[Paper] [Page] [Github]
SAM 3D Team, Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li⚬, Aohan Lin, Jia-Wei Liu, Ziqi Ma⚬, Anushka Sagar, Bowen Song⚬, Xiaodong Wang, Jianing Yang⚬, Bowen Zhang⚬, Piotr Dollár, Georgia Gkioxari, Matt Feiszli, Jitendra Malik
Meta Superintelligence Labs
19 Nov 2025
1. Introduction
 Figure 1. SAM 3D converts a single image into a composable 3D scene made of individual objects.
Figure 1. SAM 3D converts a single image into a composable 3D scene made of individual objects.
SAM 3D 논문은 Fig 1을 보는것과 같이 신경망을 활용하여 단일 이미지로부터 3D 데이터로 재구성하는 논문이다. 인간은 객체에 단일 이미지로부터 깊이와 형태를 인지할 수 있다는 사실을 기반으로 시작했다. 인간은 새롭게 본 객체도 일반화를 할 수 있는데 그 이유는 이전에 보지 못한 객체들이더라도 이전에 본 객체들로 구성이 되어 있기 때문이다.
3D 모델을 학습하는 데 있어서 데이터가 부족하다는 근본적인 어려움이 존재한다. 기존에 학습된 모델은 하나의 객체에서 하나의 3D 데이터를 매치 시켜서 학습했지만 SAM 3D는 이러한 어려움을 다음과 같이 해결하려고 했다.
- 3D 객체 모델을 렌더링하고 이미지에 붙여넣는 합성 장면을 만들 수 있다. (Synthetic pretrainning 방법)
- 인간은 객체에 대한 3D 형태 모델을 쉽게 생성할 수 없지만 제공된 선택 항목 세트에서 가장 적합한 3D 모델을 선택하고 해당 포즈를 이미지에 맞출 수 있다. (Model-in-the-loop 방식)
 Figure 3. SAM 3D data
Figure 3. SAM 3D data
SAM 3D 모델은 LLM의 학습 단계를 모방해서 학습을 진행했다.
- 먼저 렌더링된 합성 객체의 대규모 데이터(텍스처, 어휘 등)를 지도학습한다.
- 렌더링된 모델을 이미지에 붙여넣어 생성된 준 합성 데이터를 사용해서 중간 학습한다.
- 사후 학습은 새로운 MITL(Model-in-the-loop) 파이프라인과 인간 3D 아티스트를 모두 사용하여 모델을 실제 이미지에 적용하고 인간 선호도에 맞춘다.
이러한 과정을 통해 합성사진을 통한 사전 학습은 이미지에 대한 적절한 사후 학습이 주어지면 일반화된다는 것을 발견했다.
일반적인 인간이 직접 다는 주석은 3D 데이터의 ground truth를 생성할 수 없으므로 인간은 초기 3D 데이터의 형상을 여러게 제안 받은 후 이미지의 객체에 대한 3D 모델을 선택하고 정렬한다.
또한 3D 데이터의 벤치마크가 부족하여 1,000개의 이미지 및 3D 쌍으로 구성된 새로운 벤치마크인 SAM 3D Artist Objects(SA-3DAO)도 제안한다.
이 논문의 기여는 다음과 같다.
- SAM 3D 모델
- MITL 파이프라인을 구축하여 3D 데이터를 재구성한다.
- LLM 스타일의 사전 학습 및 사후 학습을 통해 도메인 간의 데이터 격차를 극복하기 위해 합성 사전 학습과 실제 정렬을 결합한다.
- 새로운 벤치마크인 SA-3DAO를 공개한다.
2. The SAM 3D Model
2.1 Problem Formulation
사진을 찍는 행위는 3D 객체를 2D 픽셀들의 집합으로 변환하는 작업이다. 따라서 이 방법을 역으로 이용한다.
