Natural Language Processing
- Korean natural language processing in Python
- 쉽고 간결한 한국어 정보처리 파이썬 패키지
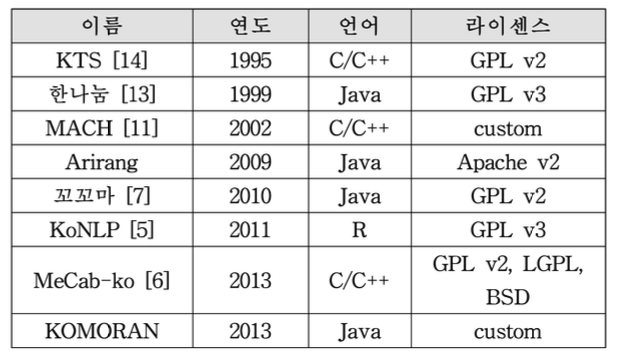
파이썬은 간결한 아름다움을 추구하는 동시에 강력한 스트링 연산이 가능한 언어다. KoNLPy는 그러한 특장점을 살려, 파이썬으로 한국어 정보처리를 할 수 있게 하는 패키지이다. 꼬꼬마, 한나눔, MeCab-ko 등 국내외에서 개발된 여러 형태소 분석기를 포함하고, 자연어처리에 필요한 각종 사전, 말뭉치, 도구, 및 다양한 튜토리얼을 포함하여 누구나 손쉽게 한국어 분석을 할 수 있도록 만들었다.
여러 오픈소스 한국어 형태소 분석기와 개발 언어
KoNLPy는 이와 같은 파이썬의 이점 위에 다음의 설계철학을 바탕으로 개발되었다.
쉽고 간단한 사용법. 직관적인 함수명을 사용한다. 메뉴얼을 따로 읽는데 많은 시간을 보내지 않아도 설치를 받자마자 바로 실행해서 결과를 볼 수 있게 한다.
확장가능성. 형태소 분석기 뿐 아니라 다양한 자연어처리 기능과 말뭉치를 포괄하는 것을 목표로 하며, 따라서 말뭉치, 메소드 등이 추가되는 것을 감안하여 개발을 진행한다. NLTk가 다양한 스테머(stemmer)를 지원하는것과 마찬가지로, 여러 형태소 분석기 중에서 목적과 취향에 맞는 것을 쉽게 선택할 수 있도록 한다.
친절하고 상세한 문서. 패키지에서 중요도가 다소 저평가될 수 있는 부분이 문서화인데, 사실 상세한 문서와 풍부한 에제는 초심자에게 가장 큰 도움이 되는 부분이기도 하다. 특히 NLRK, Gensim[10] 등 다른 파이썬 패키지들과 함께 사용할 때, 어떻게 응용하여 사용할 수 있는지 보여주는 것도 중요하다.
개방과 공유. 패키지는 사용 환경이 계속 변할 수 있기 때문에 지속가능성(sustainability)을 유지할 수 있는지가 중요하다. 또한, 실질적인 사용자의 니즈(needs)를 파악하기 위해서는 누구나 개발에 참여를 할 수 있게 하는 것도 중요하다. 따라서 본 패키지의 소스는 온라인에 공개하여 참여를 독려하고 있다.




!conda update conda
!pip install --upgrade pip
!pip install konlpy
!pip install tweepy==3.10.0
!conda install -y -c conda-forge jpype1
!conda install -y -c conda-forge wordcloud
!conda install -y nltk
!conda install -y scikit-learnfrom konlpy.tag import Kkma
Kkma = Kkma()
Kkma.pos('한국어 분석을 시작합니다 재미있어요~~')
from konlpy.tag import Hannanum
Hannanum = Hannanum()
Hannanum.morphs('한국어 분석을 시작합니다 재미있어요~~')
from konlpy.tag import Twitter
t = Okt()
t.pos('한국어 분석을 시작합니다 재미있어요~~')
워드클라우드
from wordcloud import WordCloud, STOPWORDS
import numpy as np
from PIL import Image
text = open('../data/06_alice.txt').read()
alice_mask = np.array(Image.open('../data/06_alice_mask.png'))
stopwords = set(STOPWORDS)
stopwords.add('said') 
그림파일, 이상한 나라의 앨리스소설, 본문에서 많이 등장하는 said 단어는 stopword 처리하도록 합니다.
