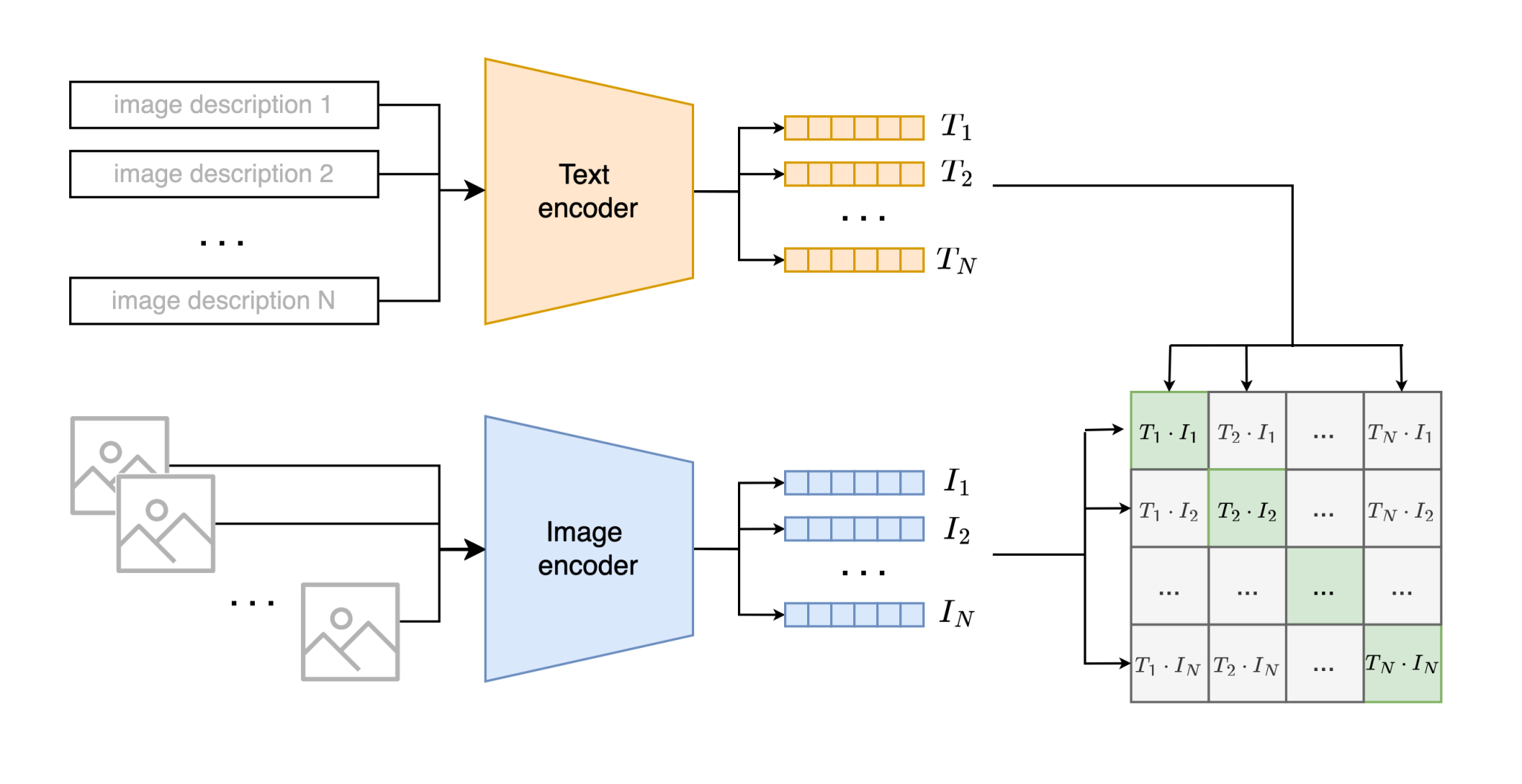
출처: https://www.pareto.si/blog/computer-vision-with-clip/
💡 작성 계기
최근 A Survey on Multimodal Large Language Models 논문 리뷰 후 CLIP 모델을 활용하여 이미지-텍스트 데이터 필터링 실습을 해보았다. 실습 후 CLIP 모델의 작동 원리와 Contrastive Learning을 직접 구현한 코드를 확인해보고 싶어 GitHub에 올라온 CLIP 모델의 코드를 살펴보았다.
🤔 CLIP이란?
CLIP(Contrastive Language–Image Pre-training)은 OpenAI에서 개발한 모델로 어떤 이미지와 텍스트가 서로 의미적으로 유사한지를 판별해주는 모델이다.
👩💻 분석 코드
- 코드는 OpenAI에서 GitHub에 공개한 자료를 살펴보았다.
- CLIP 폴더의 model.py를 한번 살펴보도록 하겠다.
출처: https://github.com/openai/CLIP/tree/main
🤖 model.py
CLIP 모델의 핵심 아키텍처와 각 아키텍처를 연결한 코드가 담겨있다.
