통계적 회귀
데이터 로드 & 구조 확인
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
data_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/ecommerce.csv'
data = pd.read_csv(data_url)
data.head()
- 사용자 세션 길이 : 한번 접속햇을 때 평균 사용 시간
- Time on APP : 폰 앱으로 접속했을 떄 유지 시간 (분)
- Time on Website : 웹사이트로 접속했을 떄 유지 시간 (분)
- Length of Membership : 회원 자격 유지 기간 (연)
필요 없는 컬럼 삭제
data.drop(['Email','Address','Avatar'], axis=1, inplace=True)
data.info()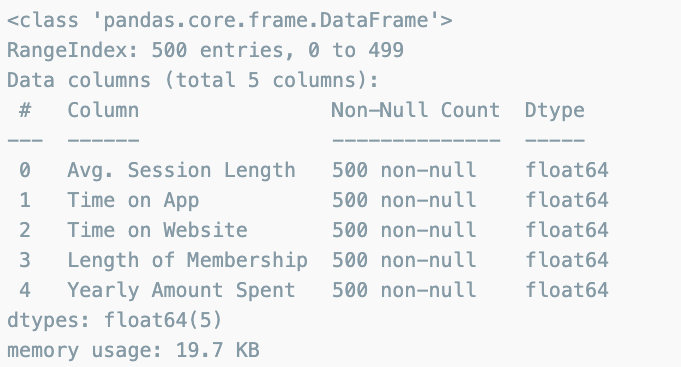
