신용카드 부정 사용자 검출

신용카드 부정사용 검출에 관한 논문의 한 예

데이터 경로
데이터 개요

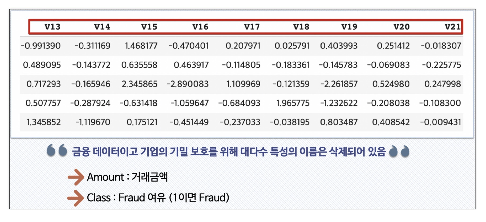
데이터 특성
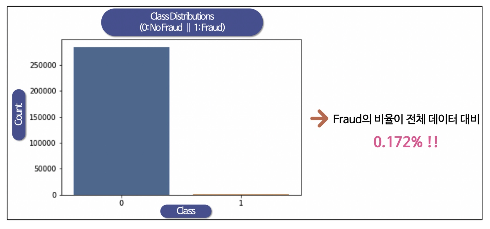
데이터의 불균형이 극심함
데이터 읽고 관찰하기
데이터 읽기
import pandas as pd
data_path = '../ds_study/data/creditcard.csv'
raw_data = pd.read_csv(data_path)
raw_data.head()
데이터 특성
- 데이터 특성은 여러 이유로 이름이 갖춰져 있다.
raw_data.columns
데이터 라벨의 불균형이 정말 심하다
raw_data['Class'].value_counts()
frauds_rate = round(raw_data['Class'].value_counts()[1]/len(raw_data)*100,2)
print('Frauds', frauds_rate, '% of the dataset')
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(x='Class', data= raw_data)
plt.title('Class Distribution \n (0: No Fraud || 1: Fraud)', fontsize = 14)
plt.show()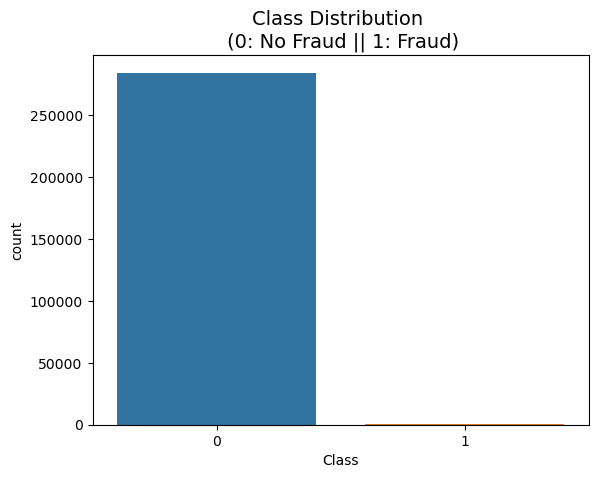
X,y로 데이터 선정
X = raw_data.iloc[:, 1:-1]
y = raw_data.iloc[:, -1]
X.shape, y.shape 
데이터 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3, random_state=13, stratify=y)나눈 데이터의 불균형 정도 확인
import numpy as np
np.unique(y_train, return_counts=True)
tmp = np.unique(y_train, return_counts=True)[1]
tmp[1]/len(y_train)*100
1st Trial
분류기의 성능을 return하는 함수 작성
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
def get_clf_eval(y_test, pred):
acc = accuracy_score(y_test, pred)
pre = precision_score(y_test, pred)
re = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
auc = roc_auc_score(y_test, pred)
return acc, pre, re, f1, auc성능을 출력하는 함수 작성
