심화 프로젝트 day2
<단어 정리 >
-
사이킷 런
- Python을 대표하는 머신러닝 라이브러리.
- 자신이 하고 싶은 분석 (분류/회귀/클러스터링 등)이 있음.
-
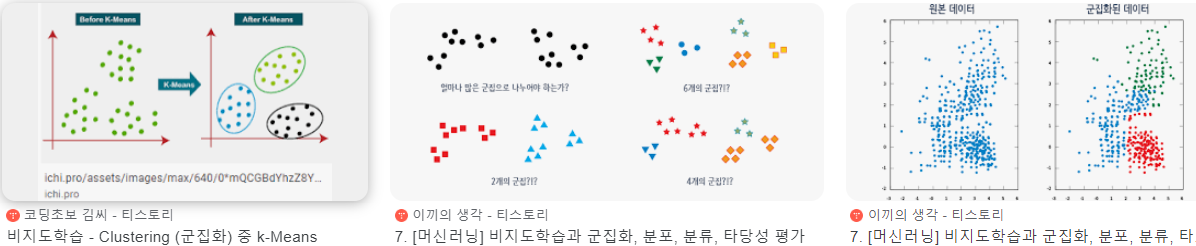
군집합 (클러스터 분석):
- 개체들을 비슷한 것끼리 그룹을 나누는 것을 말함.
- 주어진 데이터들의 특성을 고려해 데이터 집단을 정의하고 데이터 집단의 대표할 수 있는 대표점을 찾는 것으로 데이터 마이닝의 한 방법이다.
- 클러스터란 비슷한 특성을 가진 데이터들의 집단이다.
-
PCA (주성분분석)
-여러 개의 방응변수로 얻어진 다변량 데이터에 대해, 분산-공분산 구조를 선형결합식(주성분)으로 설명하고자 하는 방식- 대표적인 차원 축소 알고리즘.
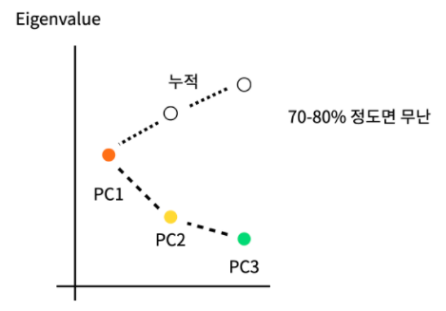
- 대표적인 차원 축소 알고리즘.
-
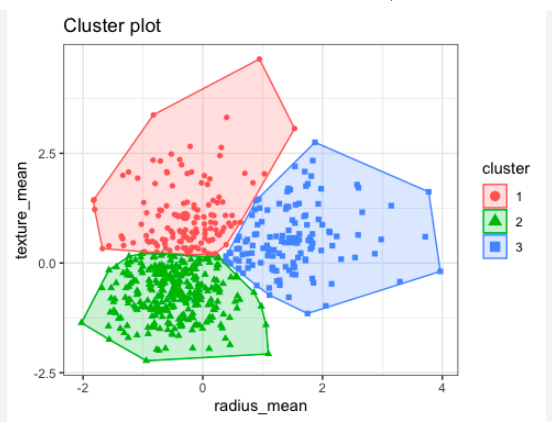
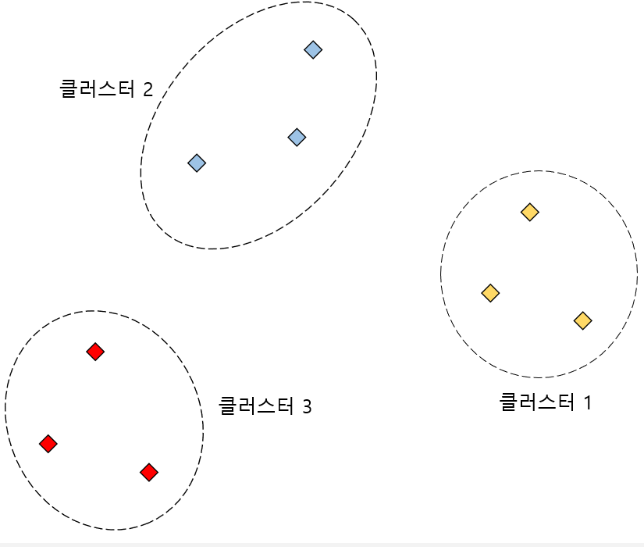
K-means 클러스터링
- k-평균 알고리즘은 주어진 데이터를 K개를 클러스터로 묶는 알고리즘
- 이 알고리즘은 자율 학습의 일종으로, 레이블이 달려 있지 않은 입력 데이터에 레이블을 달아주는 역할.