컬럼(특성) 별 boxplot
plt.figure(figsize=(10,6))
sns.boxplot(data=data.iloc[:,:-1]);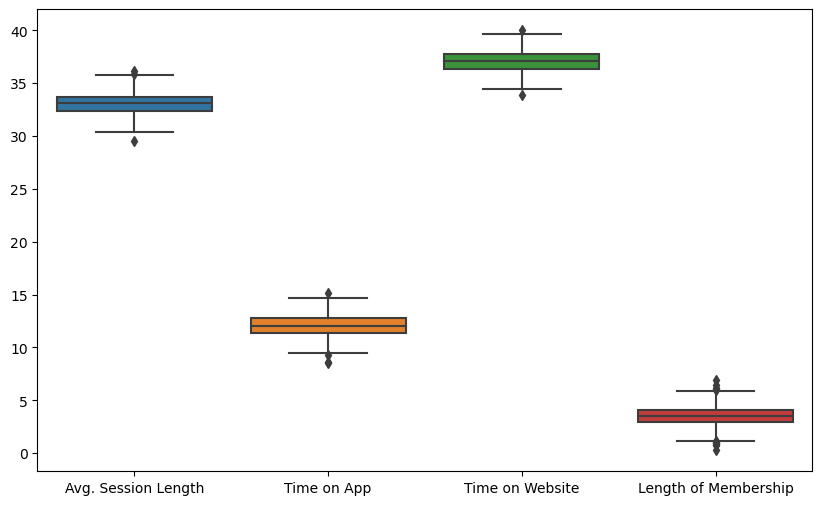
Label 값에 대한 boxplot
plt.figure(figsize=(10,6))
sns.boxplot(data=data['Yearly Amount Spent']);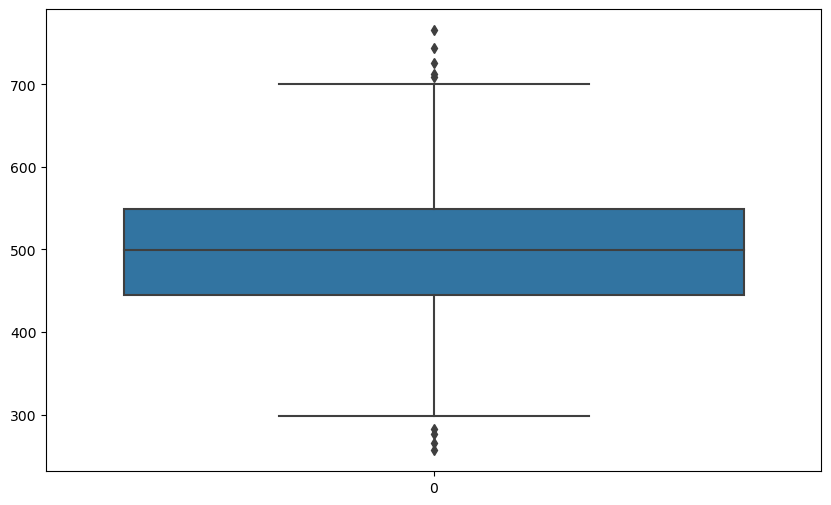
pairplot으로 경향 확인
plt.figure(figsize=(10,6))
sns.pairplot(data=data);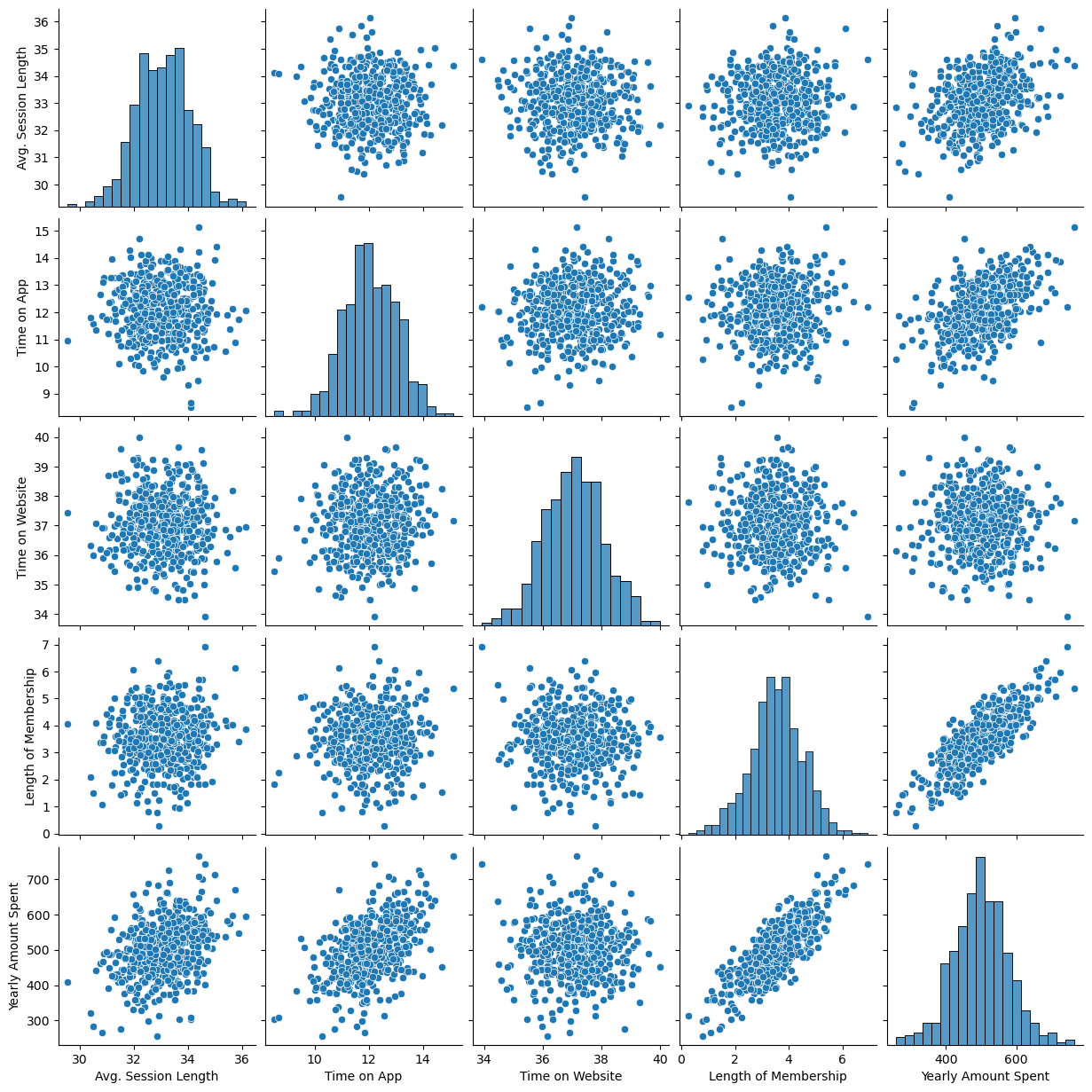
맴버쉽 유지기간
plt.figure(figsize=(12,8))