from sklearn.metrics import confusion_matrix
def print_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
acc, pre, re, f1, auc = get_clf_eval(y_test, pred)
print('==> Confusion Matrix')
print(confusion)
print('=======================')
print('Accuracy : {0:.4f}. precision: {1: .4f}'.format(acc, pre))
print('Recall : {0:.4f}. F1: {1: .4f}, AUC: {2: .4f}'.format(re, f1, auc))Logistic Regression
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(random_state=13, solver='liblinear')
lr_clf.fit(X_train, y_train)
lr_pred = lr_clf.predict(X_test)
print_clf_eval(y_test, lr_pred)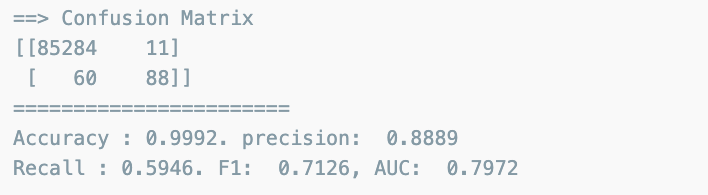
np.unique(y_test, return_counts=True)
Decision Tree
%%time
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(max_depth=4,random_state=13)
dt_clf.fit(X_train, y_train)
dt_pred = dt_clf.predict(X_test)
print_clf_eval(y_test, dt_pred)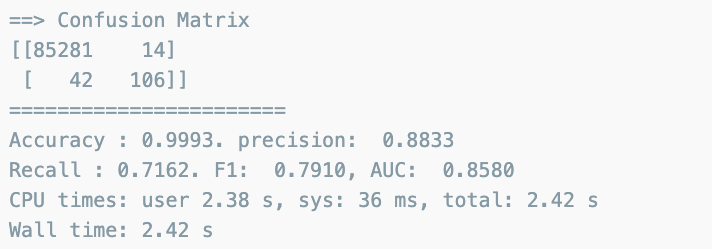
Random Forest
%%time
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1, n_estimators=100)
rf_clf.fit(X_train, y_train)
rf_pred = rf_clf.predict(X_test)
print_clf_eval(y_test, rf_pred)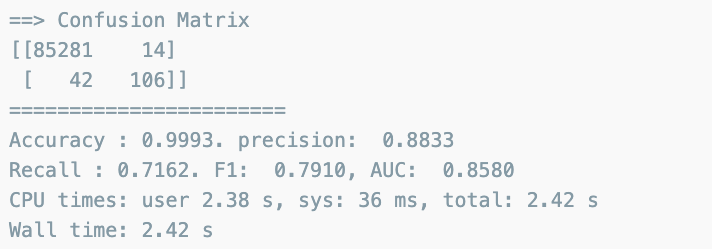
LightGBM
%%time
import warnings
warnings.filterwarnings('ignore')
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(random_state=13, n_jobs=-1, n_estimators=1000,num_leaves=64, boost_from_average=False)