- Image encoder
- Text encoder
- encoder의 출력을 CLIP 차원으로 projection
- Cosine 유사도 계산
- 학습된 가중치 불러오기
🔷Class CLIP
- 전체 CLIP 모델을 대표하는 최상위 Class이며, 이미지 인코더와 텍스트 인코더를 포함하여 두 모달리티를 통합하는 역할을 수행한다.
🔻 파라미터 입력
class CLIP(nn.Module):
def __init__(self,
# CLIP 차원
embed_dim: int,
# vision encoder 파라미터
image_resolution: int,
# 입력 이미지 해상도(가로 길이)
vision_layers: Union[Tuple[int, int, int, int], int],
# 이미지 인코더 레이어 수/구조
vision_width: int,
# 이미지 인코더의 채널
vision_patch_size: int,
# Vision Transformer 사용 시 패치 크기
# text encoder 파라미터
context_length: int,
# 텍스트 최대 시퀀스 길이
vocab_size: int,
# 어휘 사전 크기
transformer_width: int,
# 텍스트 Transformer 임베딩 차원
transformer_heads: int,
# 텍스트 Transformer 어텐션 헤드 수
transformer_layers: int
# 텍스트 Transformer 레이어 수
): - 입력으로 CLIP 차원 수, text와 image encoder에 대한 파라미터를 입력받는 것을 확인해볼 수 있다.
- 참고로 Text encoder는 Transformer 모델이고 Image encoder는 ResNet과 Vision Transformer이다.
🔻 Encoder 결정
- 입력된 파라미터를 참고하여 CLIP 모델이 구체적으로 어떤 encoder를 사용할지 결정한다.
class CLIP(nn.Module):
def __init__(self,
# ...
if isinstance(vision_layers, (tuple, list)):
# 이미지 인코더(self.visual)를 초기화하는 역할을 하며,
# vision_layers 인자의 데이터 type에 따라
# ModifiedResNet과 VisionTransformer 중 하나를 동적으로 선택하여 생성
# 튜플/리스트이면 ModifiedResNet, int이면 VisionTransformer
vision_heads = vision_width * 32 // 64
# ModifiedResNet 생성
self.visual = ModifiedResNet(
layers=vision_layers,
output_dim=embed_dim,
heads=vision_heads,
# 마지막 AttentionPool2d에서 사용되는 head의 수
input_resolution=image_resolution,
width=vision_width
)
else:
# Vision Transformer 생성
vision_heads = vision_width // 64
self.visual = VisionTransformer(
input_resolution=image_resolution,
patch_size=vision_patch_size,
width=vision_width,
layers=vision_layers,
heads=vision_heads,
output_dim=embed_dim
)
# Text encoder는 Transformer 고정
self.transformer = Transformer(
width=transformer_width,
layers=transformer_layers,
heads=transformer_heads,
attn_mask=self.build_attention_mask()
)- init에서 입력된 파라미터에 따라 Image encoder가 ResNet 또는 Vision Transformer로 정해진다.
- Text encoder는 Transformer 모델로 고정이다.
🔻 def encode_image
def encode_image(self, image):
return self.visual(image.type(self.dtype))
# 주어진 이미지를 CLIP 모델의 이미지 인코더를 통해 처리하여,
# 해당 이미지의 고차원 임베딩 벡터를 생성하는 역할
# 이미지 인코더(self.visual)로 이미지 임베딩
# [N, embed_dim] 형태- 선정된 Image encoder를 사용하여 입력 이미지를 임베딩한다.
- ResNet과 Vision Transformer 모두 CLIP 임베딩 차원의 특징을 추출하여, 추가적인 임베딩은 진행하지 않는다.
🔻 def encode_text
def encode_text(self, text):
x = self.token_embedding(text).type(self.dtype)
# 토큰 ID를 임베딩 벡터로 변환
# text: [batch_size, context_length] (토큰 ID)
# 각 context_length에 맞는 토큰 ID(정수)를 d_model로 mapping
# 출력: [batch_size, context_length, d_model]
x = x + self.positional_embedding.type(self.dtype)
# 위치 임베딩 추가
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
# Transformer 블록 통과 (텍스트 특징 학습)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_final(x).type(self.dtype)
# 최종 레이어 정규화
# 출력: [batch_size, context_length, d_model]
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
# EOT (End of Text) 토큰 임베딩 추출 및 CLIP 공간 임베딩
# EOT: 시퀀스 전체의 맥락을 학습
# EOT (End of Text) 토큰에 어휘 사전 내에서 가장 큰 정수 ID가 할당
# text.argmax(dim=-1)는 각 텍스트 시퀀스([batch_size, context_length])의
# EOT 토큰의 위치(인덱스)를 찾아줍니다.
# [batch_size, transformer_width] -> 각 batch의 EOT 벡터를 가져왔다.
# self.text_projection: CLIP 임베딩 공간으로 projection
# [batch_size, embed_dim]
return x- Transformer는 encoder를 거친 후 맥락이 반영된 token을 출력한다.
- CLIP에서는 이 중 [EOS] token을 해당 문장 전체의 의미를 담은 token으로 간주하여, 각 Batch에서 [EOS] token만 추출하여 CLIP 공간으로 임베딩한다.