-
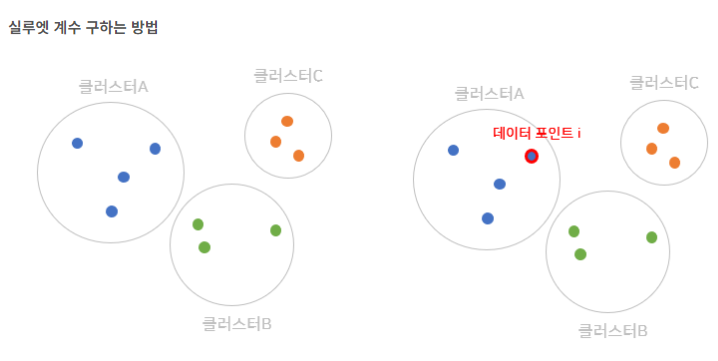
실루엣 계수
- 데이터 클러스터 내에서 일관성을 해석하고 검정하는 방법을 나타냄
- 최적화된 클러스터 갯수를 찾아내는데 사용됨
- 데이터 클러스터 내부에 존재하는 데이터 포인트들 간 일관성의 타당성을 평가
- 얼마나 분류가 잘 되어있는지를 말해주는 것.
-
상관 분석
- 상관관계는 2개 변수가 선형 관계가 있는 범위를 표현하는 통계적 측도
- 원인과 결과에 관한 표현 없이 간단한 관계를 설명함.

-
히트 맵
- 열을 뜻하는 히트와 지도를 뜻하는 맵을 결합시킴.
- 다양한 정보를 일정한 이미지위에 열분포 형태의 비쥬얼한 그래픽으로 출력하는 것이 특징
-
스케일러
-
StandardScaler, MinMaxScaler, RobustScaler
-
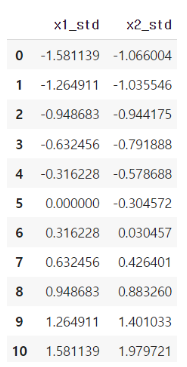
StandadScaler
- 평균 0, 표준편자 1 기준 정규화
- 평균에서 표준편차만큼 떨어져있는지를 기준
- 데이터의 특징을 모르는 경우: 가장 무난한 종류의 정규화
-
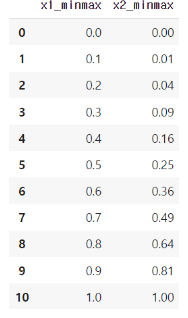
MinMaxScaler
- 최솟값 0, 최댓값 1 기준 정규화
- 각 feature의 최솟값과 최댓값을 기준으로 0~1 구간 내에 균등하게 값을 배정 하는 정규화 방법
- 이상치에 민감하다는 단점이 잇음
- Feature의 범위가 모두 0~1로 등등하게 분포를 바꿀수 있다는 장점.