lgbm_clf.fit(X_train, y_train)
lgbm_pred = lgbm_clf.predict(X_test)
print_clf_eval(y_test, lgbm_pred)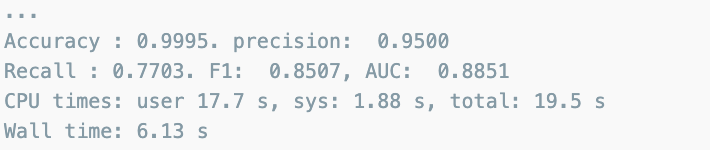
- 은행 입장에서는 Recall 선호
- 사용자 입장에서는 Precision 선호
모델과 성능을 주면 성능을 출력하는 함수
def get_result(model, X_train, y_train, X_test, y_test):
model.fit(X_train, y_train)
pred = model.predict(X_test)
return get_clf_eval(y_test, pred)다수의 모델의 성능을 정리해서 DataFrame으로 반환하는 함수
def get_result_pd(models, model_names, X_train, y_train, X_test, y_test):
col_names = ['accuracy', 'precision','recall','f1', 'roc_auc']
tmp = []
for model in models:
tmp.append(get_result(model, X_train, y_train, X_test, y_test))
return pd.DataFrame(tmp, columns=col_names, index=model_names)4개의 분류 모델을 한번에 표로 정리
import time
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticsRegression', 'DecisionTree', 'RandomForest', 'LightGBM' ]
start_time = time.time()
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
print('Fit time : ', time.time() - start_time)
results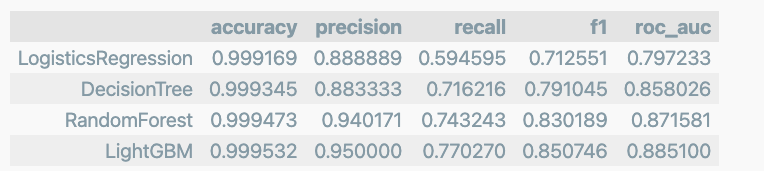
확실이 앙살블 계열의 성능이 우수하다
2nd Trial
- Amount : 신용카드 사용 금액
plt.figure(figsize=(10,5))
sns.displot(raw_data['Amount'], color='r')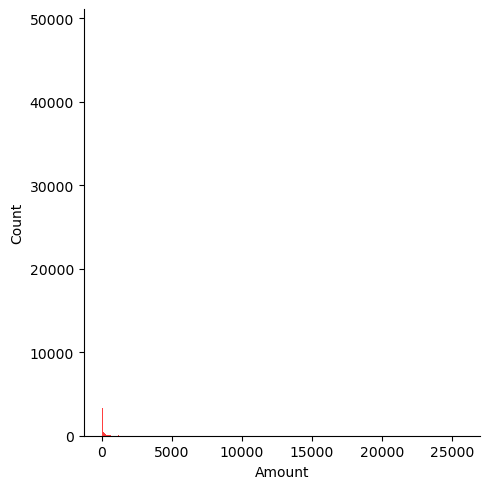
- 컬럼의 분포가 특정 대역이 아주 많다
Amount 컬럼에 StandardScaler 적용
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
amount_n = scaler.fit_transform(raw_data['Amount'].values.reshape(-1,1))