plt.figure(figsize=(8,8))
plt.imshow(alice_mask, cmap = plt.cm.gray, interpolation='bilinear')
wc = WordCloud(
background_color ='white',
max_words = 2000,
mask = alice_mask,
stopwords = stopwords
)
wc = wc.generate(text)
wc.words_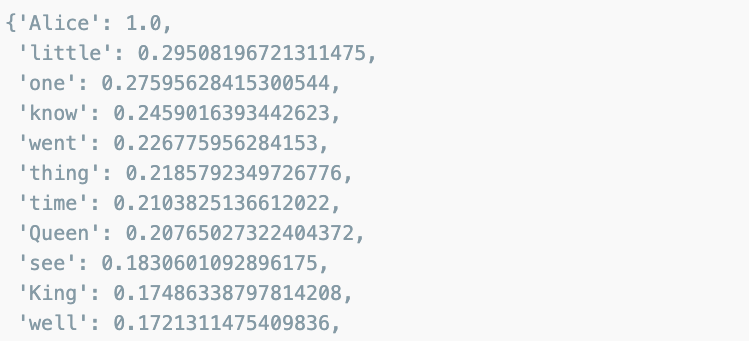
WordCloud 모듈은 자체적으로 단어를 추출해서 빈도수를 조사하고 정규화하는 기능을 가지고 있습니다.
plt.figure(figsize=(12,12))
plt.imshow(wc)
plt.axis('off')
plt.show()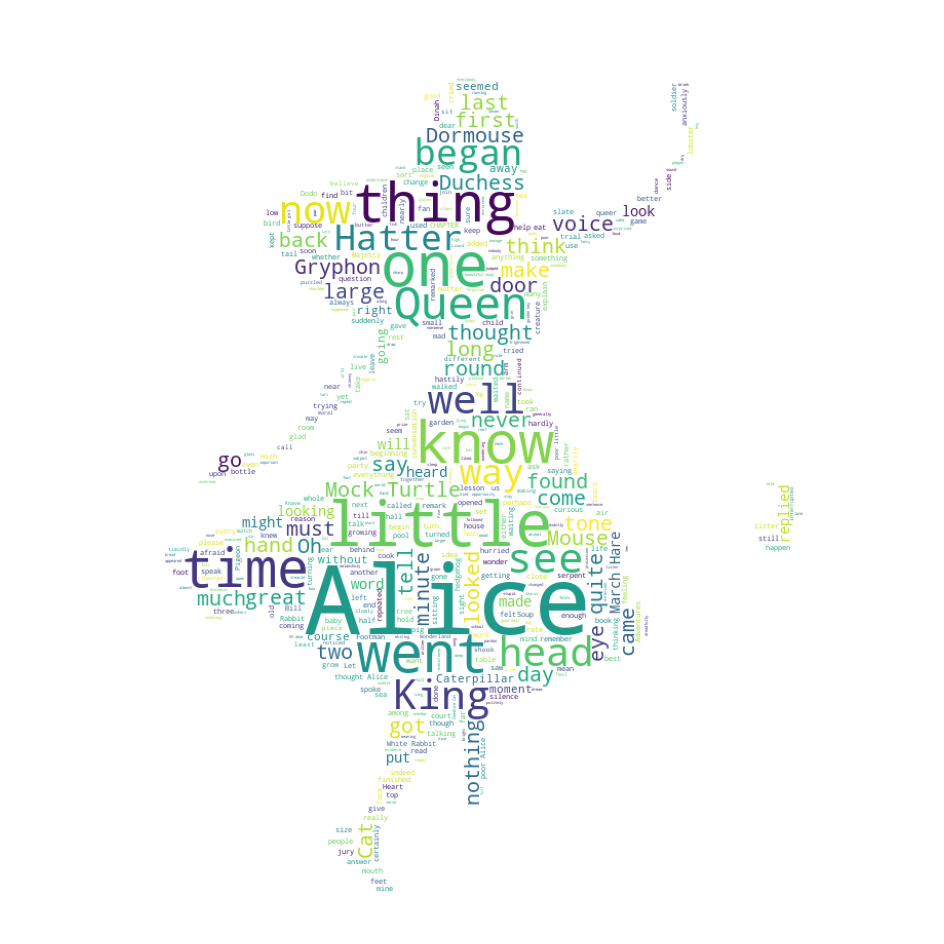
Star Wars
text = open('../data/06_a_new_hope.txt').read()
text = text.replace('HAN','Han')
text = text.replace("LUKE'S",'Lukes')
mask = np.array(Image.open('../data/06_stormtrooper_mask.png'))
stopwords.add('int')
stopwords.add('ext')
wc = WordCloud(
max_words=1000,
mask=mask,
stopwords=stopwords,
margin=10,
random_state=1
).generate(text)
default_colors = wc.to_array( )
import random
def grey_color_func(
word, font_size, position, orientation, random_state=None, **kwargs
):
return "hs1(0, 0%%, %d%%)" % random.randint(60,100)
plt.figure(figsize=(12,12))
plt.imshow(wc.recolor(color_func=grey_color_func, random_state=13))
plt.axis('off')
plt.show()
육아휴직 법안분석
- 육아휴직관련 법안 대한민국 국회 제 1809890호 의안
- KoNLPy는 대한민국 법령을 가지고 있다.