🔻 def forward
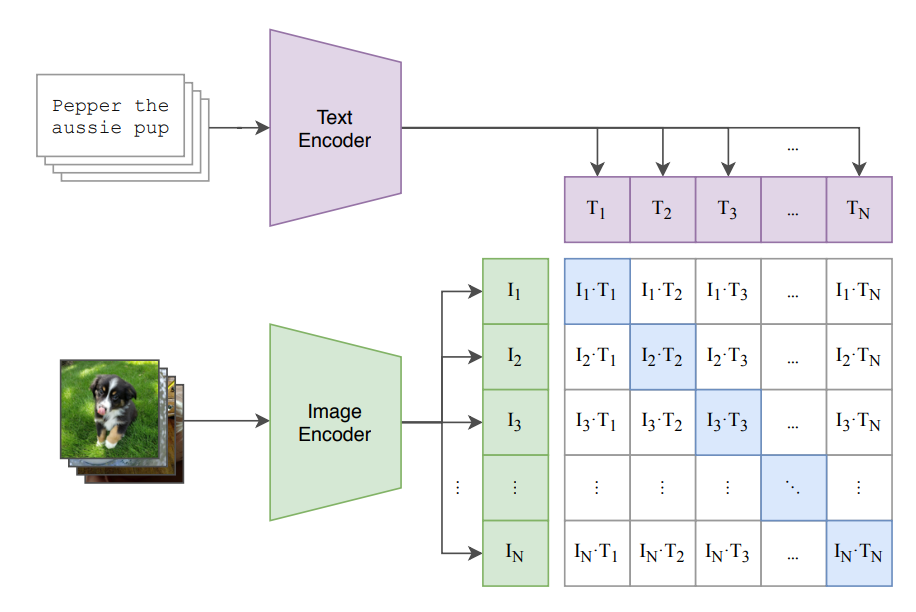
출처: https://arxiv.org/pdf/2103.00020
- encode_image와 encode_text를 호출하여 이미지와 텍스트 임베딩을 얻은 후, 이들 간의 코사인 유사도를 계산
def forward(self, image, text):
image_features = self.encode_image(image)
# 이미지 인코더가 추출한 임베딩 [batch_size, embed_dim]
text_features = self.encode_text(text)
# 텍스트 인코더가 추출한 임베딩 [batch_size, embed_dim]
# 이미지 특징 벡터와 텍스트 특징 벡터를
# 단위 길이(unit length)로 정규화하는 역할
# dim = 1이므로 embed_dim의 크기 조절
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
# 유사도값을 스케일링하는 역할
logits_per_image = logit_scale * image_features @ text_features.t()
# 이미지 특징과 텍스트 특징 간의 모든 가능한 쌍에 대한 코사인 유사도를 계산하고,
# 이를 logit_scale로 스케일링하여 로짓 행렬을 생성
# 결과 형태: [N, D] @ [D, N] = [N, N]
# (i, j)는 image_features[i] (i번째 이미지)와
# text_features[j] (j번째 텍스트) 간의 유사도
logits_per_text = logits_per_image.t()
return logits_per_image, logits_per_text
# 유사도를 matrix형태로 출력
🔷 Class ModifiedResNet
- ResNet 아키텍처를 CLIP의 목적에 맞게 수정한 버전이다.
- 최종 풀링 레이어로 AttentionPool2d를 사용
- 어텐션 메커니즘을 통해 최종 임베딩 벡터로 집약하는 역할
class ModifiedResNet(nn.Module):
def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
super().__init__()
# ...
# the 3-layer stem
self.conv1 = nn.Conv2d(3, width // 2, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(width // 2)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(width // 2, width // 2, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(width // 2)
self.relu2 = nn.ReLU(inplace=True)
self.conv3 = nn.Conv2d(width // 2, width, kernel_size=3, padding=1, bias=False)
self.bn3 = nn.BatchNorm2d(width)
self.relu3 = nn.ReLU(inplace=True)
self.avgpool = nn.AvgPool2d(2)
# residual layers
self._inplanes = width
self.layer1 = self._make_layer(width, layers[0])