- 입력
- I : 전체 이미지
- M : 이미지 내에서 특정 개체를 지정하는 마스크
- 출력
- S : 객체의 3D 형상 (shape)
- T : 객체의 텍스처 (Texture)
- R, t, s : 카메라 좌표계 기준의 레이아웃 정보 (회전, 이동, 스케일)
즉 생성 모델인 q를 정답인 p에 가깝게 만드는 것이 목표다.
2.2 Architecture
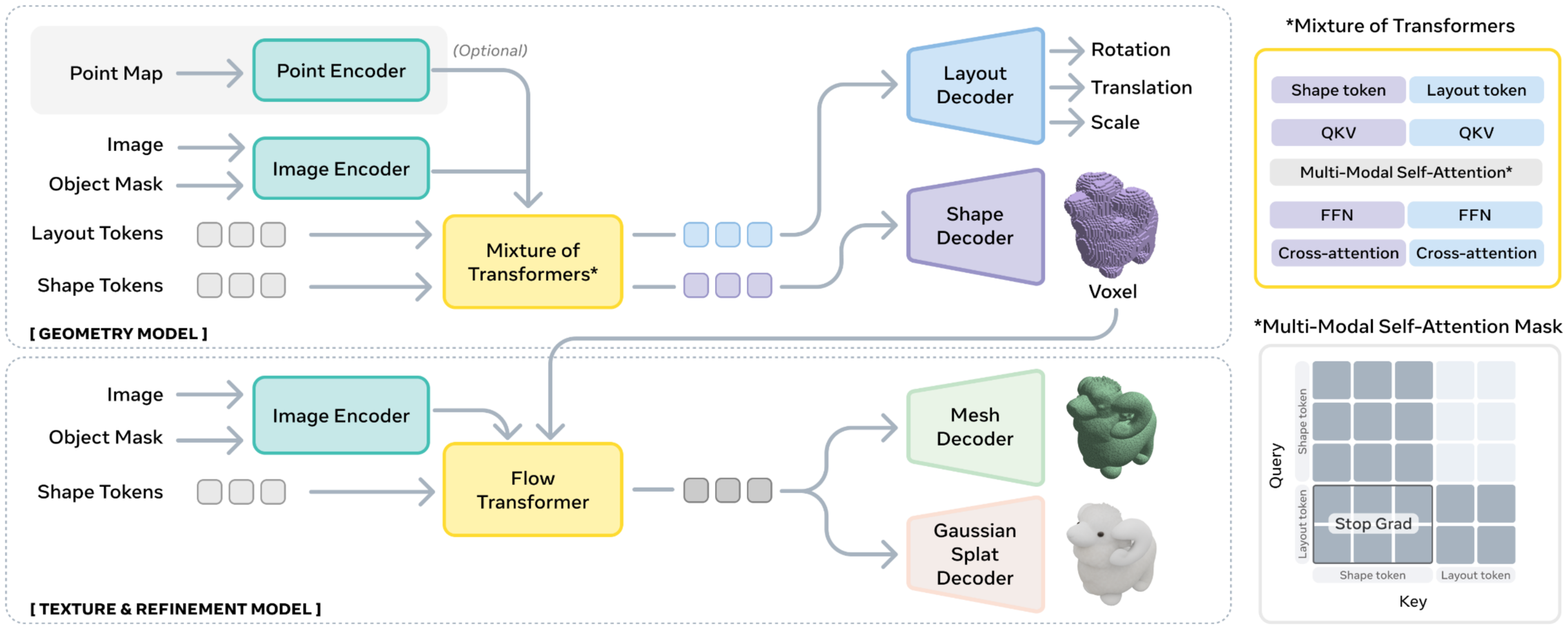
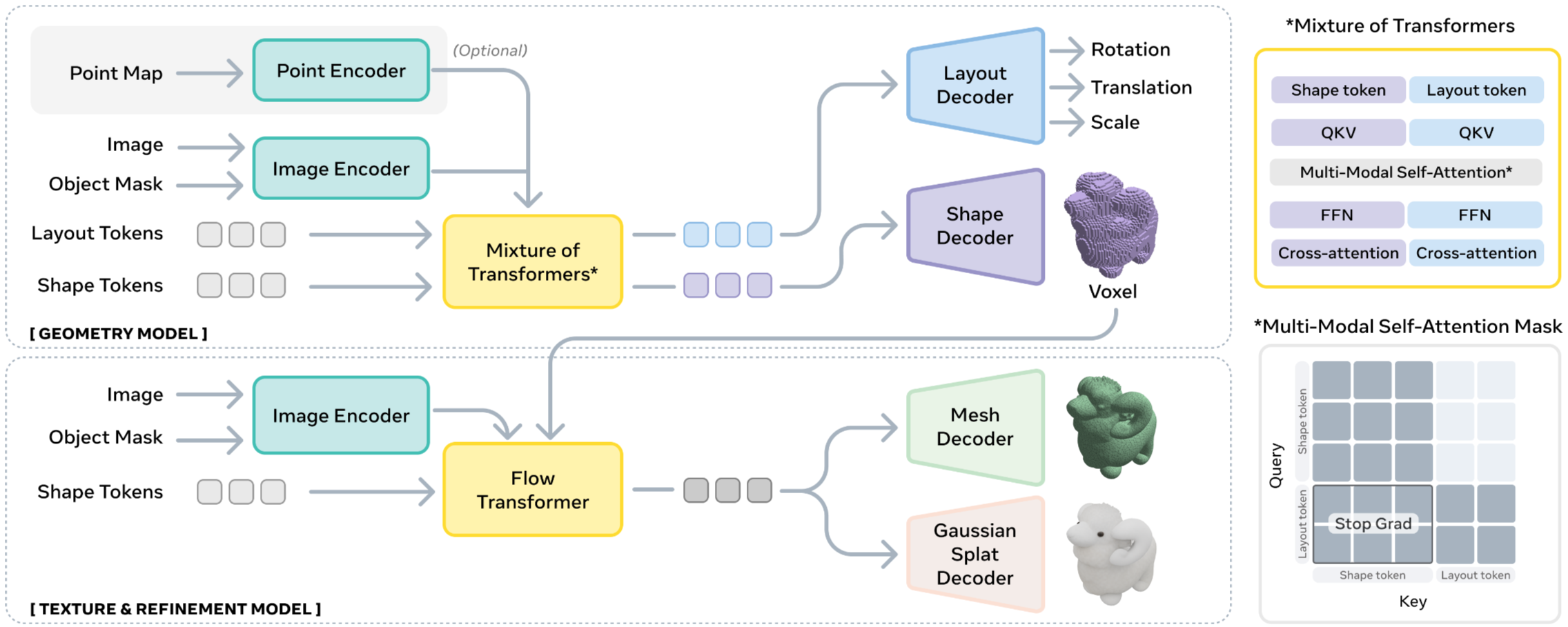 Figure 2.SAM 3D architecture.
Figure 2.SAM 3D architecture.
SAM 3D는 최근 SOTA 기술인 2단계 잠재 흐름 매칭(two-stage latent flow matching) 아키텍처 기반으로 설계를 했다. SAM 3D의 전체적인 과정은 객체의 포즈(pose)와 거친 형상(coarse shape)를 공동으로 예측을 한 다음에 모양(shape)을 개선하는 방식이다.
- Input Encoding
DINOv2 인코더를 사용하여 2쌍의 이미지 특징을 추출하여 총 4세트의 조건부 토큰(conditioning tokens)를 생성한다.
-
Cropped object(2) : 마스크 영역을 크롭한 이미지와 이진 마스크를 인코딩하여 객체에 집중된 고해상도 정보를 제공
-
Full image(2) : 전체 이미지와 전체 마스크를 인코딩하여 크롭된 뷰에는 없는 전역적인 장면 맥락과 인식 단서를 제공
선택적으로 포인트 맵(Point Map)을 조건으로 추가하여 외부 파이프라인과 통합할 수 있다.