import nltk
from konlpy.corpus import kobill
doc_ko = kobill.open('1809890.txt').read()
doc_ko 
Twitter 엔진으로 명사 분석. Twitter -> Okt
from konlpy.tag import Okt
t = Okt()
tokens_ko = t.nouns(doc_ko)
tokens_ko
nltk를 사용해서 토큰(빈도수 포함)분석
ko = nltk.Text(tokens_ko, name='육아휴직법')
ko
len(ko.tokens)
len(set(ko.tokens))
plt.figure(figsize=(12,6))
ko.plot(50)
plt.show()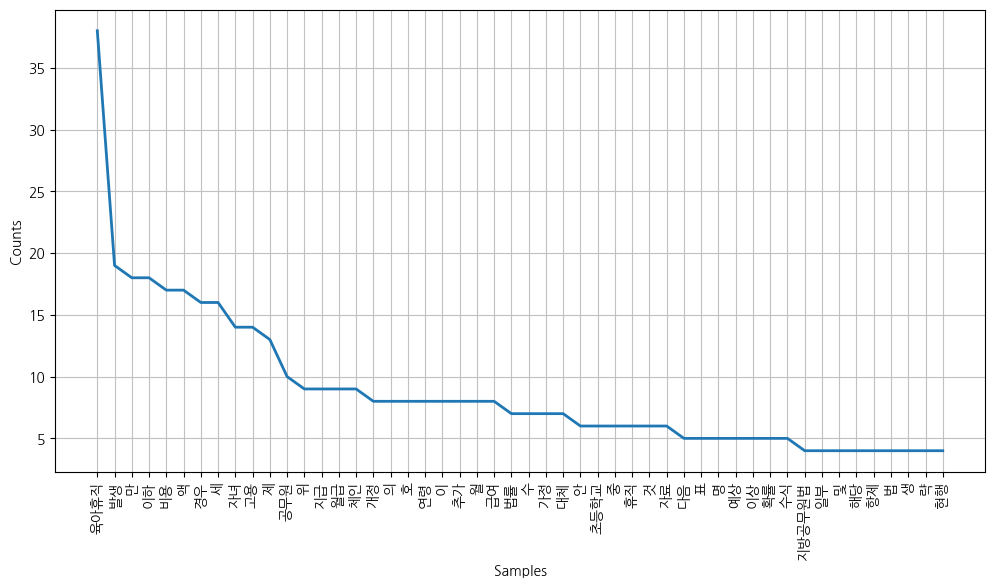
data = ko.vocab().most_common(150)
wordcloud = WordCloud(
font_path='/Library/Fonts/Arial Unicode.ttf',
relative_scaling=0.2,
background_color='white'
).generate_from_frequencies(dict(data))
plt.figure(figsize=(12,8))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
나이브베이즈 분류

기계 학습분야에서, 나이브 베이즈 분류는 특성들 사이의 독리블 가정하는 베이즈 정리를 적용한 확률 분류기의 일종으로 1950 년대 이후 광범위하게 연구되고 있다.
통계 및 컴퓨터 과학 문헌에서, 나이브 베이즈는 단순 베이즈, 독립 베이즈를 포함한 다양한 이름으로 알려져 있으며, 1960년대 초에 텍스트 검색 커뮤니티에 다른 이름으로 소개되기도 하였다.