# 첫 번째 ResNet laeyr를 생성
# _make_layer: width 채널을 가진 layers[0]개의
# Bottleneck 블록으로 구성된 시퀀스 생성
# 잔차연결은 각 bottle마다 연결되어 있다.
self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
# 최종 Attention Pooling
embed_dim = width * 32
self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
# ResNet의 최종 출력은 attention pooling을 활용하여 전체 이미지 요약
# [N, embed_dim] -> CLIP 차원 임베딩🔷 Class VisionTransformer
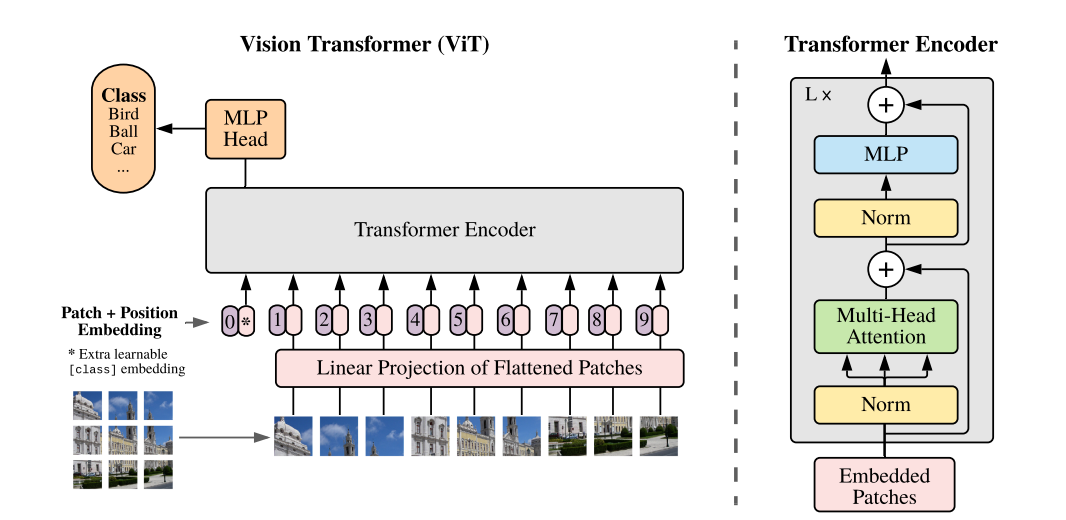
출처: https://arxiv.org/pdf/2010.11929
- VisionTransformer를 활용하여 이미지 임베딩 생성.
- 이미지 전체를 대표하는 [CLS] token 활용.
class VisionTransformer(nn.Module):
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
super().__init__()
# ...
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
# 이미지를 패치 임베딩으로 변환하는 컨볼루션 레이어
# ViT의 "패치 임베딩" 역할
# out_channels: VisionTransformer의 임베딩 차원
scale = width ** -0.5
self.class_embedding = nn.Parameter(scale * torch.randn(width))
# nn.Parameter: 이 텐서가 모델의 학습 가능한 파라미터임을 PyTorch에 등록
# 이미지 전체를 대표하는 최종 임베딩 벡터의 역할을 수행
# [CLS] 토큰
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
# 각 패치와 [CLS] 토큰의 위치 임베딩 생성
self.ln_pre = LayerNorm(width)
# 정규화 모듈
self.transformer = Transformer(width, layers, heads)
# Transformer 클래스의 인스턴스를 생성
# 패치 임베딩 시퀀스를 입력받아 여러 층의 셀프-어텐션과
# MLP 연산을 통해 심층적인 시각적 특징을 학습하고 추출
self.ln_post = LayerNorm(width)
# Transformer 블록을 통과한 후에 적용되는 최종 레이어 정규화 모듈을 정의
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
# CLIP 차원으로 임베딩
# [N, embed_dim]
🔷 Class Transformer
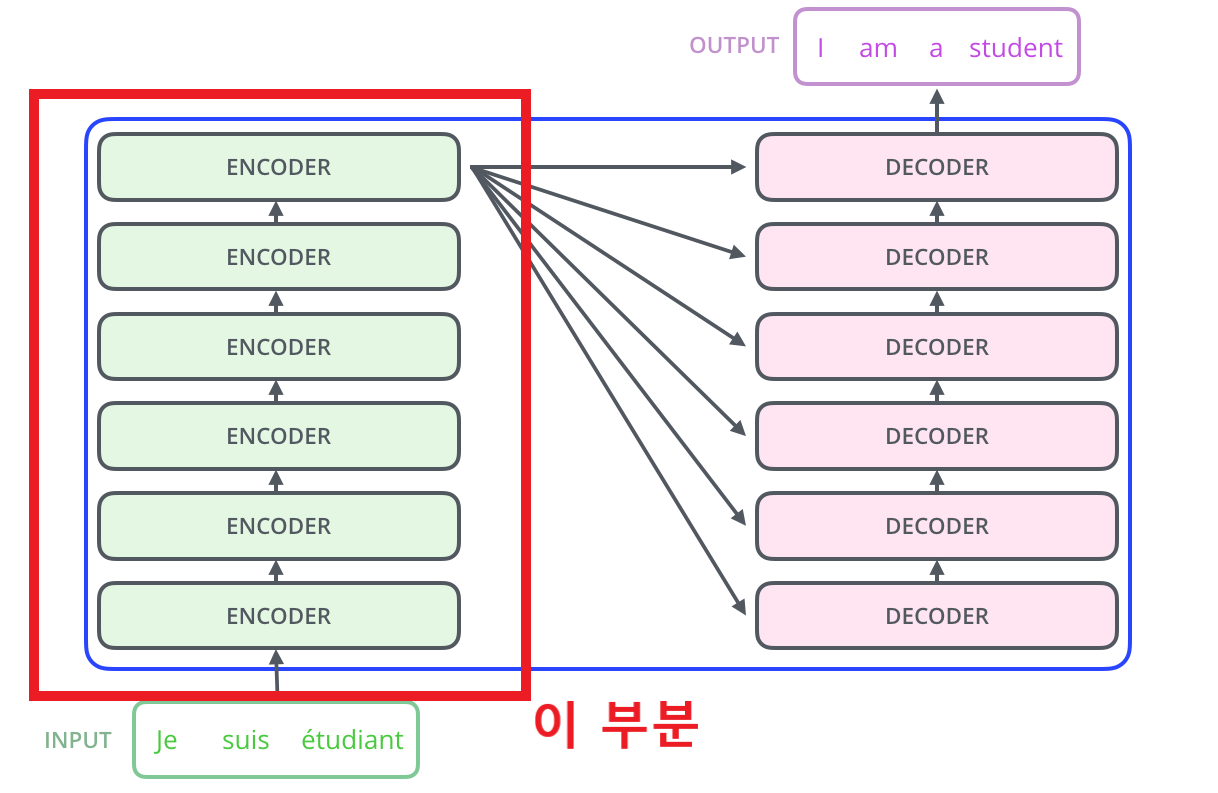
출처: https://jalammar.github.io/illustrated-transformer/
- Transformer 모델을 활용하여 Text Encoder 구현
- ResidualAttentionBlock의 개수에 맞게 층을 쌓는다.
