[Paper] [Page] [Github]
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng
ECCV 2020
기존 3D 표현 방식은 "Explicit Representation"인 공간 데이터를 직접적으로 저장하는 방법을 많이 사용했다. 예를 들어 Mesh, Point Cloud, Voxel Grid 등이 있다.
 Fig 1. 3D Data representation
Fig 1. 3D Data representation
그러나 이런 표현 방식은 복잡한 scene 표현에 어려움이 있고 메모리 문제가 발생하는 단점이 있다. 그래서 NeRF는 이러한 단점을 극복하기 위해 Explicit Representation이 아닌 Implicit Representatioin 방법을 사용하여 직접 저장하지 않고 함수로 표현을 통해 memory 문제를 해결하려고 했다.
다만 Explicit Representation 방법은 이산적이라 편집이 쉬운데 반해 Implicit Representation은 연속적이라 편집이 어려운 단점이 있다.
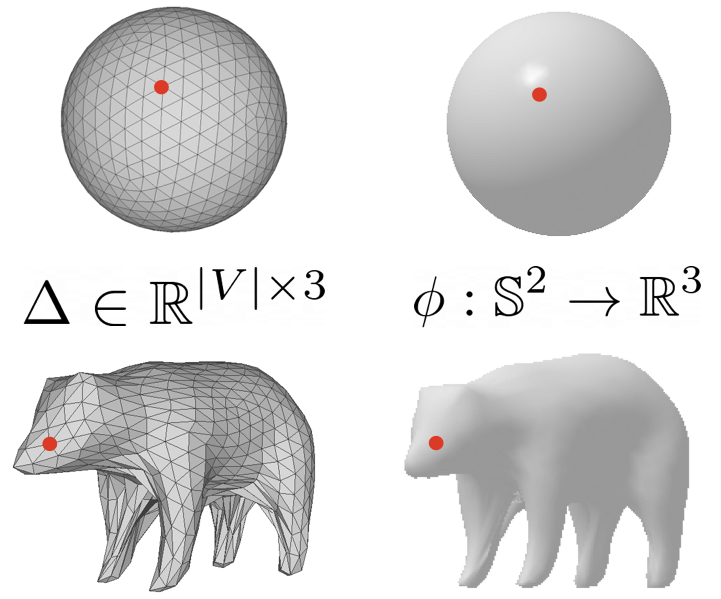 Fig 2. Mesh Parametrization
Fig 2. Mesh Parametrization
| Explicit | Implicit | |
|---|---|---|
| 표현 방식 | geometry 직접 저장 | 함수로 표현 |
| 구조 | 실제 좌표 데이터 | Function |
| 공간 표현 | discrete | continuous |
| 메모리 | 큼 | 작음 |
| Geometry 접근 | 쉬움 | 어려움 |
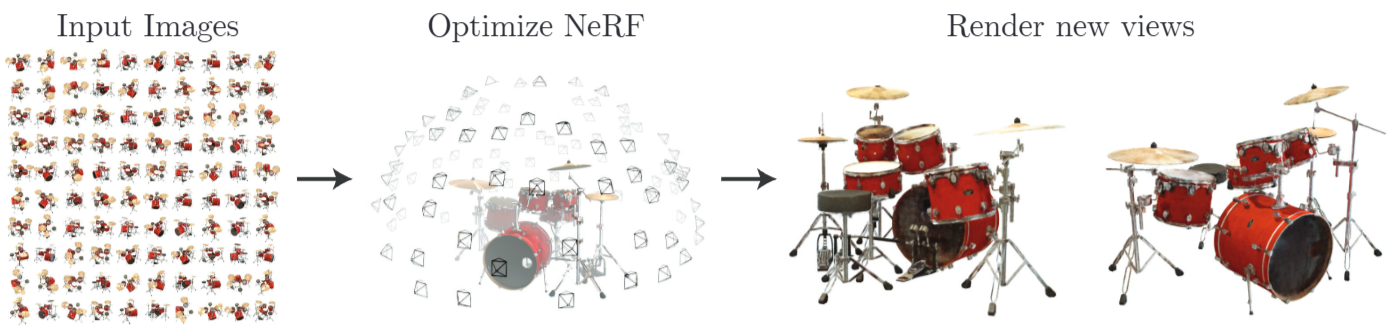 Fig 3. NeRF representation
Fig 3. NeRF representation
본 논문은 정적인 장면(image)과 카메라 위치 장면을 활용하여 촬영되지 않은 새로운 시점의 이미지를 사실적으로 합성하는 방법(Novel View Synthesis)를 제시한다. 위 논문의 제목처럼 Neural Radiance Fields 이름의 유래를 살펴보겠다.