나이브 베이즈 분류는 텍스트 분류에 사용됨으로써 문서를 여러 범주 (예:스팸, 스포츠,정치) 중 하나로 판단하는 문제에 대한 대중적인 방법으로 남아있다. 또한 자동 의료 진단 분야에서의 응용사례를 보면, 적절한 전처리를 하면 더 진보 된 방법들 (예:서포트 백터 머신(Support Vector Machine)) 과도 충분한 경쟁력을 보임을 알수 있다.
from nltk.tokenize import word_tokenize
import nltkNaive Bayes 분류기는 지도학습이라서 정답을 알려주어야 한다.
train = [
{'i like you' : 'pos'},
{'i hate you' : 'neg'},
{'you like me' : 'neg'},
{'i like her' : 'pos'}
]전체 말뭉치를 만든다.
all_words = set(
word for sentence in train for word in word_tokenize(sentence[0])
)
all_words 
말뭉치 대비해서 단어가 있고 없음을 표기한다.
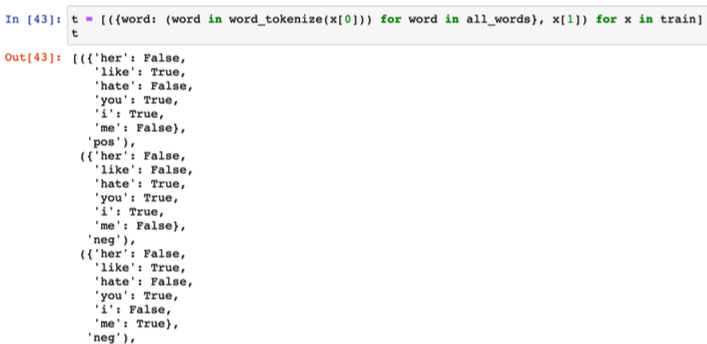
Naive Bayes 분류가 훈련을 시작했다.
like가 있을 때, Positive할 확률이 1.7:1.0 이다.
이렇게 각 단어별로 독립적으로 확률을 계산하기 때문에 naive하다고 한다.

학습결과를 가지고 테스트
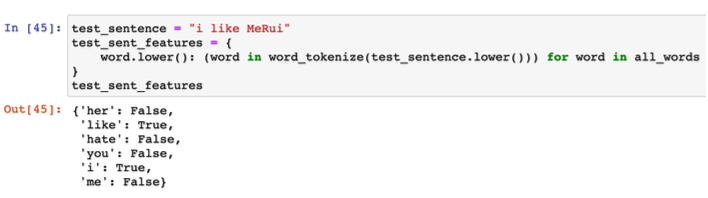
결과는 positive

한글로
정답을 알고 있는 문장으로 훈련용 데이터를 줌
from konlpy.tag import Okt
pos_tagger = Okt()
train = [
('메리가 좋아','pos'),
('고양이도 좋아','pos'),
('난 수업이 지루해','neg'),
('메리는 이쁜 고양이야','pos'),
('난 마치고 메리랑 놀거야','pos'),
]
all_words = set(
word for sentence in train for word in word_tokenize(sentence[0])
)
all_words
전체 말뭉치를 만듦. 메라가 메리는 메리랑 모두 다른 단어로 인식
t = [({word : (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train]
t
classifier = nltk.NaiveBayesClassifier.train(t)
classifier.show_most_informative_features()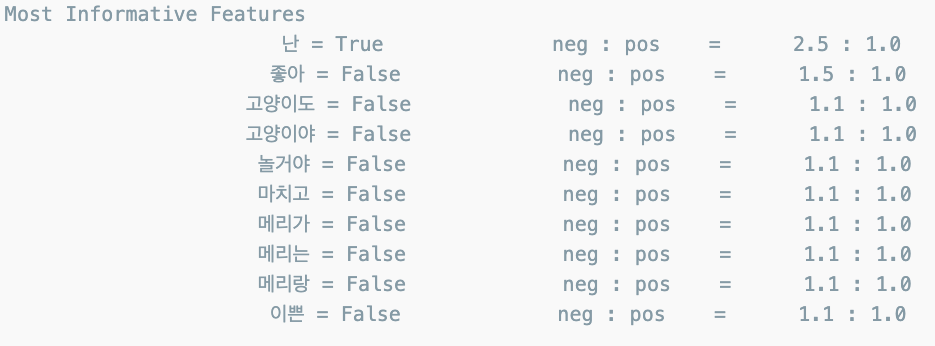
test_sentence = '난 수업이 마치면 메리랑 놀거야 '
test_sentence_features = {