- The Geometry Model
입력 이미지와 마스크 인코딩을 조건으로 받아 거친 형상(O)과 카메라 좌표계의 기준의 레이아웃 (R,t,s)를 예측한다. 12억(1.2B) 개의 파라미터를 가진 Flow Transformer로 MoT(Mixture-of-Transformers) 아키텍처를 사용한다.
- The Texture & Refinement Model
Geometry Model에서 거친 형상(O)를 예측 한 뒤 활성 복셀(Active Voxels)을 추출한 뒤 이를 바탕으로 기하학적 디테일을 정제하고 객체의 텍스처(T)를 합성한다.
- 3D Decoders
Texture & Refinement Model에서 나온 잠재 표현(Latent Representatioins)은 별도로 훈련된 VAE 디코더를 통해 메쉬(Mesh) 또는 3D Gaussian Splats 형태로 출력된다.
3. Training SAM 3D
SAM 3D 학습 방법
- Step 1: Pretraining
합성된 3D 객체 데이터셋을 사용하여 모델에 객체 형상 및 텍스처 사전 지식을 학습시킨다. - Step 1.5: Mid-Training
가려짐(occlusion)의 강건성, 마스크 추종(mask-following), 시각적 단서 등을 일반적인 기술을 학습시킨다. - Step 2: Post-Training
모델을 실제 데이터에 맞춰 정렬하고 MITL 파이프라인과 3D 아티스트의 수동 보정을 통해 실제 세계 데이터를 수집하고 이를 사용하여 모델을 미세 조정하고 최적화한다.
Step 2는 반복될 수 있으며 현재 모델에서 새로운 데이터를 통해 모델을 개선할 수 있다.
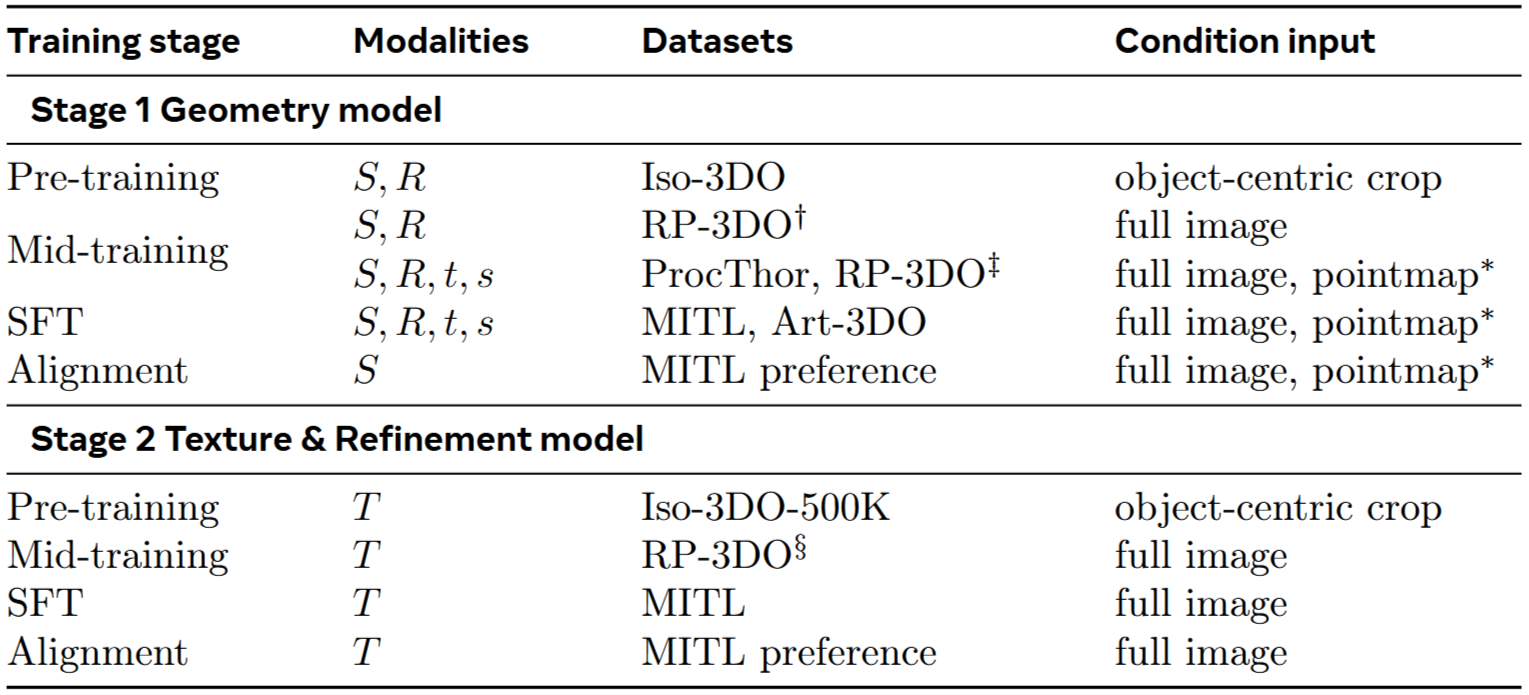 Table 1 SAM 3D training stage.
