
- 작은 데이터셋
- 높은 차원
- 비정형 데이터
3D Dataset을 이용해 여러 문제를 해결하려고 있다.
- 3D shape classification
- 3D object detection and tracking
- 3D point cloud segmentation
- 3D point cloud registration
- 6-DOF pose estimation
- 3D reconstruction
이 논문에서는 3문제(3D shape classification, 3D object detection and tracking, 3D point cloud segmentation)를 다룬다.
2. Background
2.1 Datasets
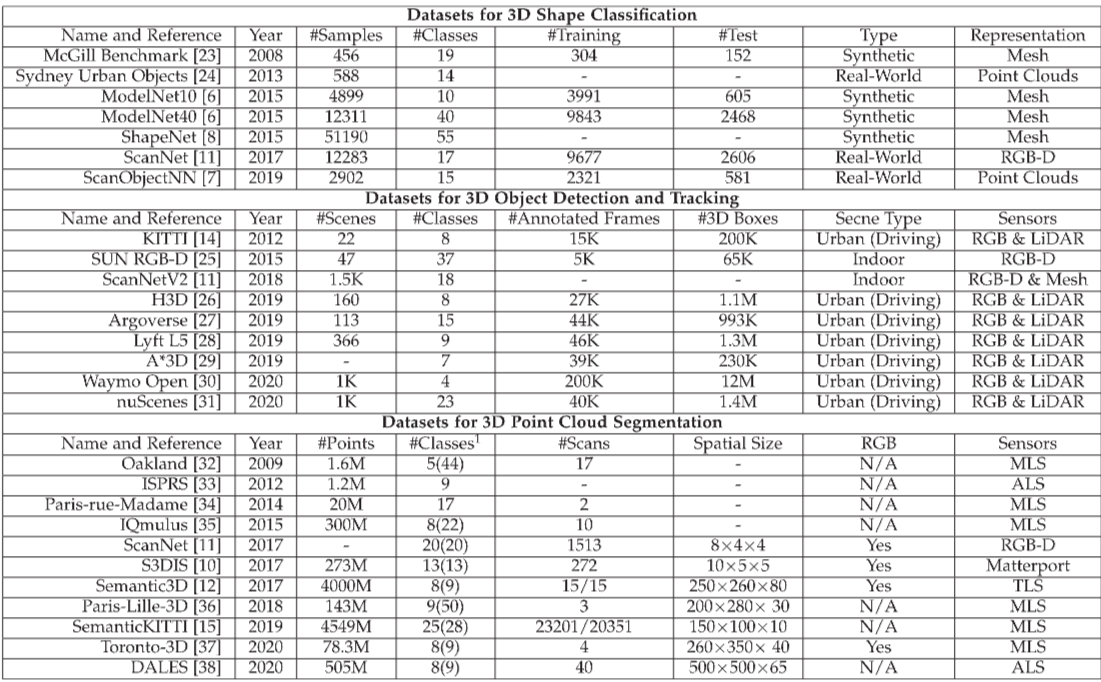 TABLE 1. A Summary of Existing Datasets for 3D Shape Classification, 3D Object Detection and Tracking, and 3D Point Cloud Segmentation
TABLE 1. A Summary of Existing Datasets for 3D Shape Classification, 3D Object Detection and Tracking, and 3D Point Cloud Segmentation
딥러닝 알고리즘을 평가하기 위해 데이터들이 수집이 되었고 Table 1은 이를 정리한 표다.
3D shape classification
- synthetic datasets
- real-world datasets
3D object detectioin and tracking
- indoor scenes
- outdoor scenes
3d point cloud segmentation
위 task의 데이터들은 각기 다른 센서를 이용해서 수집했다.
예를 들어 MLS(Monile Laser Scanners), ALS(Aerial Laser Scanners), TLS(static Terrestrial Laser Scanners), RGB-D cameras, 다른 scanners을 이용했다.
2.2 Evaluation Metrics
각기 다른 task에 평가 지표이다.