word.lower(): (word in word_tokenize(test_sentence.lower())) for word in all_words
}
test_sentence_features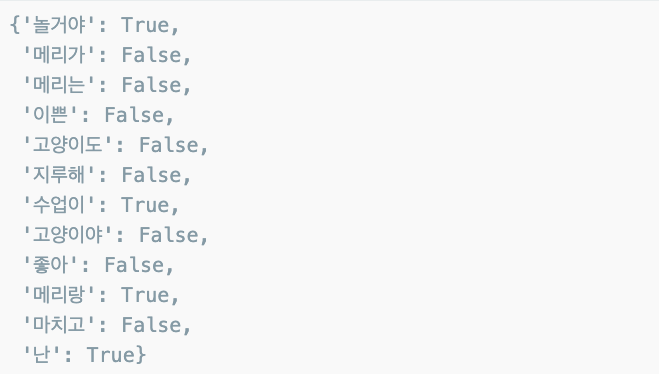
classifier.classify(test_sentence_features)
한글은 형태소 분석이 필수
형태소 분석을 한 후 품사를 단어 뒤에 붙여 넣도록 함
def tokenize(doc):
return ['/'.join(t) for t in pos_tagger.pos(doc, norm=True, stem=True)]train_docs = [(tokenize(row[0]), row[1]) for row in train]
train_docs
풀어서 말뭉치를 만들면
tokens = [t for d in train_docs for t in d[0]]
tokens
def term_exists(doc):
return {word: (word in set(doc)) for word in tokens}
train_xy = [(term_exists(d),c) for d,c in train_docs]
train_xy
classifier = nltk.NaiveBayesClassifier.train(train_xy)
classifier.show_most_informative_features()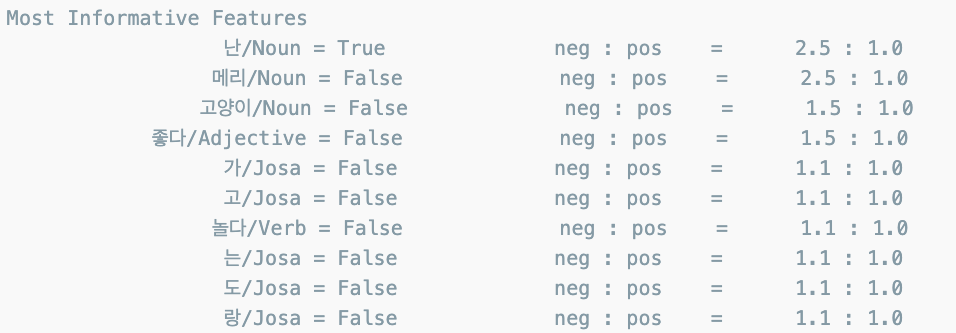
test_sentence = [('난 수업이 마치면 메리랑 놀거야')]
test_docs = pos_tagger.pos(test_sentence[0])
test_docs
test_sentence_features = {word : (word in tokens) for word in test_docs}
test_sentence_features
classifier.classify(test_sentence_features)
문장의 유사도
만약에 두 점 사이의 거리를 구하면
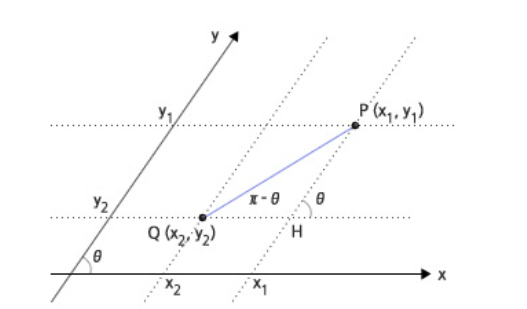
만약 문장을 점처럼 일종의 백터로 표현할 수 있다면 두 문장 사이의 거리를 구해서 유사한 문장을 찾을수 있다.
CountVectorizer : sklearn이 제공하는 문장을 벡터로 변환하는 함수
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=1)
contents = [
'상처받은 아이들은 너무 일찍 커버려',
'내가 상처받은 거 아는 사람 불편해',
'잘 사는 사람드은 좋은 사람 되기 쉬워',
'아무 일도 아니야 괜찮아'
]거리를 구하는 것이므로 지도할 내용이 없다.