raw_data_copy = raw_data.iloc[:, 1:-2]
raw_data_copy['Amount_Scaled'] = amount_n
raw_data_copy.head()
컬럼을 다시 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(raw_data_copy, y,test_size=0.3, random_state=13, stratify=y)모델에 다시 평가
import time
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticsRegression', 'DecisionTree', 'RandomForest', 'LightGBM' ]
start_time = time.time()
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
print('Fit time : ', time.time() - start_time)
results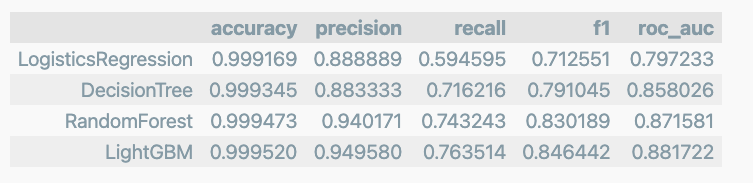
모델별 ROC 커브
from sklearn.metrics import roc_curve
def draw_roc_curve(models, model_names, X_test, y_test):
plt.figure(figsize=(10,10))
for model in range(len(models)):
pred = models[model].predict_proba(X_test)[:,1]
fpr, tpr, thresholds = roc_curve(y_test, pred)
plt.plot(fpr, tpr, label=model_names[model])
plt.plot([0,1],[0,1],'k--', label='random guess')
plt.title('ROC')
plt.legend()
plt.grid()
plt.show()
draw_roc_curve(models, model_names, X_test, y_test)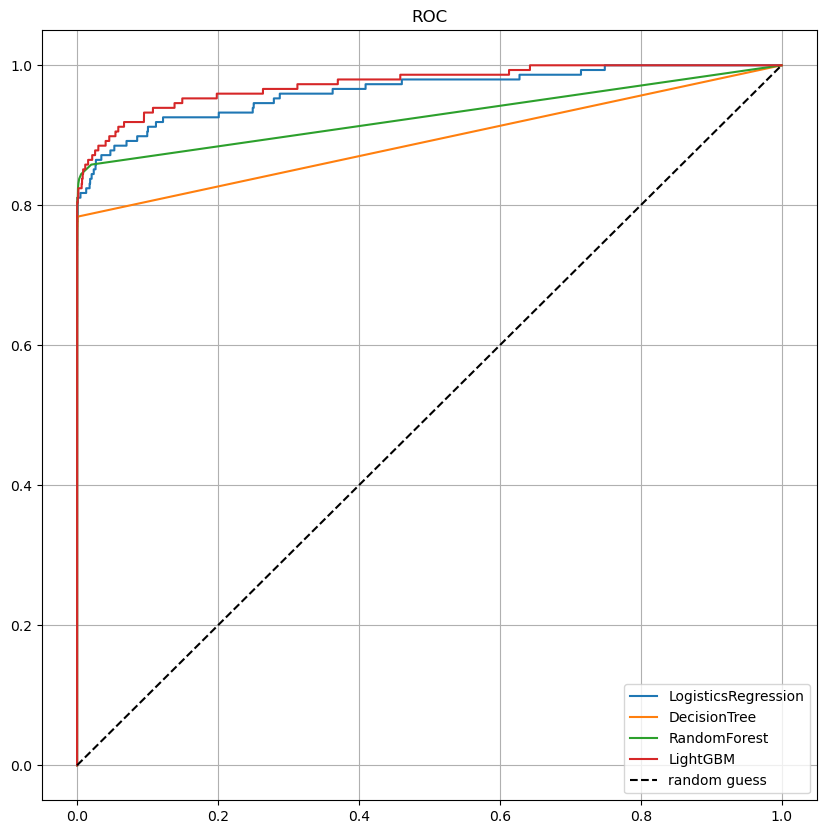
log scale
amount_log = np.log1p(raw_data['Amount'])
raw_data_copy['Amount_Scaled'] = amount_log
raw_data_copy.head()
분포가 변화홤
plt.figure(figsize=(10,5))
sns.displot(raw_data_copy['Amount_Scaled'], color='r')
plt.show()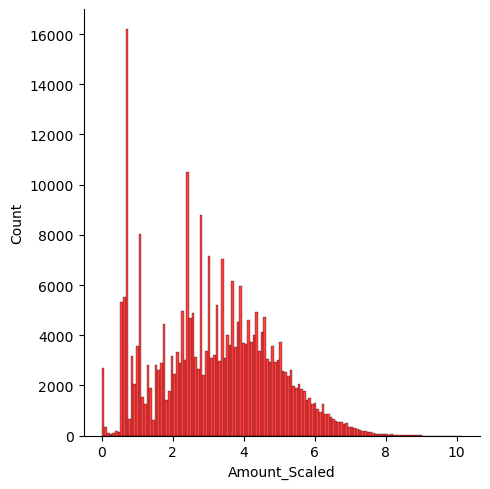
다시 성능을 확인
%%time
X_train, X_test, y_train, y_test = train_test_split(raw_data_copy, y,test_size=0.3, random_state=13, stratify=y)
