
이 포스트는 📔 도메인 주도 개발 시작하기 책을 읽고 공부한 내용을 정리한 포스트입니다.
4장. 리포지터리와 모델 구현
4.1 JPA를 이용한 리포지터리 구현
애그리거트를 어떤 저장소에 저장하느냐에 따라 리포지터리 구현 방식이 다르기에 자바 ORM 표준인 JPA를 이용해서 리포지터리와 애그리거트를 구현하는 방식에 대해 설명한다.
리포지터리를 구현한 클래스는 인프라스트럭처 영역에 속하고 이를 활용하는 인터페이스를 도메인 영역에 속하게 함으로써 DIP를 준수할 수 있다.
리포지터리는 기본적으로 조회와, 저장 기능을 제공해야 한다. 이 기능을 제공하기 위한 인터페이스는 아래와 같은 형식을 갖는다.
public interface UserRepository {
Optional<User> findById(UserId id);
void save(User user);
}인터페이스는 애그리거트 루트를 기준으로 작성되어야 한다.
JPA는 트랜잭션 범위에서 변경한 데이터에 대해서 DB에 자동으로 반영하기에 애그리거트를 수정한 결과를 저장소에 반영하는 메서드는 필요하지 않다.
4.2 스프링 데이터 JPA를 이용한 리포지터리 구현
Spring과 함께 JPA를 적용할때는 Spring Data JPA를 사용한다.
Spring Data JPA는 다음 규칙에 다라 작성한 인터페이스를 찾아서 인터페이스를 구현한 스프링 빈 객체를 자동으로 등록한다.
org.springframework.data.jpa.repository.JpaRepository<T, ID>인터페이스 상속- T: Entity Type, ID: 식별자 Type
4.3 매핑 구현
애그리거트에 대한 JPA 매핑을 위한 기본 규칙은 아래와 같다
- 애그리거트 루트는 엔티티이므로
@Entity로 매핑 설정한다. - 밸류는
@Embeddable로 매핑 설정한다. - 밸류 타입 프로퍼티는
@Embedded로 매핑 설정한다.
@Embeddable 타입에 대한 생성자 선언
불변 타입의 밸류를 활용한다면 생성 시점에서 필요한 값을 모두 전달받으므로, 기본 생성자를 추가할 필요가 없다.
하지만 JPA에서 @Embeddable 타입 매핑을 하기 위해서는 기본 생성자를 제공해야하므로 다른 코드에 사용하지 못하게 protected로 선언된 기본 생성자를 제공해야 한다.
밸류 타입에 대해서 별도 테이블을 활용하는 경우
@SecondaryTable과@AttributeOveride를 사용하여 매핑할 수 있다.
구현 기술의 한계나 팀 표준에 의해서 벨류에 대해 @Entity 매핑을 사용해야 할 때는 연관을 활용하여 매핑을 진행하고 cascade, orphanRemoval 설정을 통해 삭제 과정에서 같이 삭제되도록 설정해야 한다.
4.4 애그리거트 로딩 전략
JPA 매핑에서 생각해야 할 점은 애그리거트에 속한 객체가 모두 모여야 완전한 하나가 된다는 점 이다.
즉시 로딩 (Eager Fetch)
조회 시점에서 애그리거트가 완전한 상태가 되도록 하려면 즉시 로딩(Eager Fetch) 을 설정하면 된다.
위 설정을 한 엔티티는 #find() 메서드로 엔티티를 찾을 때 연관된 구성요소를 DB에서 함께 읽어온다.
예를 들어 User라는 애그리거트 루트가 Image라는 @Entity와 이하 데이터를 갖고 있다면 조회 메소드를 호출했을때 아래와 같은 조인 쿼리를 실행한다.
select u.user_id, ..., img.image_id, ...
from User u
left outer join Image img on u.user_id = i.user_id
where u.user_id = ?조회되는 데이터가 많아진다면 즉시 로딩 방식을 사용할 때 성능 (실행 빈도, 트래픽, 지연 도링 시 실행 속도 등)을 검토해야 한다.
지연 로딩 (Lazy Fetch)
상태를 변경하는 시점에서 필요한 구성 요소만 사용하고자 한다면 지연 로딩(Lazy Fetch) 을 설정하면 된다.
위 설정을 한 엔티티는 상태를 변경하는 시점에 필요한 구성요소를 DB에서 읽어와 상태를 변경한다.
그렇다면 어떤걸 써야할까?
무조건 지연로딩이나 즉시 로딩으로만 설정하기보다 애그리거트에 맞게 선택하는 것이 주요하다.
4.5 애그리거트의 영속성 전파
애그리거트가 완전한 상태여야 한다는 것은 저장, 삭제 과정에서도 하나로 처리되어야 함을 말한다!
@Entity 타입에 대해 매핑된 애그리거트 루트에 대해서 cascade 속성을 추가함으로써 루트가 삭제될 때 같이 처리되도록 설정할 수 있다.
@OneToOne(cascade = {CascadeType.PERSIST, CascadeType.REMOVE},
orphanRemoval = true)
@JoinColumn(name="user_id")
private Image image;4.6 식별자 생성 기능
식별자 생성 방식
- 사용자 직접 생성
- 도메인 로직으로 생성
- DB를 이용한 일련번호 사용
4.7 도메인 구현과 DIP
Entity를 구현하는 과정에서 JPA에 특화된 기술을 활용함으로서 DIP 원칙을 어기고 있다고 볼 수 있다.
구현 기술에 대한 의존 없이 도메인을 순수하게 유지하려면 Spring Data JPA의 Repository 인터페이스를 상속받지 않도록 수정하고 도메인과 인프라스트럭처를 엄격하게 구분해야한다.
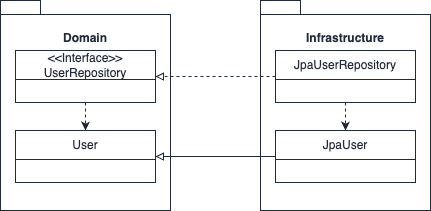
DIP를 적용하는 주된 이유는 저수준 구현이 변경되도라도 고수준이 영향을 받지 않도록 하기 위함이다. 하지만 리포지터리와 도메인 모델의 구현 기술은 거의 바뀌지 않는다. 이에 DIP를 완벽하게 지키면 좋겠지만 개발 편의성과 실용성을 가져가기 위해 엄격한 구분까지 접근하지 않아도 된다.