Table 1 SAM 3D training stage.
5. Related Work
3D reconstruction
- 고전적 방법
: 여러 장의 이미지를 이용해서 기하학적 구조를 계산하는 방법- 양안 시차(Binocular stereopsis)
- Structure-from-Motion (SfM)
- SLAM
- Deep Learning 방법
- 복셀(Voxel)
- 포인트 클라우드(point cloud)
- 메쉬(Mesh)
- NeRF
- Gaussian Splatting
위 방법과는 다르게 SAM 3D는 단일 이미지 한장만으로 3D를 재구성한다.
Single-view 3D Reconstruction
- 3D supervision 방법
- 복셀(Voxel)
- 포인트 클라우드(point cloud)
- 메쉬(Mesh)
- CAD 정렬 지오메트리(CAD-aligned geomety)
- 잠재 공간 기반 (Latent-based)
- VAE의 잠재 공간
기존 모델들은 주로 ShapeNet, Pix3D, Objaverse과 같은 단순화된 합성 데이터셋에서만 평가되었다. 배경이 하얗고 물체가 중앙에 있는 쉬운 데이터에만 최적화되어 있어 복잡한 실제 환경에서는 성능이 떨어진다.
Layout estimation
물체의 3D 형상뿐만 아니라 카메라 공간 상에서의 위치와 자세(Pose)를 추정하는 연구들은 특정 환경에 국한된 연구가 많다. SAM 3D는 특정 환경(실내/실외)이나 평면 가정에 얽매이지 않고 광범위한 객체 타입과 다양한 장면에서 포즈를 추정할 수 있다.
3D datasets
-
합성 데이터: ShapeNet, Objaverse-XL 등은 규모는 크지만 실제 사진이 아닌 렌더링 된 이미지이므로 현실과의 괴리(Domain gap)가 크다.
-
실제 데이터 (Real-world): ScanNet, ARIA Digital Twin 등 실제 환경 데이터셋이 존재하지만 대부분 실내(Indoor) 가구 위주이며 규모가 작다.
이러한 데이터로 학습된 모델들은 일반화 능력이 떨어져 처음 보는 이미지에서는 잘 작동하지 않는다.
Post-training
SAM 3D는 self-training을 사용하여 합성 데이터와 실제 데이터의 격차를 해소하고 RAFT와 가장 유사하지만 preference tuning도 통합한다.
Multi-stage pretraining
처음에는 쉬운 대규모 데이터로 기초를 다지고 나중에 고품질 데이터를 섞거나(Curriculum learning), 고품질 데이터를 나중에 제공하는 것이 최근 LLM 학습의 추세이다.
6. Conclusion
새로운 이미지에서 객체의 3D 모양, 텍스처 및 레이아웃을 재구성하기 위한 새로운 SAM 3D 모델을 소개한다. SAM 3D가 로보틱스, AR/VR, 게임, 영화 등과 같은 다양한 분야에서 새로운 기능을 제공할 것으로 기대한다.