-
RobustScaler
- 중앙값 0 , 사분위수 IQR 기준 정규화
- 각 feature의 median(Q2)에 해당하는 데이터를 0으로 잡고, Q!,Q3 사분위수와의 IQR 차이 만큼을 기준으로 정규화
- 공식 : (데이터값 - Q2)/ (Q3 - Q1)

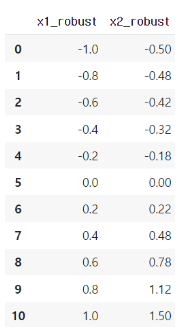
- 이상치에 강한 특징
- 이상치가 많은 데이터를 다루는 경우 유용한 정규화 방법
-
- 회귀분석
- 관찰된 연속형 변수들에 대해 두 변수 사이의 모형을 구한 뒤 적합도를 측정
- 시간에 따라 변화하는 데이터나 영향,가설적 실험,인과 관계의 모델링등의 통계적 예측
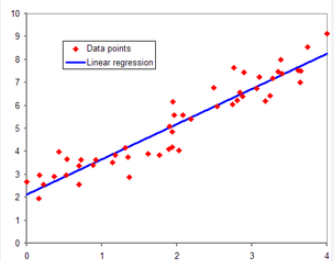
- 투 트랙 괜찮은 방향성? > 괜찮음
<장르>
- popularity 컬럼 삭제: track 데이터에 없기 때문에
- Z-score 후 IQR 벗어나는 것 결측치로 변환 후 제거(7~800개)
- 스탠다드 스케일 진행
- PCA 진행하여 주성분 3개로 진행
- 주성분 가중치 확인함
- K-means 클러스터링 진행(K = 6)
- 클러스터 숫자를 장르에 붙여줌
- 여기서부터 질문
- 검정 통계량은 답이 있느데 비지도학습은 어떻게 확인할수 있나?
- 비지도 평가가 모호함. 군집이라는 것은 떨어져있으면 좋다고 함
- 실루엣 분석을 많이 사용함. 1에 가깝게 잇으면 군집에 가깝다.
- 떨어져 잇으면 잘 나온것
- 600~ 700개는 너무 많이 자료가 삭제됨
- 컬럼이 24개 / 필요한 데이터는? 목적은 비슷한 곡을 추천/ 수치화 된것만 가져가자
- 자연어 처리가 어렵기 때문에 문자로 된 컬럼들은 지웠음
- 컬럼별 이상치 확인을 위해서 box플롯을 사용
- roundness, speechness,등 이상치 있는 컬럼들은 일단 삭제
- 전처리 하기전에 k클러스터링을 해봄
- 6개 컬럼을 가지고 클러스터링을 해봄
- key값만 표준화를 시키고 다시 테이블에 붙임
- PCA를 진행하 여 주성분을 3개로 잡음
<질문>
-
추가하지 않은 6가지를 넣어봐야함
-
이상치를 많이 제거하지 않을때 결과를 봣으면 좋겟다.
-
roundness 곡의 특성들이 군집을 살릴수 잇음
-
클러스터링 특징과 결과까지만 추천 시스템은 생각 안해도 됨.
-
이상치는 어떻게?
- loundess : -20 이하는 어떻게 처리?
- 이상치를 제거 햇을때와 안했을때를 비교해볼듯
- 제거시 왜 이것을 어떻게 제거햇는지를?
- 표준화를 한 후 데이터에 넣어서 클러스터링
- loundess : -20 이하는 어떻게 처리?
-
연도 데이터는 ?
- 0은 이상치는 지우고 진행
-
해석방법은?
- 변수(컬럼)간의 상관관계를 확인해보기
- 관계성을 먼저 확인하고
- 상관 관계를 확인
- 시각화
- 실루엣
-
6/18 회의록
- 이상치 삭제 안한것으로 클러스터링 돌려보기
- 실루엣 돌려보기
- 표준화 안된 데이터만 표준화 하기
- year 있는 것과 없는 것으로
- k_mean 클러스터링 외 기법?

차근차근 열심히 따라가보는 왕초보의 기록들!