[Deep Reinforcement Learning] 16강 Deep Reinforcement Learning
[Deep Reinforcement Learning]

👨🏫학습목표
오늘은 지금까지 배웠던 Reinforcement Learning과 Deep Reinforcement Learning의 차이 그리고 각 방식의 역사에 대해 배워볼 예정이다.
👨🎓강의영상: https://www.youtube.com/watch?v=TL1RavBMag8&list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC&index=16
1️⃣ RL vs DRL

🔷 Reinforcement Learning (RL)
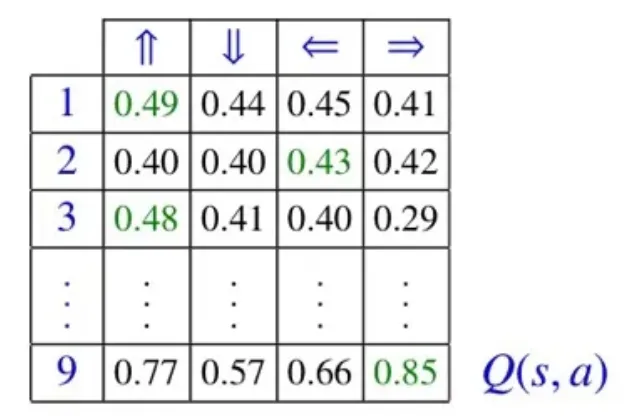
🔻 Tabular updating method
-
값을 table로 기록한다.
-
값을 Bellman equation을 통해 반복적으로 업데이트한다.
-
대표적인 방법: Monte Carlo, Sarsa, Q-learning
-
State-action의 크기가 커질수록 차지하는 memory가 많아진다.
🔷 Deep Reinforcement Learning (DRL)
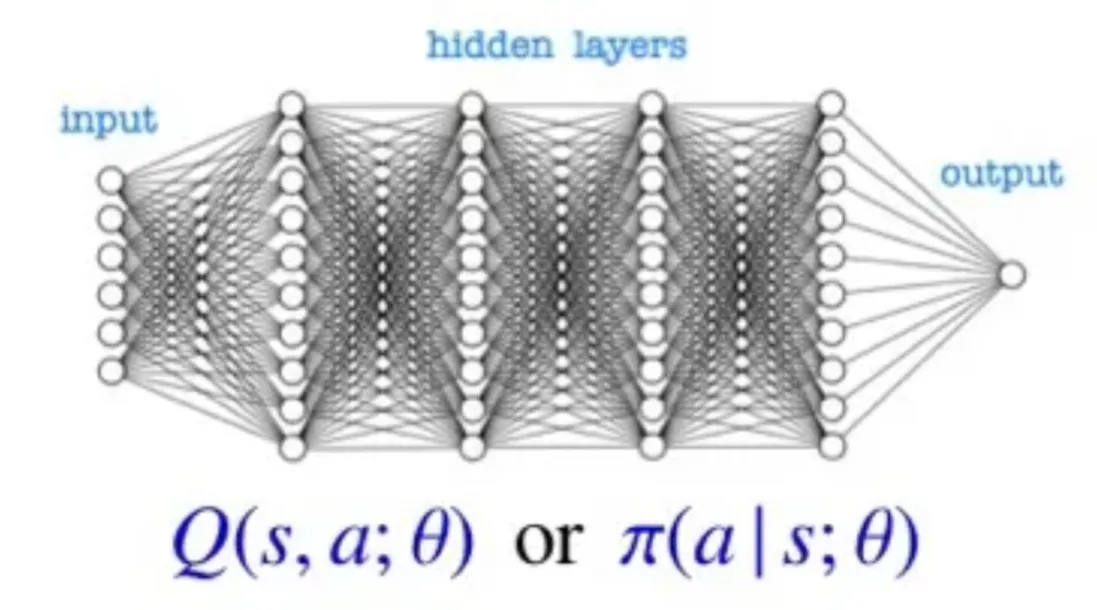
🔻 Function approximation method
-
State-action value function이나 policy를 신경망을 통해 근사한다.
-
함수를 구하기 때문에 함수값 를 모두 기록할 필요가 없다.
-
Deep Q-Network (DQN): 를 출력한다.
-
Policy Gradient (REINFORCE): policy 를 근사한다.
-
Actor-Critic (A3C): 와 를 모두 근사한다.
-
State-action space가 훨씬 커도 적용 가능하다.
-
Data가 Continuous한 경우에도 적용할 수 있다.
-
Label 없이 학습을 한다.
2️⃣ Why DRL?

🔷 Deep Reinforcement Learning
-
빅데이터, 신경망 기술의 발달, 연산 능력 향상으로 DRL이 게임, 로보틱스, 자율주행차 등 다양한 분야에서 활용되고 있다.
-
로보틱스에서는 state space가 굉장히 크다. 이를 DL을 통해 low-dimension으로 조정할 수 있다.
🔻 대표적인 모델
-
DQN: 아타리 게임에서 사람의 실력을 뛰어넘었다.

출처: https://huggingface.co/learn/deep-rl-course/unit3/hands-on
-
AlphaGo: CNN + RL을 통해 바둑에서 뛰어난 성능을 보였다.