class Transformer(nn.Module):
def __init__(self, width: int, layers: int, heads: int,
attn_mask: torch.Tensor = None):
super().__init__()
self.width = width
# width: Transformer 모델의 임베딩 차원
self.layers = layers
# Transformer에 포함될 ResidualAttentionBlock의 총 개수
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width,
heads, attn_mask) for _ in range(layers)])
# layers 수만큼의 ResidualAttentionBlock 인스턴스들을 생성하고,
# 이를 nn.Sequential 컨테이너로 묶어 self.resblocks에 할당
def forward(self, x: torch.Tensor):
return self.resblocks(x)
# 출력: [시퀀스_길이, 배치_크기, 임베딩_차원]🔷 class ResidualAttentionBlock
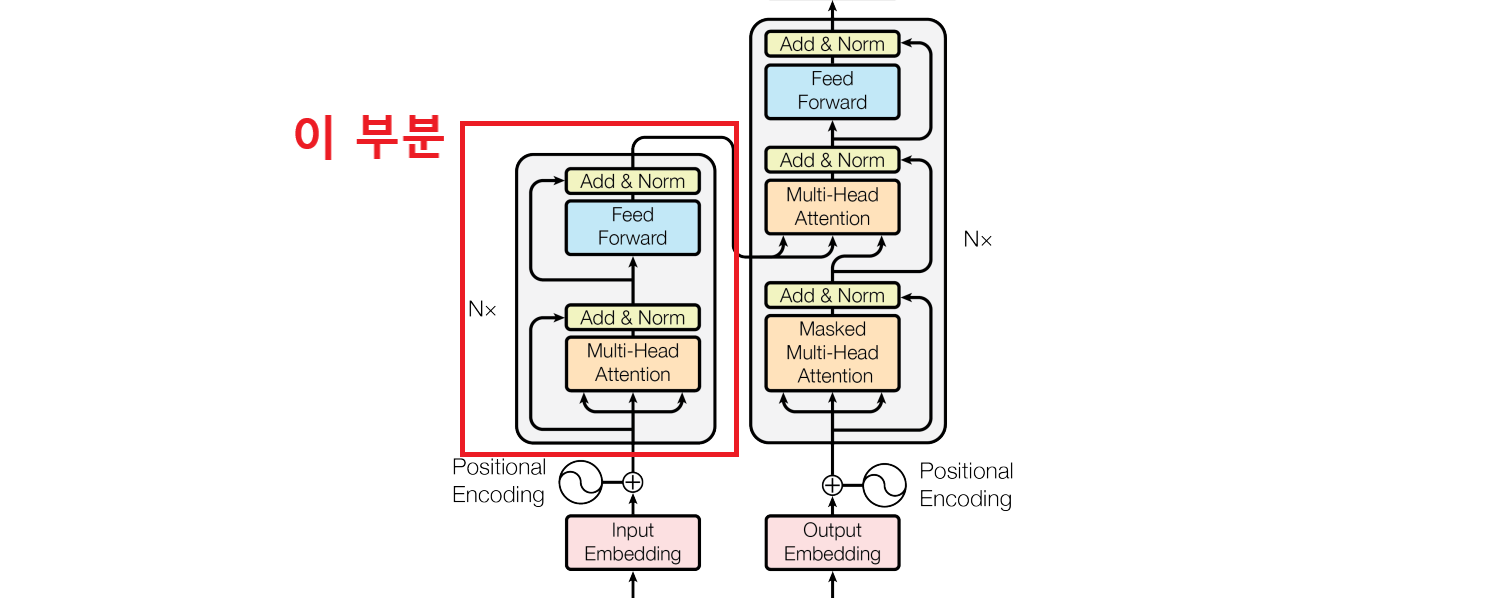
출처: https://arxiv.org/pdf/1706.03762
- Transformer를 구성하는 핵심 단위
- 셀프-어텐션 메커니즘과 피드포워드 신경망(MLP)을 결합하며, 잔차 연결과 레이어 정규화가 적용
class ResidualAttentionBlock(nn.Module):
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
super().__init__()
self.attn = nn.MultiheadAttention(d_model, n_head)
# 멀티헤드 어텐션(Multihead Attention) 모듈을 정의
# d_model: 모델의 임베딩 차원 (입력/출력 차원)
# n_head: 어텐션 헤드의 개수
self.ln_1 = LayerNorm(d_model)