sns.lmplot(x='Length of Membership', y='Yearly Amount Spent', data=data);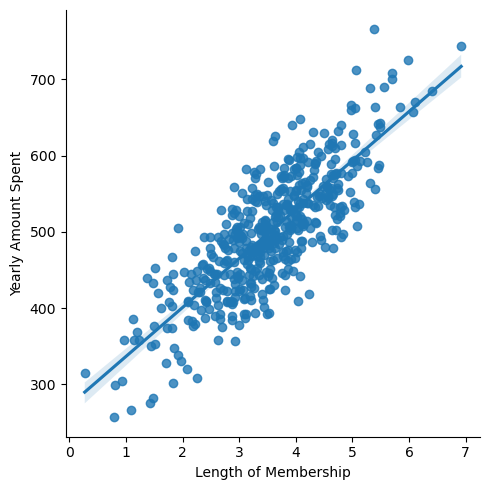
상관이 높은 멤버쉽 유지기간만 가지고 통계적 회귀 (회귀 리포트)
import statsmodels.api as sm
X = data['Length of Membership']
y = data['Yearly Amount Spent']
lm = sm.OLS(y, X ).fit()
lm.summary()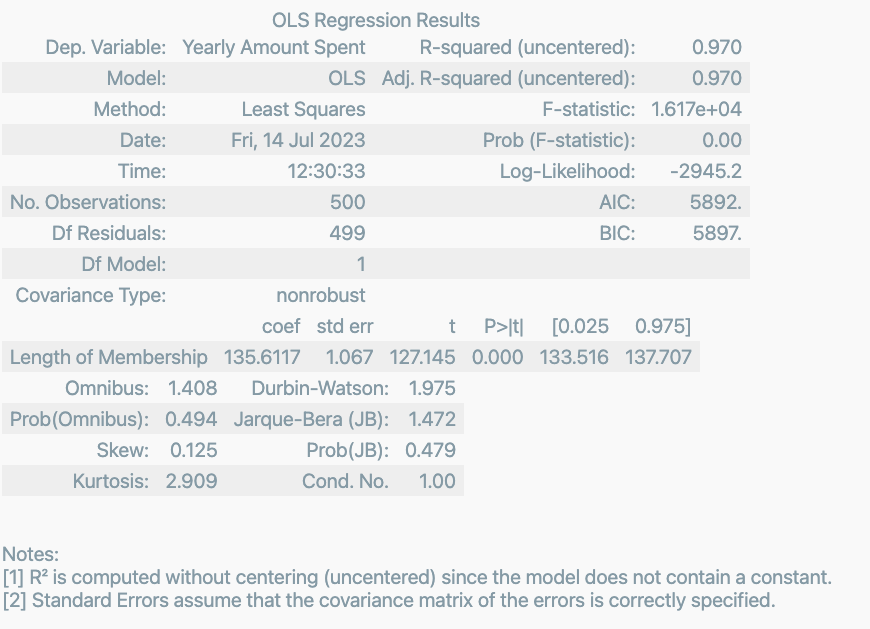
수치으 의미를 해석
- R-suqared : 모형 적합도, y의 분산을 각각의 변숟ㄹ이 약 99.8%로 설명할 수 있음.
- Adj. R-suqared : 독립변수가 여러 개인 다중회귀분석에서 사용
- Prob. F-Statistic : 회귀모형에 대한 통계적 유의미성 검정. 이 값이 0.05 이하라면 모집단에서도 의미가 있다고 볼 수 있음.