3D shape classification
- OA(Overall Accuracy)
- mAcc(mean class accuracy)
3D object detectioin and tracking
- AP(Average Precision) : detection
- AMOTA(Average Multi-Object Tracking Accuracy) : tracking
- AMOTP(Average Multi-Object Tracking Precision) : tracking
3d point cloud segmentation
- OA
- mIoU
- mAcc
- mAP
3. 3D Shape Classification
Classification을 하기 위해 먼저 각 점(point)의 특징을 임베딩(embedding) 형태로 학습을 하기 위해 각 점의 고유한 속성 및 주변 정보가 저차원 벡터로 표현이 된다. 이후 이들을 집계하는 방법을 사용하여 전체 포인트 클라우드를 대표하는 단일의 전역 형상 임베딩(global shape embedding)을 추출한다. 이 과정에서 포인트 클라우드의 무작위적인 특성을 처리하고 전체 형상을 특징 짓는다. 추출된 전역 형상 임베딩을 여러 개의 Fully Connected Layers 즉 MLPs로 구성된 분류기에 입력하여 최종 3D 형상 분류 결과를 얻게 된다.
3D Shape Classification 방법으로는 크게 3가지로 나뉜다.
- Multi-view based : 비정형 point cloud를 2D 이미지로 투영하는 방법
- Volumetric-based : point cloud를 3D 복셀화로 변환
- point-based : 원시 데이터를 활용해서 정보 손실을 발생시키지 않음
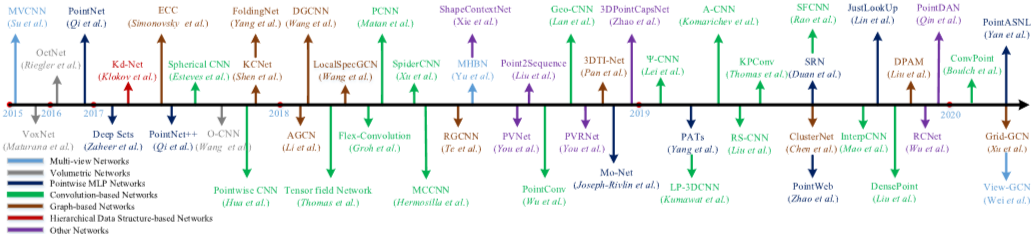 Fig 2. Chronological overview of the most relevant deep learning-based 3D shape classification methods.
Fig 2. Chronological overview of the most relevant deep learning-based 3D shape classification methods.
Fig 2는 여러 주요 방법들을 정리한 이미지다.
3.1 Multi-view based
이 방법은 먼저 3D 형상을 여러 view로 투영(2D 이미지로 변환)하고 각 view 별 특징을 CNN 기법을 사용하여 추출한 다음 정확한 형상 분류를 위해 이러한 특징들을 융합한다.
이 방법의 핵심은 여러 뷰(Multi-view)에서 추출된 특징들을 어떻게 효과적으로 통합하여 판별력 있는 전역 표현을 만들어 내는지다.
3.1.1 MVCNN
MVCNN는 여러 뷰의 특징들을 Max-pooling 하여 전역 벡터를 생성한다. 그러나 Max-pooling은 특정 뷰에서 가장 큰 요소만을 유지하므로 정보 손실이 발생할 수 있다는 한계가 있다.
3.1.2 MHBN
MHBN은 지역 컨볼루션 특징을 harmonized bilinear pooling 방식으로 통합하여 더욱 압축적이고 판별력 있는 전역 벡터를 만들었다.
3.1.3 Inter-relationship
관계 네트워크(relation network)를 도입하여 view들 간의 상호 관계를 탐색하고 더욱 판별력 있는 3D 객체 표현을 얻는다
3.1.4 View-GCN
Multi-view를 그래프의 노드로 간주하여 방향성 그래프(directed graph)를 구성한다. 이 그래프에 지역 그래프 커ㄴ볼루션, 비지역 메시지 전달, 선택적 뷰 샘플링을 포함하는 핵심 계층을 적용하여 전역 형상 벡터를 생성했다.