형태소 분석 엔진은 Okt
from konlpy.tag import Okt
t = Okt()
contents_tokens = [t.morphs(row) for row in contents]
contents_tokens
형태소 분석된 결과를 다시 하나의 문장씩으로 합친다.
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
contents_for_vectorize.append(sentence)
contents_for_vectorize
백터 라이즈 수행
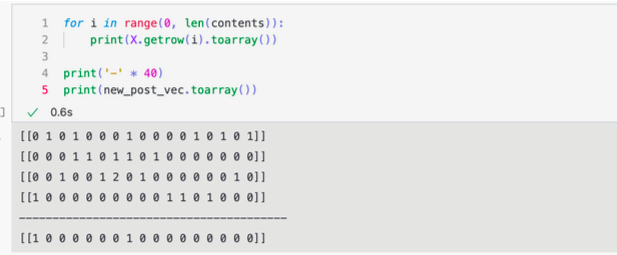
X = vectorizer.fit_transform(contents_for_vectorize)
X
4개 문장에 전체 말뭉치의 단어가 18개였다
num_samples, num_features = X.shape
num_samples, num_features 
확인
(vectorizer.get_feature_names_out())
X.toarray().transpose()
테스트용 문장
new_post = ['상처받기 싫어 괜찮아']
new_post_tokens = [t.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
new_post_for_vectorize.append(sentence)
new_post_for_vectorize
새로운 테스트용 문장을 만들고 백터로 표현하면 거리를 구할수 있다.
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()
단순히 기하학적 거리를 사용해보면
import scipy as sp
def dist_raw(v1, v2):
delta = v1 - v2
return sp.linalg.norm(delta.toarray())
dist = [dist_raw(each, new_post_vec) for each in X]
dist 
print('Best post is ', dist.index(min(dist)), ', dist = ', min(dist))
print('Test post is --> ', new_post)
print('Best dist post is -->', contents[dist.index(min(dist))])
유사도 - 벡터 사이의 거리
결국 관건은 벡터로 잘 만드느것과 만들어진 벡터 사이의 거리를 잘 계산하는 것이다.
TF - IDF
- 한 문서에서 많이 등장한 단어에 가중치 (Term Freq.)를 또한 한편으론 전체 문서에서 많이 나타나는 단어는 중요하지 않게 (Inverse Document Freq) 나타나는 개념.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=1, decode_error='ignore')
X = vectorizer.fit_transform(contents_for_vectorize)
X
num_samples, num_features = X.shape
num_samples, num_features 
X.toarray().transpose()
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()
def dist_norm(v1, v2):
v1_normalized = v1 / sp.linalg.norm(v1.toarray())
v2_normalized = v2 / sp.linalg.norm(v2.toarray())
delta = v1_normalized - v2_normalized
return sp.linalg.norm(delta.toarray())
dist = [dist_raw(each, new_post_vec) for each in X]
dist 
네이버 지식인 검색 결과에서 유사한 문장 찾기
예전 함수 가져오기
import urllib.request
import json
import datetime
def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = '/' + api_node + '.json'