# 첫 번째 레이어 정규화(Layer Normalization) 모듈을 정의
self.mlp = nn.Sequential(OrderedDict([
# 피드포워드 신경망
("c_fc", nn.Linear(d_model, d_model * 4)),
# 첫 번째 선형 변환 레이어
("gelu", QuickGELU()),
# QuickGELU 활성화 함수
("c_proj", nn.Linear(d_model * 4, d_model))
# 두 번째 선형 변환 레이어입니다. 확장된 d_model * 4 차원을
# 다시 원래의 d_model 차원으로 투영(projection)하여 복원
]))
self.ln_2 = LayerNorm(d_model)
# 두 번째 레이어 정규화 모듈
self.attn_mask = attn_mask
# 어텐션 마스크를 저장하는 변수
# 특정 위치들이 다른 위치들에 "어텐션"하지 못하도록 마스킹(masking)하는 데 사용
# 인과적 마스크(causal mask)를 사용하여 모델이 미래의 토큰을 보지 못하도록 강제
def forward(self, x: torch.Tensor):
x = x + self.attention(self.ln_1(x))
# 정규화 후 self-attention 수행 그리고 잔차 연결
x = x + self.mlp(self.ln_2(x))
# 정규화 후 self-attention 수행 그리고 잔차연결
return x
# 출력: [시퀀스_길이, 배치_크기, 임베딩_차원]
🔷 def build_model
- 주어진 state_dict (미리 학습된 모델의 가중치 딕셔너리)로부터 CLIP 모델 구성한다.
- 모델 인스턴스에 load_state_dict 함수를 통해 가중치를 로드한다.
- 모델을 평가 모드로 설정하여 반환한다.
def build_model(state_dict: dict):
# (생략: 이미지 인코더 타입 및 파라미터 추론)
# (생략: 텍스트 인코더 및 공통 파라미터 추론)
# 추론된 모든 파라미터로 CLIP 모델 인스턴스 생성
model = CLIP(