3.2 Volumetric-Based Methods
Volumetric-Based Methods은 일반적으로 point cloud를 3D grid로 복셀화(3차원 데이터를 복셀 형태로 변환)한다. 즉 3D 공간을 작은 정육면체(복셀)들로 나누고 각 복셀이 point cloud의 점들이 포함하는지 여부 또는 점들의 특정 속성을 인코딩한다. 이렇게 생성된 volumetric representation에 표준 3D CNN을 적용하여 형상 분류와 같은 작업을 수행한다.
3.2.1 VoxNet
3D 객체 인식을 위한 복셀 기반 점유 네트워크 방법이다.
3.2.2 ShapeNets
복셀 그리드에 있는 이진 변수의 확률 분포로 3D 형상을 표현하는 방법이다.
위 두 방법들은 고해상도 3D 데이터에 대해 계산 및 메모리 비용이 해상도의 세제곱에 비례하여 증가하는 문제로 확장성이 좋지 않았다. 그래서 이러한 한계를 극복하기 위해 octree와 같은 계층적이고 압축적인 데이터 구조가 도입되어서 OctNet, Octree-based CNN, PointGrid, 3DmFV와 같은 방법론들이 등장했다.
3.3 Point-Based Methods
이 방법들은 point cloud를 원시(raw) point cloud 데이터에 직접 CNN에 적용하기 때문에 정보 손실을 줄일 수 있다.
- pointwise MLP
- convolution-based
- graph-based
- hierarchical data structure-based methods
- other typical methods
3.3.1 Pointwise MLP Methods
전형적인 DL 모델에는 3D Data의 불규칙성 때문에 적용할 수 없다.
PointNet 방법론은 point cloud를 원본 데이터를 사용하고 대칭함수를 통해 점들의 순서가 바뀌어도 동일한 결과(순열 불변성을)를 출력하도록 한 첫 번쨰 연구이다. PointNet은 각 점의 특징을 MLP(Multi-layer Perceptrons)를 통해 독립적으로 학습한다. 그 후 이 점들의 특징들을 모아서(aggregate) 전체 Point clouds를 대표하는 하나의 전역(global) 특징을 만든다. 이때 max-pooling layer를 사용하여 전역 특징을 만들기 때문에 점들의 순서가 바뀌어도 큰 값은 동일하게 선택되므로 최종 출력값은 변하지 않는다. 그러나 이 방법은 지역 정보를 반영하지 못한다.
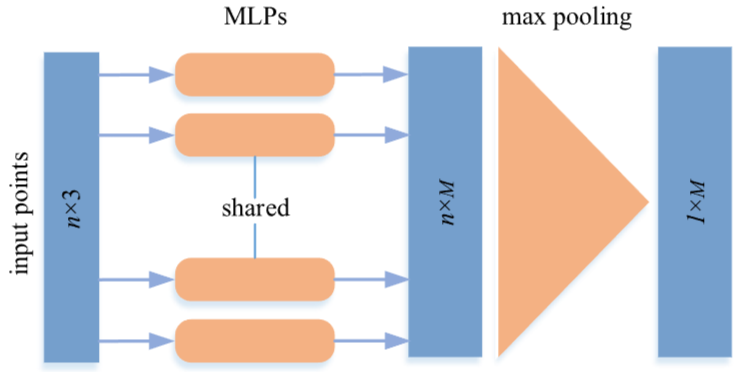 Fig 3. A lightweight architecture of PointNet. n denotes the number of input points, M denotes the dimension of the learned features for each point.
Fig 3. A lightweight architecture of PointNet. n denotes the number of input points, M denotes the dimension of the learned features for each point.
그래서 PointNet++ 방법론이 등장했다. 이 방법론은 점들 사이의 지역적인 구조 정보를 파악하기 위해 계층적인 구조를 도입했다. set abstraction level은 점 집합을 추상화하는 역할을 하며 Sampling Layer, Grouping Layer, PointNet based Learning Layer 층으로 구성이 되어 있다.
이후에 등장한 방법론들도 PointNet의 기반을 두고 있다.
3.3.2