- Neural : 합성곱(CNN)이 없는 다중 퍼셉트론(MLP)로 이루어져 있다
- Radiance : 컴퓨터 그래픽스에서 특정 표면의 점에서 특정 방향으로 나가는 빛의 색과 세기(밀도)를 뜻하며 논문에서는 이를 특정 위치에서 보는 방향에 따라 달라지는 RGB 색상을 의미한다. 즉 위치와 방향에 따라 어떤 색상의 빛이 나오는지를 다루는 것
- Field : 공간 전체의 연속적 위치에서 정의 되었다는 의미이다. 즉 좌표와 방향을 준다면 언제든 그 위치의 상태(밀도, 색상)를 뽑아내는 연속적인 공간이라는 것
쉽게 말해 Neural Radiance Fields는 3D 공간 상의 모든 연속적인 점(Fields)에서 뿜어져 나오는 빛의 색상과 밀도(Radiance)를 인공지능(Neural Network)이 학습하여 기억하고 있는 가상의 공간이다.
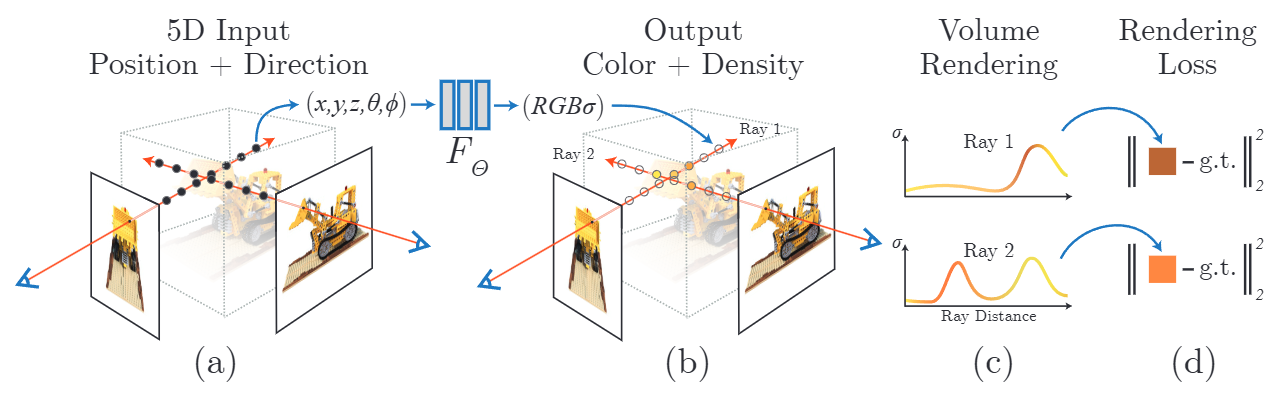
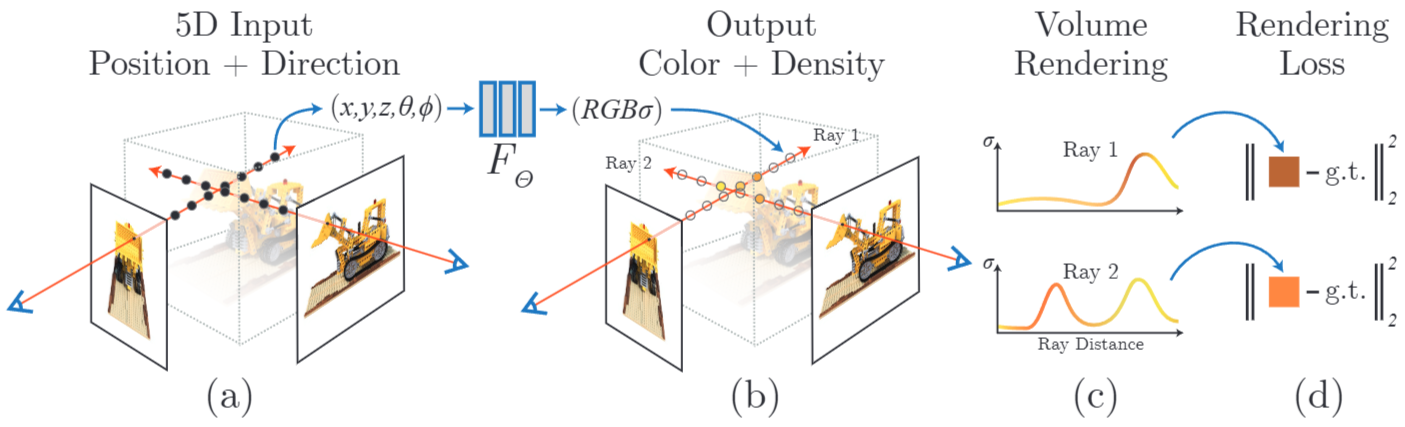 Fig 4. An overview of our neural radiance field scene representation and differentiable rendering procedure
Fig 4. An overview of our neural radiance field scene representation and differentiable rendering procedure
Fig 4를 각 단계 파이프라인으로 살펴보겠다.
