머신러닝 day1 & 통계야 놀자 첫 세션
Today Goal
✅ 파이썬 300제 241~260까지 풀기 & 오답⭕
✅ SQL 코드카타 1문제풀기 & 오답⭕
✅ 파이썬 코드카타 1문제 풀기 & 오답⭕
✅ 파이썬 basic 4주차 복습하고 정리하기⭕
✅소현 튜터님 기초통계 수업듣고 바로 복습하기 ⭕
✅머신 러닝 기초 (선형회귀까지 듣기)
✅책 30분씩 읽기⭕
Today I Learn
💡SQL
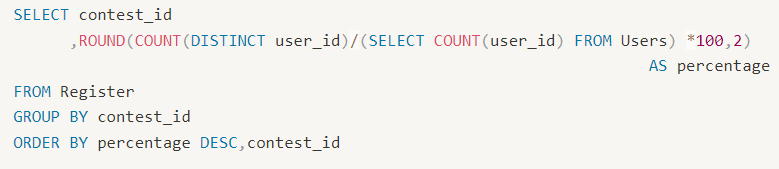
✔94번 1633. Percentage of Users Attended a Contest
✅ 처음 쓴 코드

✅ 오답 코드

💡Python 300제
✔ 풀어보는 정도로만 봄.
💡Python 코드카타
✔21번 하샤드의 수
✅ 오답노트 쿼리문

💡파이썬 Basic 라이브 세션
✅ 4주차
✔기본 그래프 그리기
- 데이터분석가에게 시각화란?
- 데이터 분석 결과를 시각적으로 표현하고 의사소통 하는 것
- 데이터 시각화는 '전략'으로 인식, 사용자의 흥미 유발이 가능
#기본 그래프 그리기
df2.groupby('Gender')['customer ID'].count().plot.bar()
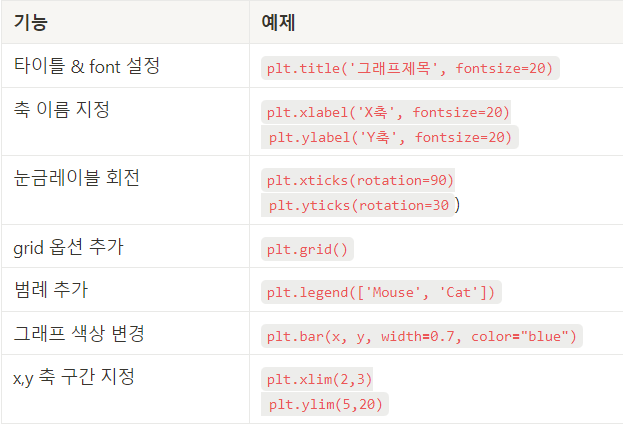
df2.groupby('Gender')['customer ID'].count().plot.bar(color = ['yellow','purple'])✔Matplotlib의 다양한 옵션을 살펴봅시다!
- 주요 지원 옵션
💡기초 통계 라이브 세션
✅1주차
✔ 다양한 데이터의 종류 이해
- 데이터에 분석에 사용되는 통계
- 데이터의 종류를 왜 분류해야하나?
- 데이터의 생김새에 따라 시각화, 해석, 통계모델 결정에 중요한 역할을 하기때문
- 데이터의 종류 정보를 곧 변수로 인식하고, 종류에 따라 해당 변수에 관련된 계산을 어떠한 식으로 수행할지 결정
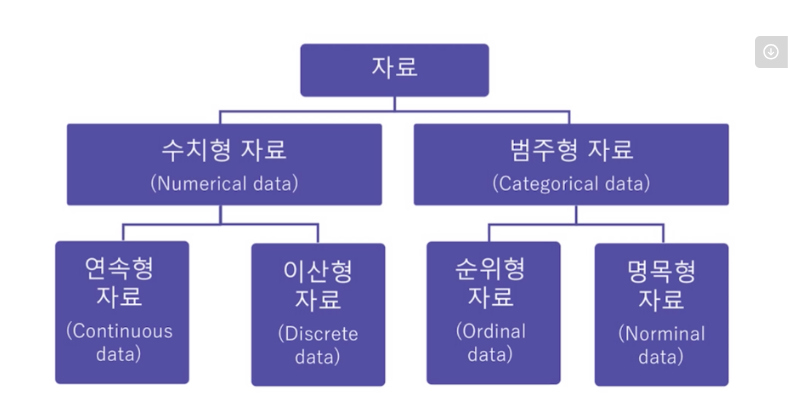
- 수치형 - 숫자를 이용해 표현할 수 있는 데이터 (체중,신장,사고건수, 일방문자수)
- 이산형, 연속형을 모두 포함한 개념
- 범주형 - 가능한 범주 안의 값만을 취하는 데이터 (나라,도시,혈액형,성공여부, 등수,MBTI)
- 값이 달라집에 따라 좋거나 나쁘다고 할 수 없는 데이터
- 명목형
- 이진형, 순서형을 모두 포함하는 개념
✔ 편차, 분산, 표준편자 표본분포의 이해
- 평균으로 EDA했다는 의미
- 데이블이 주어졌을때, 이를 살펴보는 가장 기초적인 단계는 각 컬럼의 ‘대표값’을 구하는 것임. 대표값은 평균, 중앙값, 최빈값이 될수 있음.
- 평균: 모든 값의 총 합을 개수로 나눈 값
- 중간값: 데이터 중 가운데 위치한 값
- 최빈값: 데이터 중 가장 많이 도출된 값
- 편차 : 평균으로부터 얼마나 떨어져 잇느지를 의미
- 분산 : 편차의 합이 0으로 나오는 것을 방지하기 위해서 생성된 개념 = 편차 제곱합의 평균
- 표본 분포 : 표본의 분호. 표본이 흩어져 있는정도
- 중심극한정리 중요! : 표본 크기가 충분히 크다면 어떤 분포에서도 표본 평균이 정규분포를 따른다는 것을 의미
[= 표본이 많아질수록 평균 주변에서 값으로 모인다.
= 표본들을 뽑아서 평균내어 모은게 정규뷴포 모양을 띄는것
= 많은 독립적인 확률변수가 모이면, 그 합이나 평균이 정규분포에 가까워진다는 원리.
= 다양한 분포를 가진 데이터라도 샘플 수가 많아지면 전체 분포가 종 모양의 곡선(정규분포)에 근접함.]
- 표준오차 : 표본의 표준편차
✔정규분포, 신뢰구간
- 신뢰구간: 특정 범위 내에 값이 존재할것으로 예측되는 영역
(영어점수가 10점에서 90점 사이일 것 같아요) - 신뢰수준: 실제 모수를 추정하는데 몇 퍼센트의 확률로 신뢰구간이 실제 모수를 포함하게 되는 확률. 주로 95%와 99% 를 이용합니다.
(영어점수가 10점에서 90점 사이일에 분포할 확률이 95% 같아요)
** 인강이 들어오면 다시 정리하기로.
💡머신 러닝
✔
How was it?
✔ 기초 통계가 잘 안들어와서, 책을 빌려서 읽고 있지만, 익숙하지 않은 분야여서 그런지 이해가 가지 않은다. 그래도.. 강의와 책을 여러번 듣다보면 익숙해지지 않을까 생각이 든다.
✔ 내가 체력이 지금 떨어져서 계속 졸린건가? 지금 이건 어떻게 해야 할꺼 같다.
✔하루하루 좀 더 계획을 세우고 고민해서 하루를 보내야겟다.