회귀 모델
pred = lm.predict(X)
sns.scatterplot(x=X, y=y)
plt.plot(X, pred, 'r', ls='--', lw=3)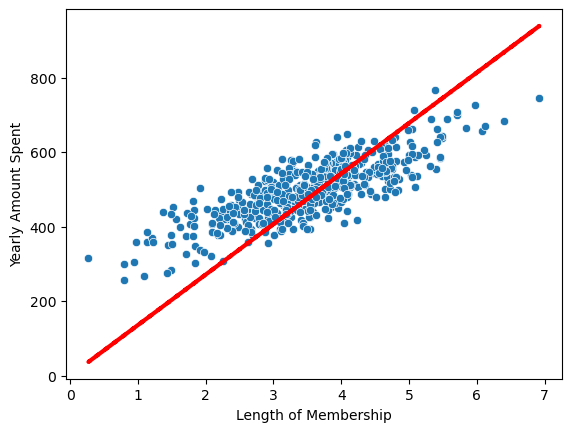
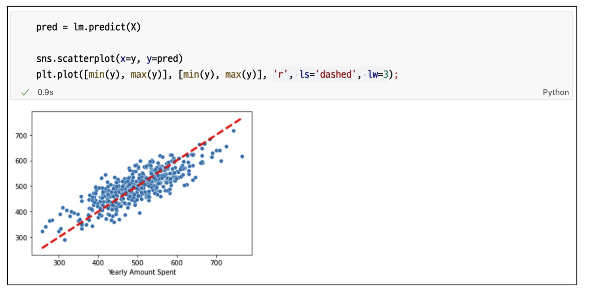
참 값 VS 예측 값
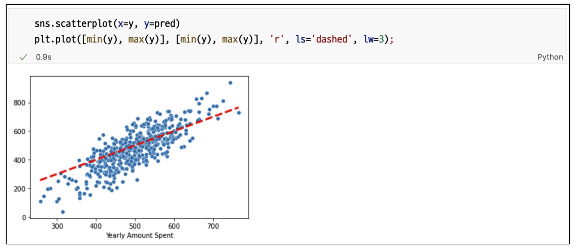
상수항 무
sns.scatterplot(x=y, y=pred)
plt.plot([min(y), max(y)], [min(y), max(y)], 'r', ls='dashed', lw=3)
plt.plot([0,max(y)], [0, max(y)], 'b', ls='dashed', lw=3)
# plt.plot(X, pred, 'r', ls='--', lw=3)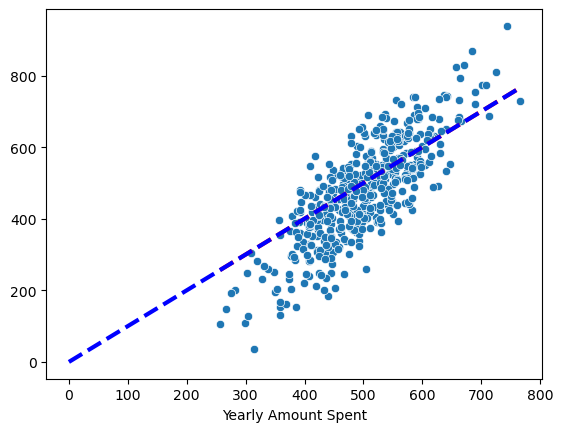
상수항을 넣기
X = np.c_[X, [1]*len(X)]
X[:5]
다시 모델 fit
lm = sm.OLS(y, X ).fit()
lm.summary()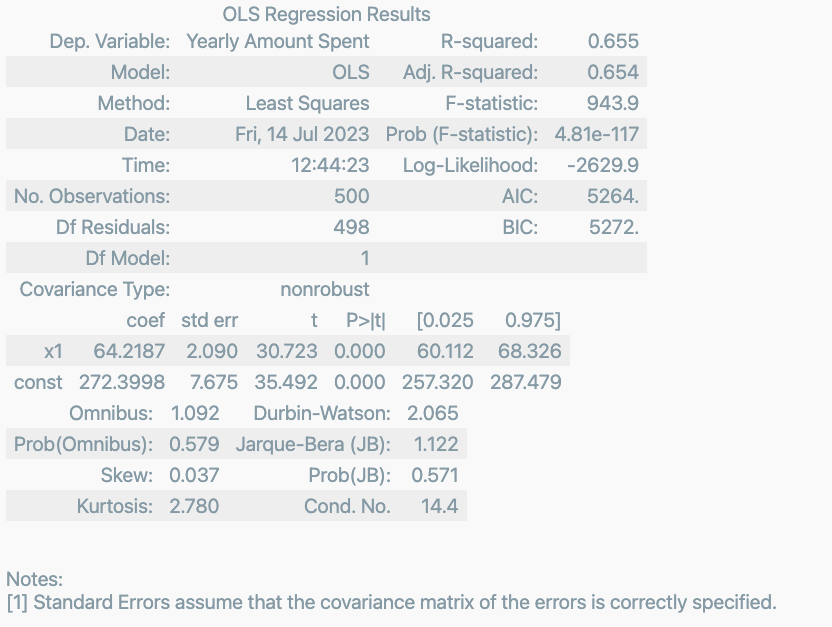
선형 회귀 결과
pred = lm.predict(X)