(a) 5D Input
3D 공간 상의 특정 점 좌표값인 (x, y, z) 와 그 점을 쳐다보는 광선(Ray)의 방향 (θ, φ) 을 Input으로 넣는다. 이때 이미지는 (x, y, z) 위치를 카메라 포즈 값은 (θ, φ) 방향을 결정한다.
(b) Output
Input 값을 MLP에 넣어 학습을 진행한다. 각 포인트의 RGB 값과 밀도를 예측한다.
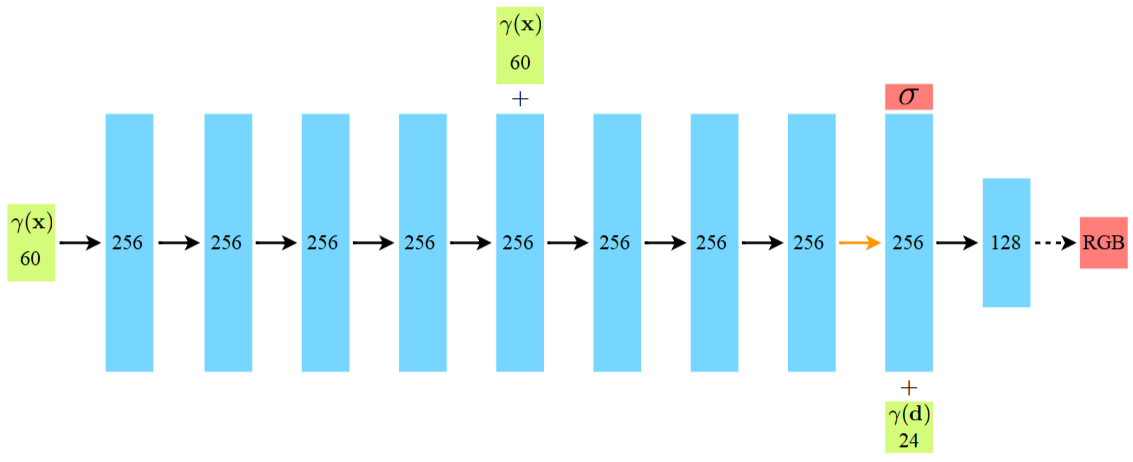 Fig 5. A visualization of our fully-connected network architecture
Fig 5. A visualization of our fully-connected network architecture
Fig 5를 보면 처음 Input은 위치 정보 (x, y, z)로 넣고 밀도를 예측해 밀도(𝜎)를 출력한다. 물체의 밀도는 각도와 상관없이 동일해야 하기 때문에 처음 8개의 FC 레이어에서는 위치 정보인 (x, y, z)로만 학습이 이루어진다. 도중에 5번째 레이어에서 Skip-connection이 발생한다. 9번째 레이어에서 방향 정보 (θ, φ)이 추가 입력되면서 최종으로 RGB 값이 출력된다. RGB값은 물체를 보는 방향에 따라 달라지기 때문에 방향 값이 필요하다.
여기서 입력 차원을 늘린 이유는 MLP가 low-frequency 정보에 편향되는 것을 방지하기 위해 60차원으로 늘렸다. 이를 Poisitional Encoding이라고 한다.
 Fig 6. Ablation study
Fig 6. Ablation study
위 그림처럼 Poisitional Encoding의 유무에 따라 결과값이 달라지는 것을 알 수 있다.