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticsRegression', 'DecisionTree', 'RandomForest', 'LightGBM' ]
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
results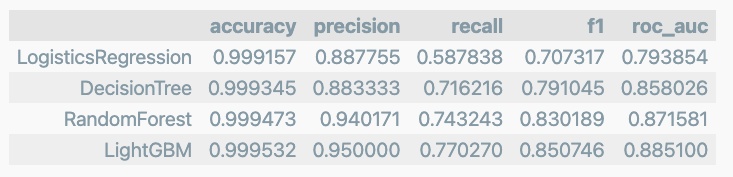
- 미세한 변화는 보이지만 확실한 변화는 관찰되지 않았다.
ROC 커브 결과
draw_roc_curve(models, model_names, X_test, y_test)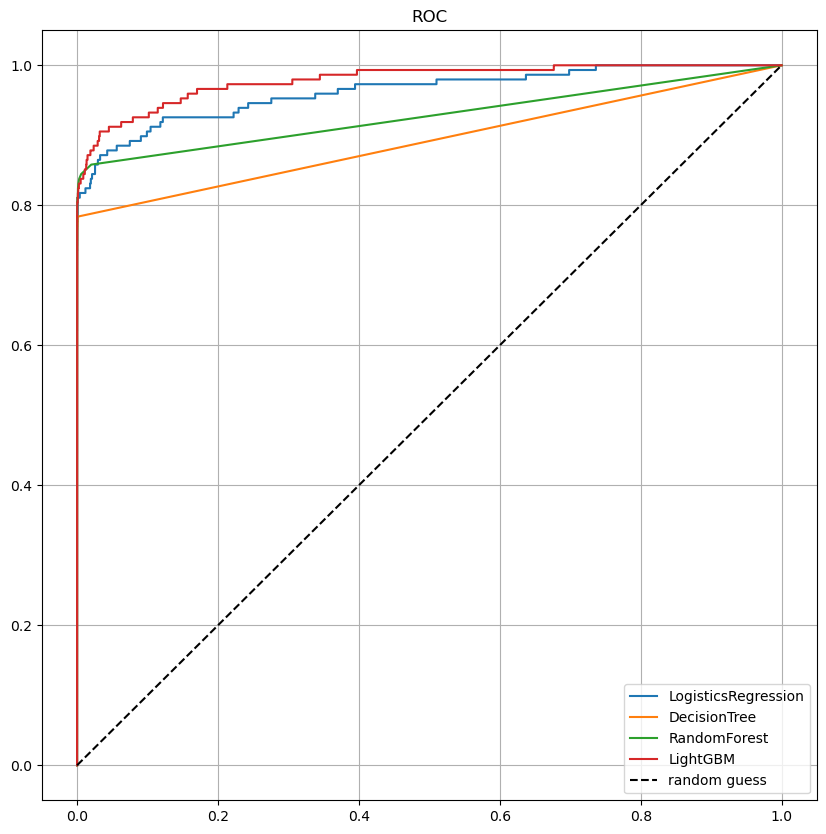
3rd Trail
Outlier를 정리하기 위해 Outlier의 인덱스를 파악하는 코드
def get_outlier(df=None, column=None, weight = 1.5):
fraud = df[df['Class']==1][column]
quantile_25 = np.percentile(fraud.values,25)
quantile_75 = np.percentile(fraud.values,75)
iqr = quantile_75 - quantile_25
iqr_weight = iqr * weight
lowest_val = quantile_25 - iqr_weight
highest_val = quantile_75 + iqr_weight
outlier_index = fraud[(fraud < lowest_val) | (fraud > highest_val)].index
return outlier_indexOutlier 찾기
get_outlier(df=raw_data, column='V14') 
Outlier 제거
outlier_index = get_outlier(df=raw_data, column='V14')
raw_data_copy.drop(outlier_index, axis=0, inplace=True)
raw_data_copy.shape
Outlier를 제거하고 데이터 나누기
X = raw_data_copy
raw_data.drop(outlier_index, axis=0, inplace=True)
y = raw_data.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3, random_state=13, stratify=y)%%time
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticsRegression', 'DecisionTree', 'RandomForest', 'LightGBM' ]