param_query = '?query=' + urllib.parse.quote(search_text)
param_start = '&start=' + str(start_num)
param_disp = '&display=' + str(disp_num)
return base + node + param_query + param_start + param_disp
def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
print('[%s] Url Request Success'% datetime.datetime.now())
return json.loads(response.read().decode('utf-8'))문장 수집
client_id = 'g*'
client_secret = 'O*'
url = gen_search_url('kin','파이썬',1,100)
one_result = get_result_onpage(url)
one_result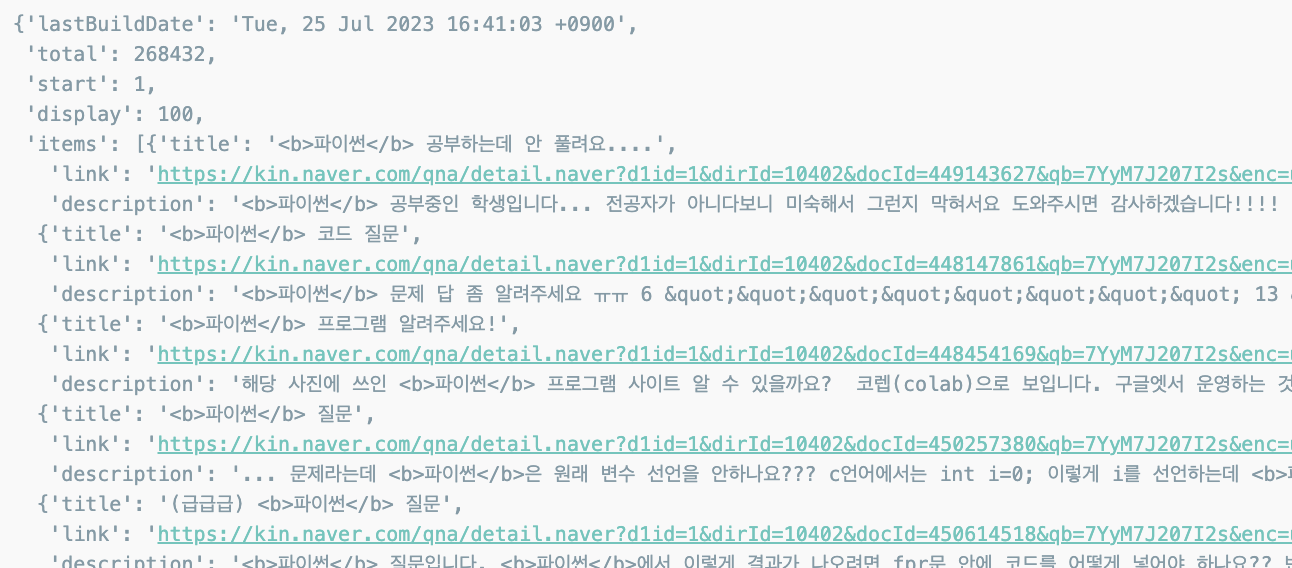
one_result['items'][0]['description']
태그 제거기 호출
def delete_tag(input_str):
input_str = input_str.replace('<b>','')
input_str = input_str.replace('</b>','')
return input_str
def get_description(pages):
contents = []
for sentences in pages['items']:
contents.append(delete_tag(sentences['description']))
return contents컨텐츠를 리스트로 변환
contents = get_description(one_result)
contents
형태소 분석
from sklearn.feature_extraction.text import CountVectorizer
from konlpy.tag import Okt
t = Okt()
vectorizer = CountVectorizer(min_df=1)
contents_tokens = [t.morphs(row) for row in contents]
contents_tokens
len(contents_tokens)
vectorize 후 다시 합치기
contents_for_vectorize = []
for content in contents_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
contents_for_vectorize.append(sentence)
contents_for_vectorize
결과
X = vectorizer.fit_transform(contents_for_vectorize)
X
num_samples, num_features = X.shape
num_samples, num_features 
유사도 측정할 테스트 문장
new_post = ['파이썬을 독학하려는데 좋은 책 있나요']
new_post_tokens = [t.morphs(row) for row in new_post]
new_post_for_vectorize = []
for content in new_post_tokens:
sentence = ''
for word in content:
sentence = sentence + ' ' + word
new_post_for_vectorize.append(sentence)
new_post_for_vectorize
vectorize
new_post_vec = vectorizer.transform(new_post_for_vectorize)
new_post_vec.toarray()
유클리드 거리
dist = [dist_raw(each, new_post_vec) for each in X]
dist 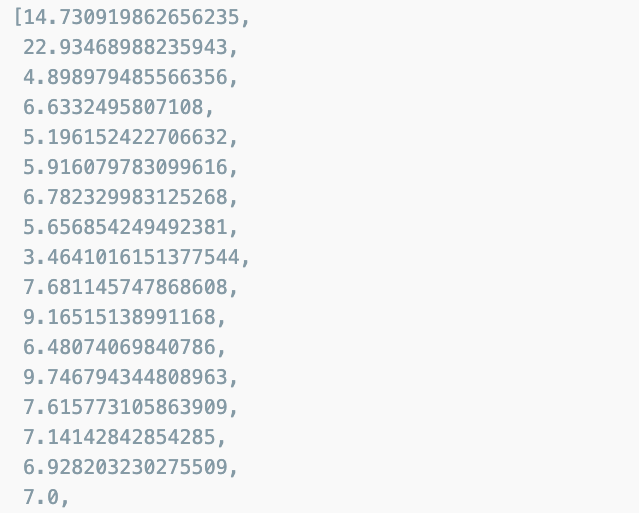
결과
min(dist)
contents[dist.index(min(dist))]