sns.scatterplot(x=X[:,0], y=y)
plt.plot(X[:,0], pred, 'r', ls='--', lw=3)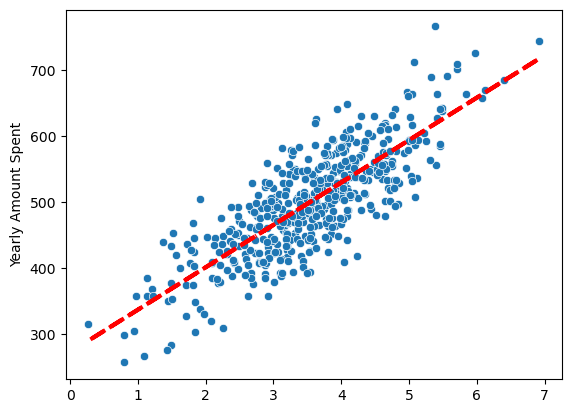
참 값 VS 예측 값
데이터 분리 후 네개 컬럼 모두를 네개 변수로 보고 회귀
from sklearn.model_selection import train_test_split
X = data.drop('Yearly Amount Spent', axis=1)
y = data['Yearly Amount Spent']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
lm = sm.OLS(y_train, X_train ).fit()
lm.summary()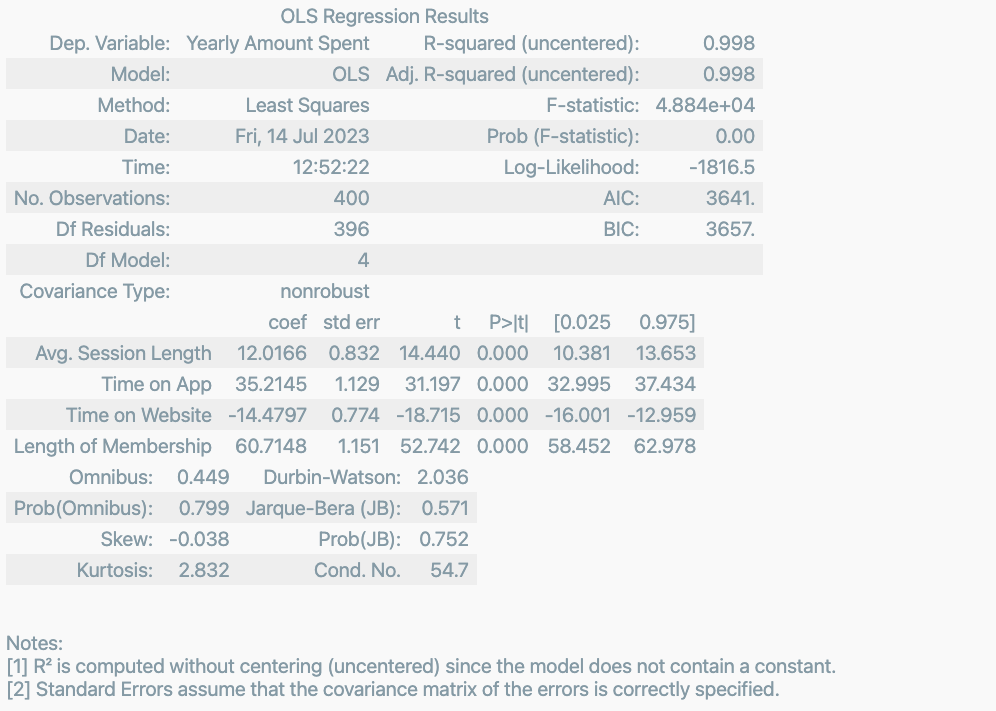
참 값 VS 예측 값
pred = lm.predict(X_test)
sns.scatterplot(x=y_test, y=pred)
plt.plot([min(y_test), max(y_test)],[min(y_test), max(y_test)],'r')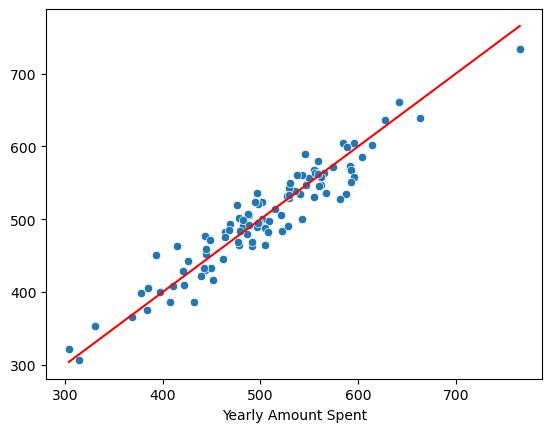

10√2 Data
정보 감사합니다.