출처: https://intellipaat.com/blog/power-of-deep-learning-alphago-vs-lee-sedol-case-study/
3️⃣ Milestones in DRL
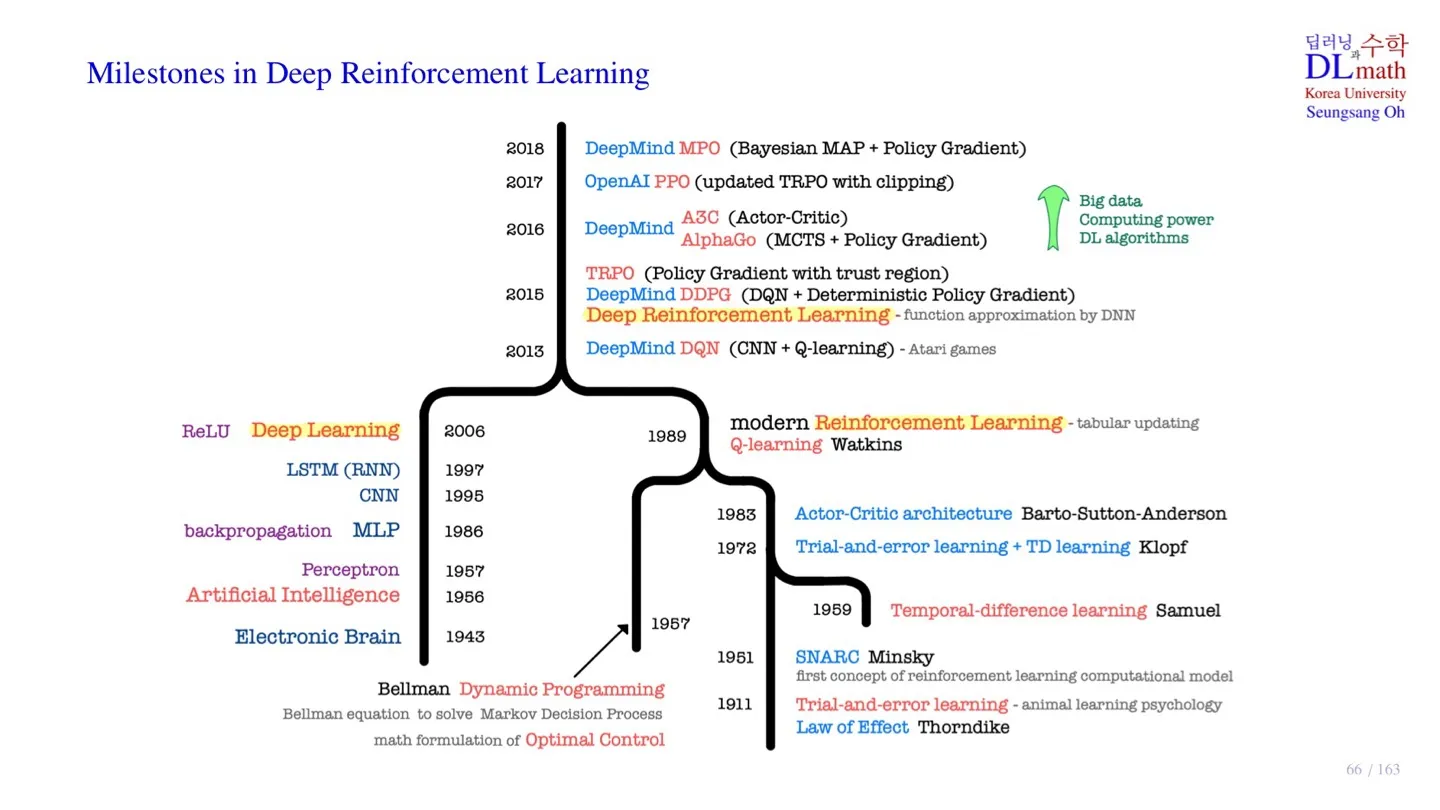
🔻 1. Trial-and-error learning
-
시행착오 학습법으로 동물의 학습 행동에 대한 심리학 연구를 통해 시작되었다.
-
Law of Effect : 동물이 어떤 행동을 한 후 얻은 자극을 토대로 행동 결정을 한다는 이론이다.
-
SNARC : 강화학습 개념을 처음으로 컴퓨터 모델로 구현한 것
🔻 2. Dynamic Programming
-
Optimal Control (최적 제어)
-
Markov Decision Process
-
Bellman equation
🔻 3. Q-learning
-
Trial-and-error learning과 Dynamic Programming이 합쳐져 탄생하였다.
-
finite state space
-
finite action space
🔻 4. Deep Learning
-
Programming 방식으로 시작하였다.
-
이후 Perceptron이 등장하면서 Learning 방식이 등장하였다.
-
Backpropagation
-
CNN, LSTM
🔷 Deep Reinforcement Learning
-
Deep Learning과 Reinforcement 학문이 합쳐져 등장하였다.
-
DQN의 등장으로 시작되었다.
-
Large or continuous state space
-
TRPO, DDPG : Continuous action space로 확장되었다.
-
PPO : TRPO를 더욱 쉽게 업데이트 할 수 있도록 개선하였다.
4️⃣ 정리
🔷 16강에서 배운 내용은 아래와 같다.
- RL과 DRL의 차이를 살펴보았다.
- Deep Reinforcement Learning의 장점을 살펴보았다.
- Deep Reinforcement Learning의 발전과정을 살펴보았다.