(c) + (d) : Volume Rendering + Loss
NeRF 모델에서는 MLP에서 얻은 Ray 내 점들의 RGB 값과 밀도 값을 결합하여 하나의 픽셀로 변환한다. 이렇게 렌더링 된 RGB 값은 실제 이미지의 RGB 값과 비교되어 MSE Loss를 통해 최적화된다.
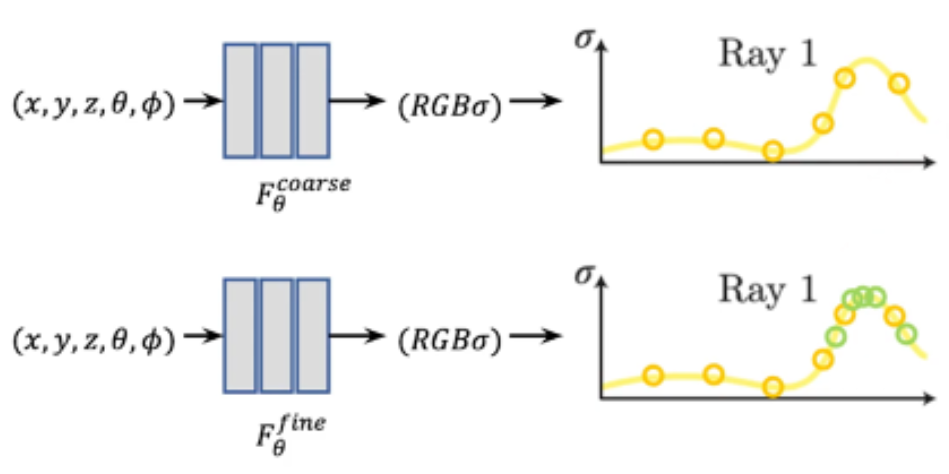 Fig 6. Sampling 과정
Fig 6. Sampling 과정
Ray에는 수많은 점들이 있기 때문에 모든 점들을 학습하기 보다는 sampling을 진행한다. sampling 방법에는 deterministic sampling, stratified sampling 방법이 있는데 이 논문에서는 stratified sampling을 사용했다. 각 구간을 일정하게 sampling을 하게 되면 편향이 생길 수 있으므로 구간을 나눠 구간마다 sampling을 진행하였다. 이 sampling을 통해 64개의 점을 sample(Coarse) 했다. 이후에는 밀도가 높은 구간을 중심으로 다시 sampling을 진행(Fine)해서 총 192개의 Sampling을 진행한다.
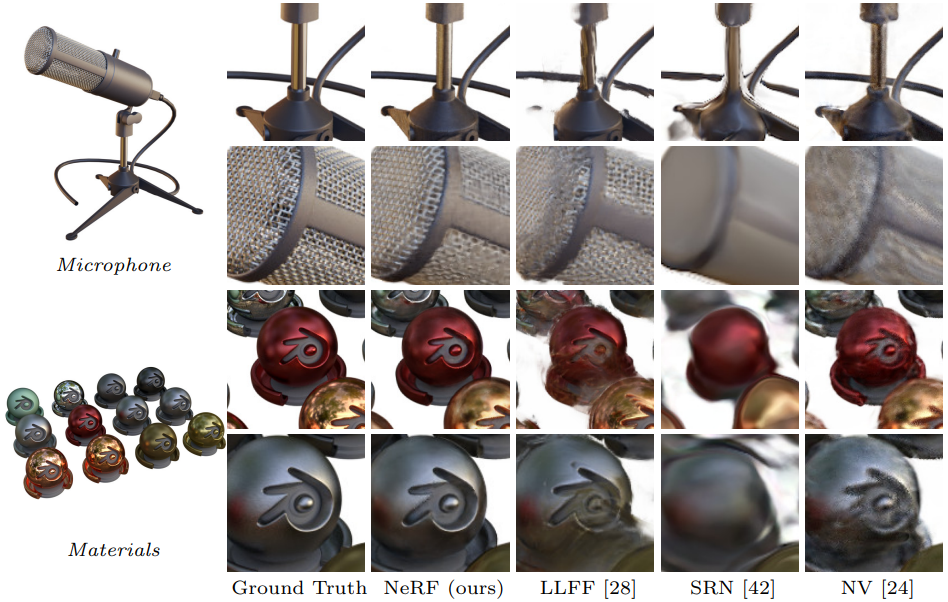


위 이미지는 실험 결과를 기존 방법들과 이미지 비교를 했다.
출처