embed_dim,
image_resolution, vision_layers, vision_width, vision_patch_size,
context_length, vocab_size, transformer_width, transformer_heads,
transformer_layers)
# 추론된 모든 파라미터로 CLIP 모델 인스턴스 생성
# 모델의 뼈대 완성, 가중치만 채워넣으면 된다.
for key in ["input_resolution", "context_length", "vocab_size"]:
if key in state_dict:
del state_dict[key]
# state_dict에서 불필요하거나 모델 파라미터가 아닌 키들을 제거
# PyTorch의 model.load_state_dict(state_dict) 메서드는
# 기본적으로 로드하려는 state_dict의 키와 현재 모델의
# state_dict 키가 정확히 일치하기를 기대하기 때문
convert_weights(model)
# 모델의 일부 파라미터를 fp16으로 변환
model.load_state_dict(state_dict)
# 정리된 state_dict의 가중치를 모델에 로드
# 비어있는 model에 실제 학습된 가중치를 주입하는 핵심 단계
return model.eval()
# 모델을 평가 모드로 설정하고 반환
✨ Loss function
🔍 Embedding Vector
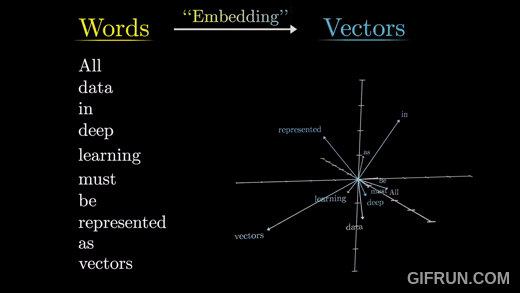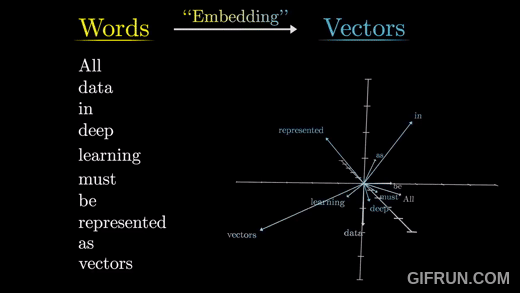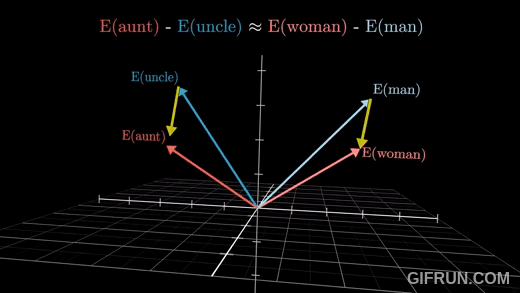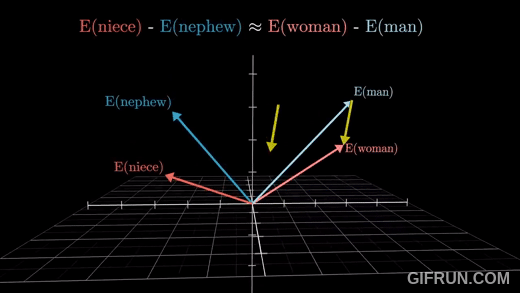

출처: https://www.youtube.com/watch?v=eMlx5fFNoYc&t=887s
📐 코사인 유사도
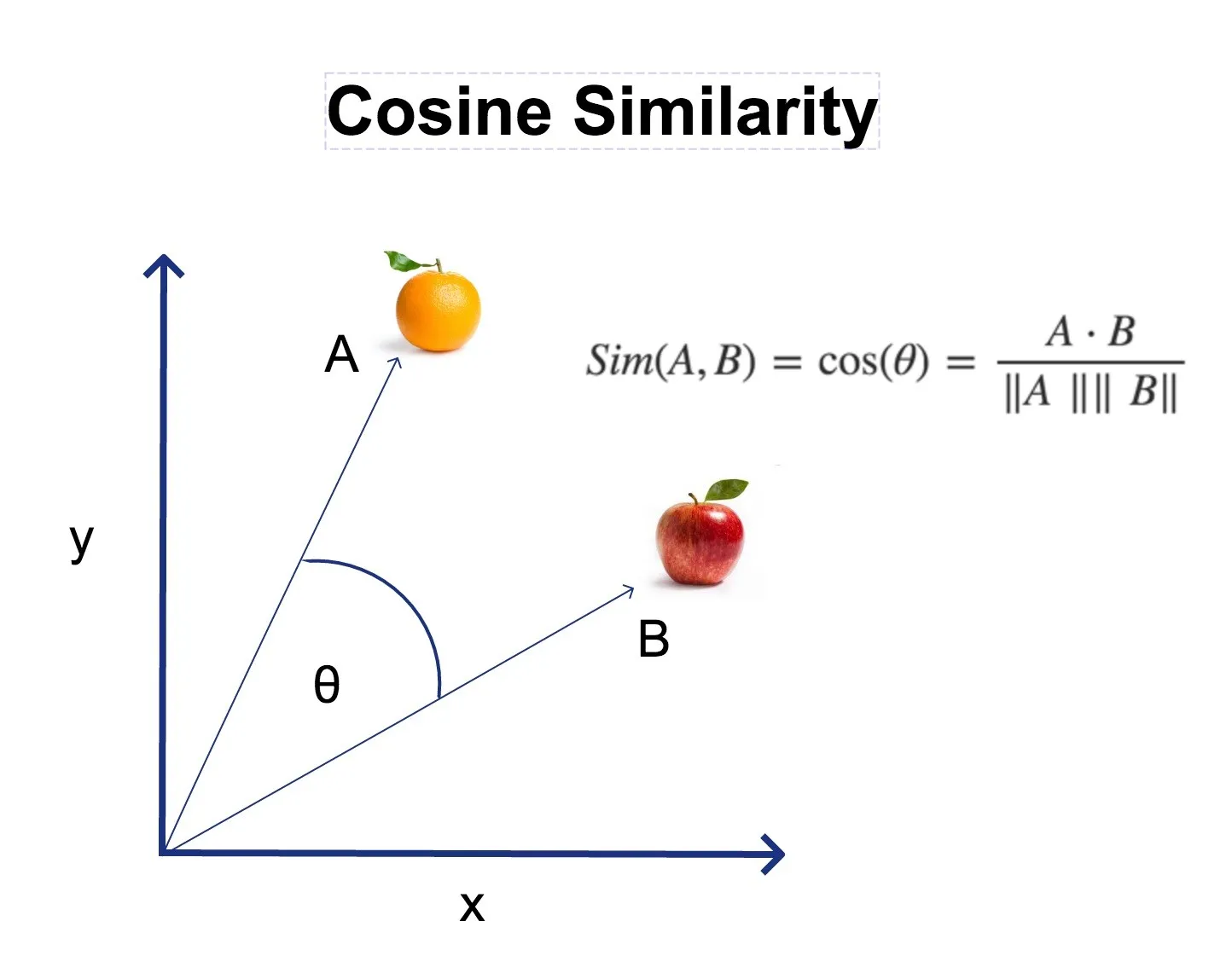