results = get_result_pd(models, model_names, X_train, y_train, X_test, y_test)
results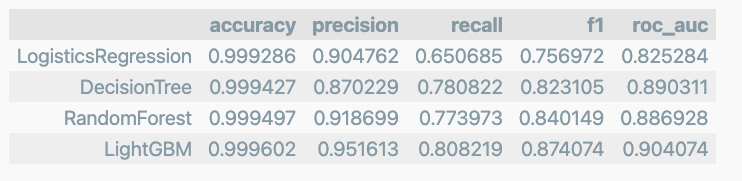
ROC 커브
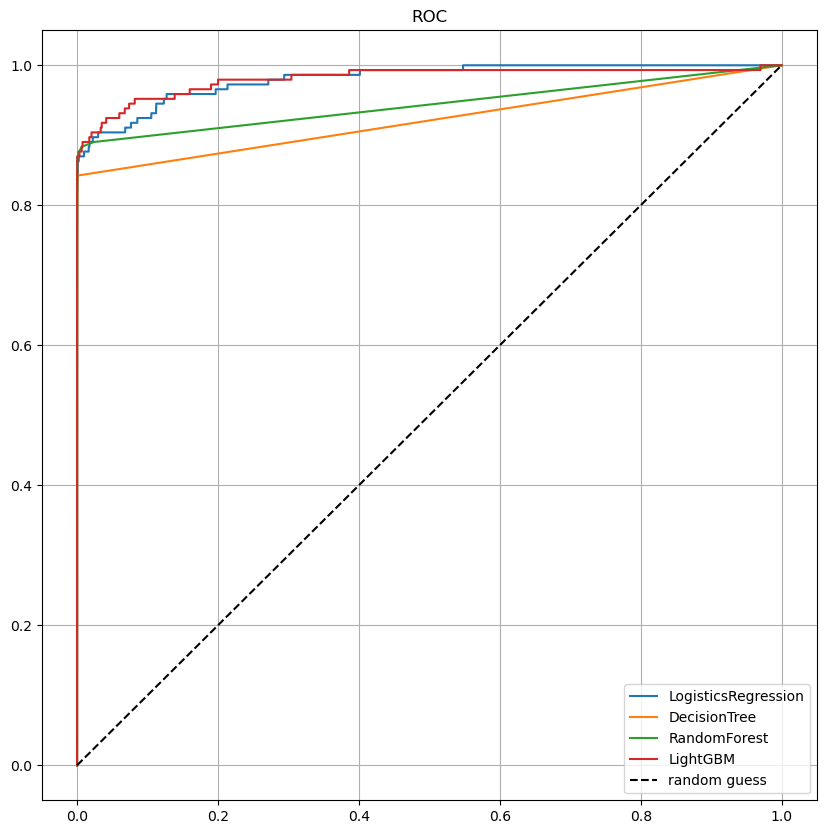
4th Trial
Oversampling - SMOTE
Undersampling vs Oversampling
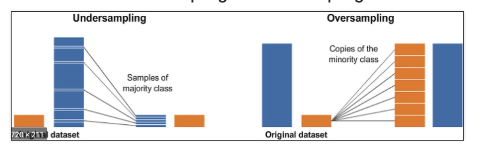
- 데이터의 불균형이 극심할 때 불균형한 두 클래스와 분포를 강제로 맞춰보는 작업
- 언더샘플링: 많은 수의 데이터를 적은 수의 데이터로 강제로 조정
- 오버 샘플링 :
- 원본 데이터의 피쳐 값들을 아주 약간 변경하여 증식
- 대표적으로 SMOTE(Synthetif Minority Over-sampling Technique) 방법이 있음
- 적은 데이터 세트에 있는 개별 데이터를 k 최근접이웃 방법으로 찾아서 데이터의 분포 사이에 새로운 데이터를 만드는 방식
- imbalanced-learn 이라는 Python pkg가 있음
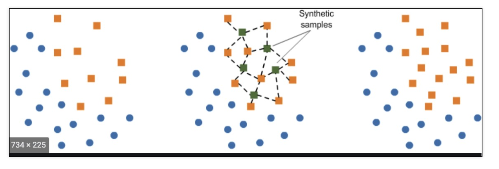
- pip install imbalanced-learn
SMOTE 적용
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=13)
X_train_over, y_train_over = smote.fit_resample(X_train, y_train)데이터의 증강 효과는
X_train.shape, y_train.shape
X_train_over.shape, y_train_over.shape
결과
print(np.unique(y_train, return_counts=True))
print(np.unique(y_train_over, return_counts=True))
다시 학습을 돌려보면
%%time
models = [lr_clf, dt_clf, rf_clf, lgbm_clf]
model_names = ['LogisticsRegression', 'DecisionTree', 'RandomForest', 'LightGBM' ]
results = get_result_pd(models, model_names, X_train_over, y_train_over, X_test, y_test)
results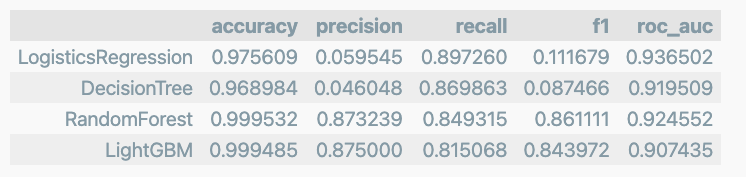
- recall은 확실이 좋아졌다.
ROC 커브
draw_roc_curve(models, model_names, X_test, y_test)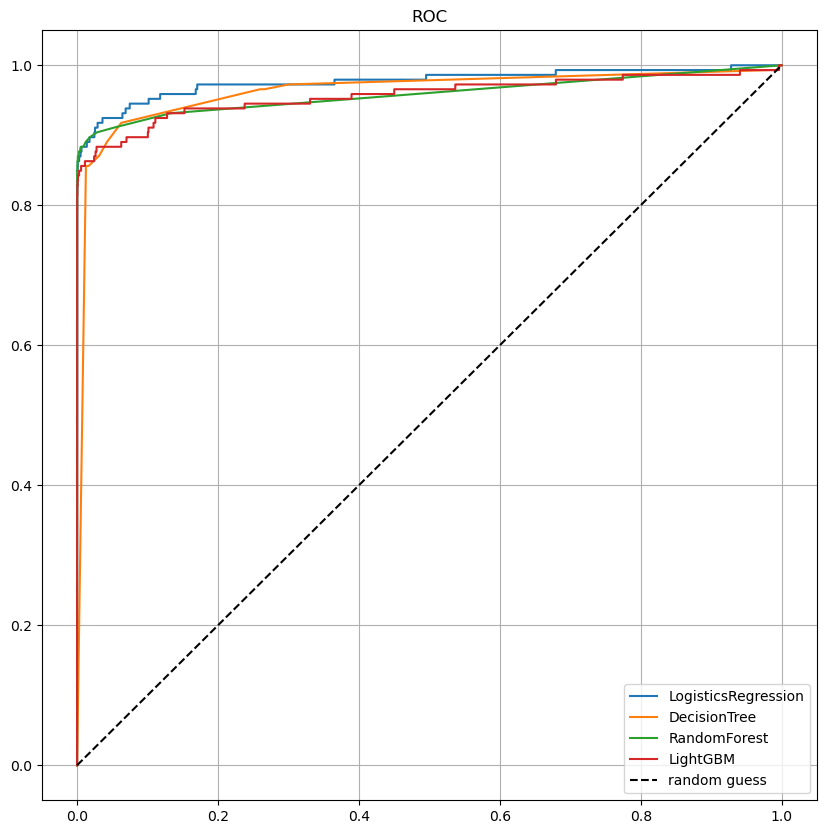

10√2 Data