출처: https://thenewth.com/tag/clip/
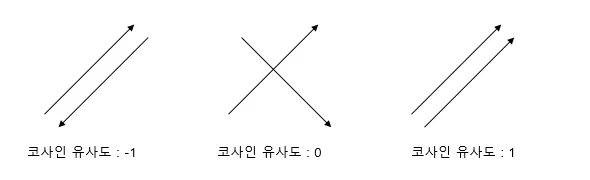
출처: https://wikidocs.net/24603
✍ Contrastive Loss
import torch.nn.functional as F
class CLIPLoss(nn.Module):
def forward(self, image_features, text_features):
logits = image_features @ text_features.T
# 이미지와 텍스트 간 내적을 통해 유사도 계산
# Cosine Similarity - 코사인 유사도
labels = torch.arange(len(logits)).to(logits.device)
# CrossEntropyLoss 적용 (이미지-텍스트 정답 매칭)
loss = (F.cross_entropy(logits, labels)
+ F.cross_entropy(logits.T, labels)) / 2
return loss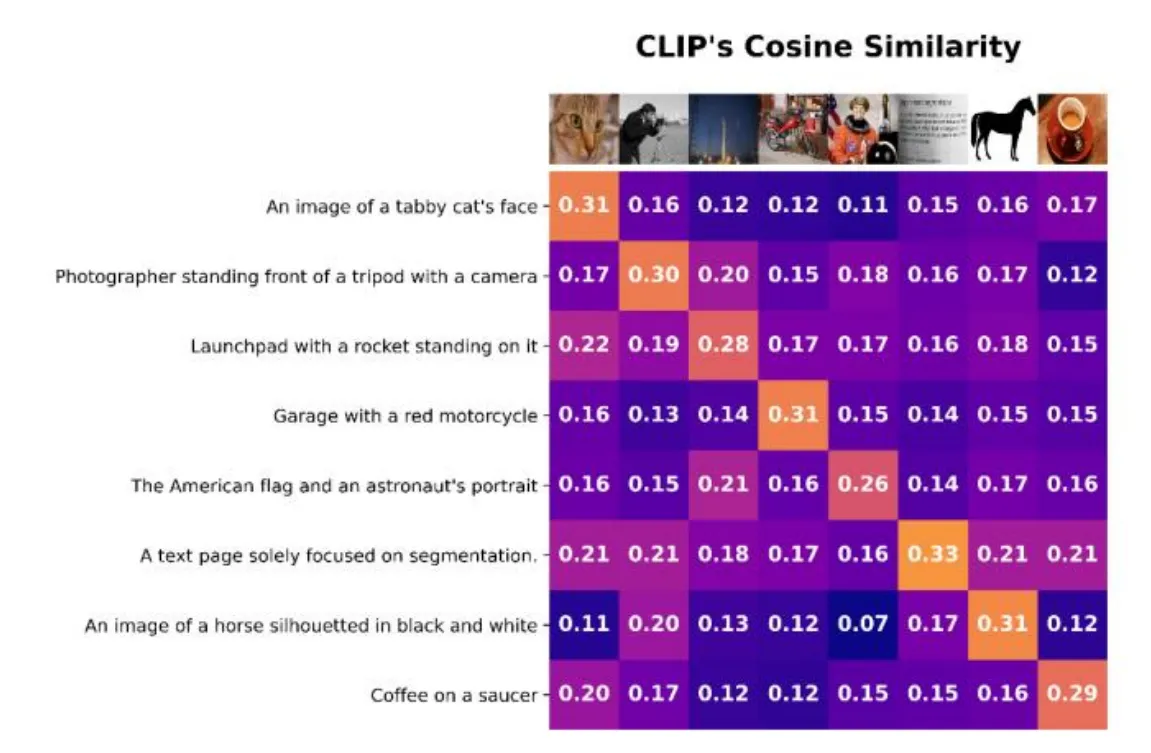
출처: https://www.researchgate.net/figure/sualization-of-Sigmoid-approach-using-CLIP-cosine-similarity-matrix-as-a-key-input-The_fig2_374991410
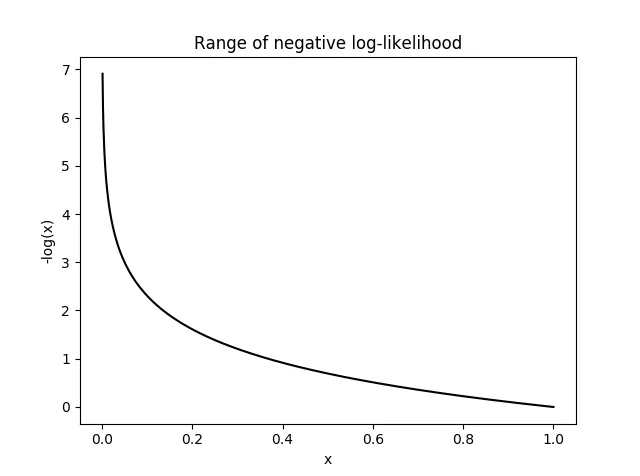
출처: https://gaussian37.github.io/dl-concept-nll_loss/
😂 내 생각
CLIP 모델은 코드가 짧음에도 불구하고 velog에 담아내기 쉽지 않았다. 핵심적인 코드보다는 모델 자체를 구현하기 위해 지금까지 정립해온 코드들이 너무 많아서 그런 것 같다.
앞으로 모델의 구현 코드를 계속 velog에 작성한다면, 핵심적인 부분만 잘 정리해둬야할 것 같다. 코드 velog는 당분간은 고생 좀 해야할 것 같다.

I'm curious about AI